 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multi-turn Medical Diagnosis: Hold, Lure, and Self-Correction
Apr 06, 2026Large language models (LLMs) achieve high accuracy in medical diagnosis when all clinical information is provided in a single turn, yet how they behave under multi-turn evidence accumulation closer to real clinical reasoning remains unexplored. We introduce MINT (Medical Incremental N-Turn Benchmark), a high-fidelity, multi-turn medical diagnosis benchmark comprising 1,035 cases with clinically labeled evidence shards, controlled turn granularity, and information-preserving decomposition. Through systematic evaluation of 11 LLMs on MINT, we uncover three persistent behavioral patterns that significantly impact diagnostic decisions: (1) intent to answer, models rush to answer before sufficient evidence has been observed, with over 55% of answers committed within the first two turns; (2) self-correction, incorrect-to-correct answer revisions occur at up to 10.6 times the rate of correct-to-incorrect flips, revealing a latent capacity for self-correction that premature commitment forecloses; and (3) strong lures, clinically salient information such as laboratory results trigger premature answering even when models are explicitly instructed to wait. We translate these findings into clinically actionable guidance: deferring the diagnostic question to later turns reduces premature answering and improves accuracy at the first point of commitment by up to 62.6%, while reserving salient clinical evidence for later turns prevents a catastrophic accuracy drop of up to 23.3% caused by premature commitment. Our work provides both a controlled evaluation framework and concrete recommendations for improving the reliability of LLMs in multi-turn medical diagnosis.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
Current Agents Fail to Leverage World Model as Tool for Foresight
Jan 08, 2026Agents built on vision-language models increasingly face tasks that demand anticipating future states rather than relying on short-horizon reasoning. Generative world models offer a promising remedy: agents could use them as external simulators to foresee outcomes before acting. This paper empirically examines whether current agents can leverage such world models as tools to enhance their cognition. Across diverse agentic and visual question answering tasks, we observe that some agents rarely invoke simulation (fewer than 1%), frequently misuse predicted rollouts (approximately 15%), and often exhibit inconsistent or even degraded performance (up to 5%) when simulation is available or enforced. Attribution analysis further indicates that the primary bottleneck lies in the agents' capacity to decide when to simulate, how to interpret predicted outcomes, and how to integrate foresight into downstream reasoning. These findings underscore the need for mechanisms that foster calibrated, strategic interaction with world models, paving the way toward more reliable anticipatory cognition in future agent systems.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
ModelingAgent: Bridging LLMs and Mathematical Modeling for Real-World Challenges
May 21, 2025
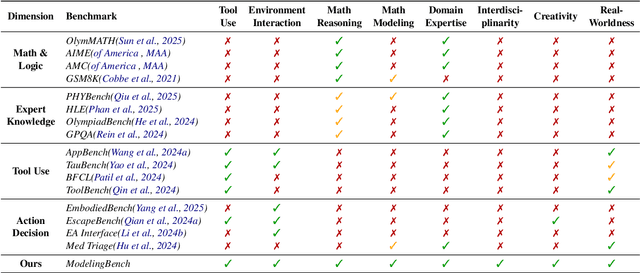
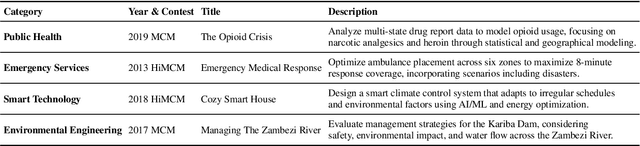
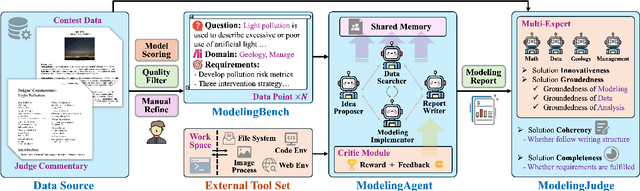
Recent progress in large language models (LLMs) has enabled substantial advances in solving mathematical problems. However, existing benchmarks often fail to reflect the complexity of real-world problems, which demand open-ended, interdisciplinary reasoning and integration of computational tools. To address this gap, we introduce ModelingBench, a novel benchmark featuring real-world-inspired, open-ended problems from math modeling competitions across diverse domains, ranging from urban traffic optimization to ecosystem resource planning. These tasks require translating natural language into formal mathematical formulations, applying appropriate tools, and producing structured, defensible reports. ModelingBench also supports multiple valid solutions, capturing the ambiguity and creativity of practical modeling. We also present ModelingAgent, a multi-agent framework that coordinates tool use, supports structured workflows, and enables iterative self-refinement to generate well-grounded, creative solutions. To evaluate outputs, we further propose ModelingJudge, an expert-in-the-loop system leveraging LLMs as domain-specialized judges assessing solutions from multiple expert perspectives. Empirical results show that ModelingAgent substantially outperforms strong baselines and often produces solutions indistinguishable from those of human experts. Together, our work provides a comprehensive framework for evaluating and advancing real-world problem-solving in open-ended, interdisciplinary modeling challenges.
TAMA: A Human-AI Collaborative Thematic Analysis Framework Using Multi-Agent LLMs for Clinical Interviews
Mar 26, 2025Thematic analysis (TA) is a widely used qualitative approach for uncovering latent meanings in unstructured text data. TA provides valuable insights in healthcare but is resource-intensive. Large Language Models (LLMs) have been introduced to perform TA, yet their applications in healthcare remain unexplored. Here, we propose TAMA: A Human-AI Collaborative Thematic Analysis framework using Multi-Agent LLMs for clinical interviews. We leverage the scalability and coherence of multi-agent systems through structured conversations between agents and coordinate the expertise of cardiac experts in TA. Using interview transcripts from parents of children with Anomalous Aortic Origin of a Coronary Artery (AAOCA), a rare congenital heart disease, we demonstrate that TAMA outperforms existing LLM-assisted TA approaches, achieving higher thematic hit rate, coverage, and distinctiveness. TAMA demonstrates strong potential for automated TA in clinical settings by leveraging multi-agent LLM systems with human-in-the-loop integration by enhancing quality while significantly reducing manual workload.
The Law of Knowledge Overshadowing: Towards Understanding, Predicting, and Preventing LLM Hallucination
Feb 22, 2025



Hallucination is a persistent challenge in large language models (LLMs), where even with rigorous quality control, models often generate distorted facts. This paradox, in which error generation continues despite high-quality training data, calls for a deeper understanding of the underlying LLM mechanisms. To address it, we propose a novel concept: knowledge overshadowing, where model's dominant knowledge can obscure less prominent knowledge during text generation, causing the model to fabricate inaccurate details. Building on this idea, we introduce a novel framework to quantify factual hallucinations by modeling knowledge overshadowing. Central to our approach is the log-linear law, which predicts that the rate of factual hallucination increases linearly with the logarithmic scale of (1) Knowledge Popularity, (2) Knowledge Length, and (3) Model Size. The law provides a means to preemptively quantify hallucinations, offering foresight into their occurrence even before model training or inference. Built on overshadowing effect, we propose a new decoding strategy CoDa, to mitigate hallucinations, which notably enhance model factuality on Overshadow (27.9%), MemoTrap (13.1%) and NQ-Swap (18.3%). Our findings not only deepen understandings of the underlying mechanisms behind hallucinations but also provide actionable insights for developing more predictable and controllable language models.
Internal Activation as the Polar Star for Steering Unsafe LLM Behavior
Feb 04, 2025



Large language models (LLMs) have demonstrated exceptional capabilities across a wide range of tasks but also pose significant risks due to their potential to generate harmful content. Although existing safety mechanisms can improve model safety, they often lead to overly cautious behavior and fail to fully utilize LLMs' internal cognitive processes. Drawing inspiration from cognitive science, where humans rely on reflective reasoning (System 2 thinking) to regulate language and behavior, we empirically demonstrate that LLMs also possess a similar capacity for internal assessment and regulation, which can be actively detected. Building on this insight, we introduce SafeSwitch, a framework that dynamically regulates unsafe outputs by monitoring and utilizing the model's internal states. Our empirical results show that SafeSwitch reduces harmful outputs by over 80% on safety benchmarks while maintaining strong utility. Compared to traditional safety alignment methods, SafeSwitch delivers more informative and context-aware refusals, demonstrates resilience to unseen queries, and achieves these benefits while only tuning less than 6% of the original parameters. These features make SafeSwitch a promising approach for implementing nuanced safety controls in LLMs.
EscapeBench: Pushing Language Models to Think Outside the Box
Dec 18, 2024Language model agents excel in long-session planning and reasoning, but existing benchmarks primarily focus on goal-oriented tasks with explicit objectives, neglecting creative adaptation in unfamiliar environments. To address this, we introduce EscapeBench, a benchmark suite of room escape game environments designed to challenge agents with creative reasoning, unconventional tool use, and iterative problem-solving to uncover implicit goals. Our results show that current LM models, despite employing working memory and Chain-of-Thought reasoning, achieve only 15% average progress without hints, highlighting their limitations in creativity. To bridge this gap, we propose EscapeAgent, a framework designed to enhance creative reasoning through Foresight (innovative tool use) and Reflection (identifying unsolved tasks). Experiments show that EscapeAgent can execute action chains over 1,000 steps while maintaining logical coherence. It navigates and completes games with up to 40% fewer steps and hints, performs robustly across varying difficulty levels, and achieves higher action success rates with more efficient and innovative puzzle-solving strategies. All the data and codes are released.
Integrative Decoding: Improve Factuality via Implicit Self-consistency
Oct 02, 2024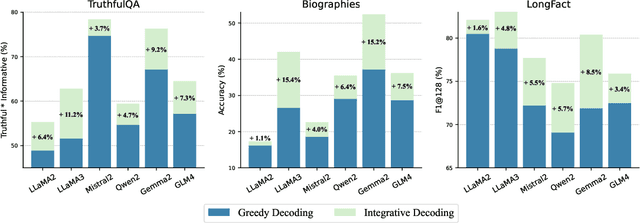
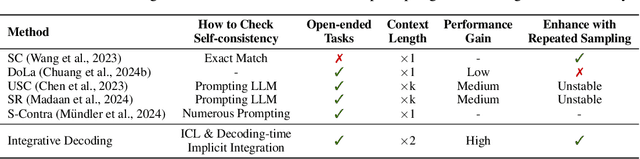
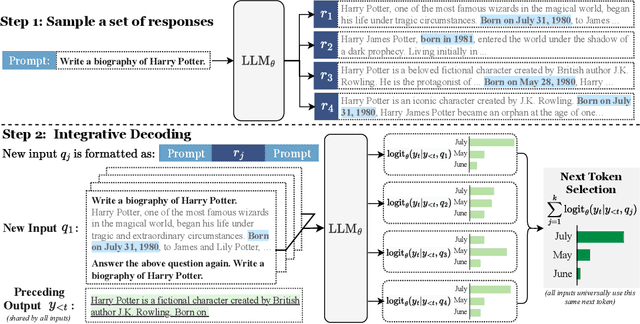
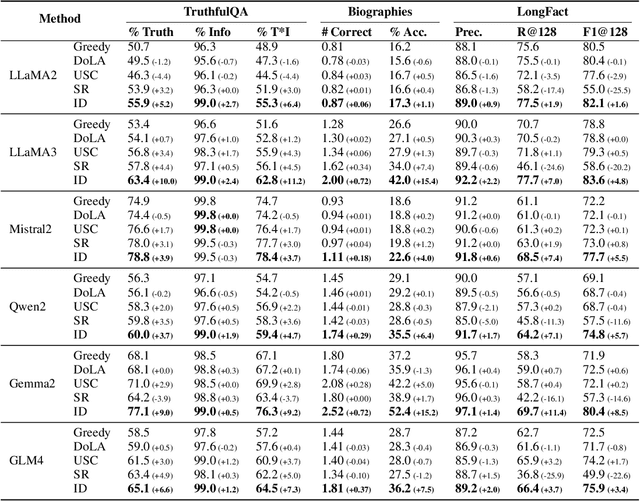
Self-consistency-based approaches, which involve repeatedly sampling multiple outputs and selecting the most consistent one as the final response, prove to be remarkably effective in improving the factual accuracy of large language models. Nonetheless, existing methods usually have strict constraints on the task format, largely limiting their applicability. In this paper, we present Integrative Decoding (ID), to unlock the potential of self-consistency in open-ended generation tasks. ID operates by constructing a set of inputs, each prepended with a previously sampled response, and then processes them concurrently, with the next token being selected by aggregating of all their corresponding predictions at each decoding step. In essence, this simple approach implicitly incorporates self-consistency in the decoding objective. Extensive evaluation shows that ID consistently enhances factuality over a wide range of language models, with substantial improvements on the TruthfulQA (+11.2%), Biographies (+15.4%) and LongFact (+8.5%) benchmarks. The performance gains amplify progressively as the number of sampled responses increases, indicating the potential of ID to scale up with repeated sampling.