 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Divergence Regularization in LLM RL
Jun 08, 2026Reinforcement learning (RL) has become a key component of post-training large language models (LLMs). In practice, LLM RL is often off-policy because of training-inference mismatch and policy staleness, making trust-region control essential for stable optimization. Mainstream methods such as PPO and GRPO approximate this control with a ratio-clipping mechanism, but the importance ratio can be a poor proxy for distributional shift in long-tailed vocabularies. Recent work such as DPPO addresses this mismatch by replacing ratio-based clipping with a divergence-based mask, yielding a trust region defined by the sampled token's absolute probability shift. However, DPPO still relies on a hard mask: once a token crosses the trust-region boundary in a harmful direction, its gradient is discarded rather than corrected. To address this, we propose Divergence Regularized Policy Optimization (DRPO), which replaces the hard mask with a smooth advantage-weighted quadratic regularizer on policy shift. DRPO preserves the same trust-region geometry as DPPO while inducing bounded, continuous gradient weights that attenuate diverging updates and provide corrective signals beyond the boundary. Experiments across model scales, architectures, and precision settings show that DRPO improves the stability and efficiency of LLM RL training.
AgentSPEX: An Agent SPecification and EXecution Language
Apr 14, 2026Language-model agent systems commonly rely on reactive prompting, in which a single instruction guides the model through an open-ended sequence of reasoning and tool-use steps, leaving control flow and intermediate state implicit and making agent behavior potentially difficult to control. Orchestration frameworks such as LangGraph, DSPy, and CrewAI impose greater structure through explicit workflow definitions, but tightly couple workflow logic with Python, making agents difficult to maintain and modify. In this paper, we introduce AgentSPEX, an Agent SPecification and EXecution Language for specifying LLM-agent workflows with explicit control flow and modular structure, along with a customizable agent harness. AgentSPEX supports typed steps, branching and loops, parallel execution, reusable submodules, and explicit state management, and these workflows execute within an agent harness that provides tool access, a sandboxed virtual environment, and support for checkpointing, verification, and logging. Furthermore, we provide a visual editor with synchronized graph and workflow views for authoring and inspection. We include ready-to-use agents for deep research and scientific research, and we evaluate AgentSPEX on 7 benchmarks. Finally, we show through a user study that AgentSPEX provides a more interpretable and accessible workflow-authoring paradigm than a popular existing agent framework.
Supervised Fine-Tuning versus Reinforcement Learning: A Study of Post-Training Methods for Large Language Models
Mar 14, 2026Pre-trained Large Language Model (LLM) exhibits broad capabilities, yet, for specific tasks or domains their attainment of higher accuracy and more reliable reasoning generally depends on post-training through Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). Although often treated as distinct methodologies, recent theoretical and empirical developments demonstrate that SFT and RL are closely connected. This study presents a comprehensive and unified perspective on LLM post-training with SFT and RL. We first provide an in-depth overview of both techniques, examining their objectives, algorithmic structures, and data requirements. We then systematically analyze their interplay, highlighting frameworks that integrate SFT and RL, hybrid training pipelines, and methods that leverage their complementary strengths. Drawing on a representative set of recent application studies from 2023 to 2025, we identify emerging trends, characterize the rapid shift toward hybrid post-training paradigms, and distill key takeaways that clarify when and why each method is most effective. By synthesizing theoretical insights, practical methodologies, and empirical evidence, this study establishes a coherent understanding of SFT and RL within a unified framework and outlines promising directions for future research in scalable, efficient, and generalizable LLM post-training.
PRL: Process Reward Learning Improves LLMs' Reasoning Ability and Broadens the Reasoning Boundary
Jan 15, 2026Improving the reasoning abilities of Large Language Models (LLMs) has been a continuous topic recently. But most relevant works are based on outcome rewards at the trajectory level, missing fine-grained supervision during the reasoning process. Other existing training frameworks that try to combine process signals together to optimize LLMs also rely heavily on tedious additional steps like MCTS, training a separate reward model, etc., doing harm to the training efficiency. Moreover, the intuition behind the process signals design lacks rigorous theoretical support, leaving the understanding of the optimization mechanism opaque. In this paper, we propose Process Reward Learning (PRL), which decomposes the entropy regularized reinforcement learning objective into intermediate steps, with rigorous process rewards that could be assigned to models accordingly. Starting from theoretical motivation, we derive the formulation of PRL that is essentially equivalent to the objective of reward maximization plus a KL-divergence penalty term between the policy model and a reference model. However, PRL could turn the outcome reward into process supervision signals, which helps better guide the exploration during RL optimization. From our experiment results, we demonstrate that PRL not only improves the average performance for LLMs' reasoning ability measured by average @ n, but also broadens the reasoning boundary by improving the pass @ n metric. Extensive experiments show the effectiveness of PRL could be verified and generalized.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Why is Your Language Model a Poor Implicit Reward Model?
Jul 10, 2025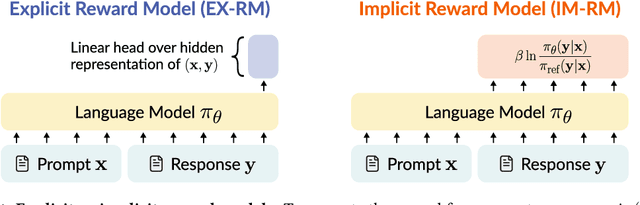
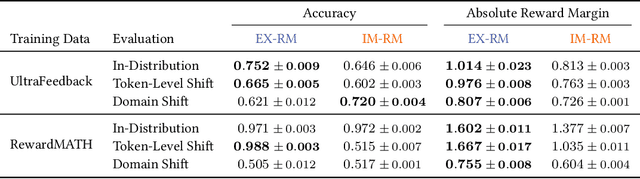
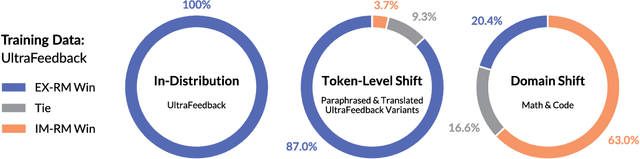
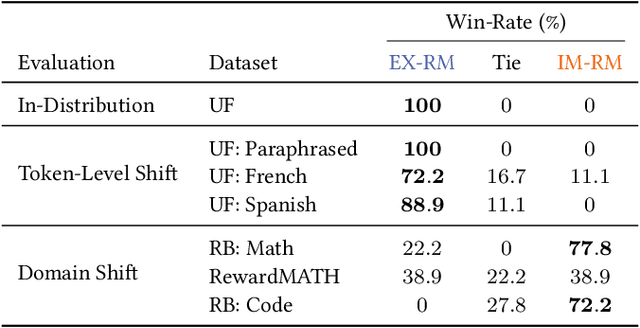
Reward models are key to language model post-training and inference pipelines. Conveniently, recent work showed that every language model defines an implicit reward model (IM-RM), without requiring any architectural changes. However, such IM-RMs tend to generalize worse, especially out-of-distribution, compared to explicit reward models (EX-RMs) that apply a dedicated linear head over the hidden representations of a language model. The existence of a generalization gap is puzzling, as EX-RMs and IM-RMs are nearly identical. They can be trained using the same data, loss function, and language model, and differ only in how the reward is computed. Towards a fundamental understanding of the implicit biases underlying different reward model types, we investigate the root cause of this gap. Our main finding, backed by theory and experiments, is that IM-RMs rely more heavily on superficial token-level cues. Consequently, they often generalize worse than EX-RMs under token-level distribution shifts, as well as in-distribution. Furthermore, we provide evidence against alternative hypotheses for the generalization gap. Most notably, we challenge the intuitive claim that IM-RMs struggle in tasks where generation is harder than verification because they can operate both as a verifier and a generator. Taken together, our results highlight that seemingly minor design choices can substantially impact the generalization behavior of reward models.
MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
May 30, 2025Reward modeling is a key step in building safe foundation models when applying reinforcement learning from human feedback (RLHF) to align Large Language Models (LLMs). However, reward modeling based on the Bradley-Terry (BT) model assumes a global reward function, failing to capture the inherently diverse and heterogeneous human preferences. Hence, such oversimplification limits LLMs from supporting personalization and pluralistic alignment. Theoretically, we show that when human preferences follow a mixture distribution of diverse subgroups, a single BT model has an irreducible error. While existing solutions, such as multi-objective learning with fine-grained annotations, help address this issue, they are costly and constrained by predefined attributes, failing to fully capture the richness of human values. In this work, we introduce MiCRo, a two-stage framework that enhances personalized preference learning by leveraging large-scale binary preference datasets without requiring explicit fine-grained annotations. In the first stage, MiCRo introduces context-aware mixture modeling approach to capture diverse human preferences. In the second stage, MiCRo integrates an online routing strategy that dynamically adapts mixture weights based on specific context to resolve ambiguity, allowing for efficient and scalable preference adaptation with minimal additional supervision. Experiments on multiple preference datasets demonstrate that MiCRo effectively captures diverse human preferences and significantly improves downstream personalization.
Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
May 05, 2025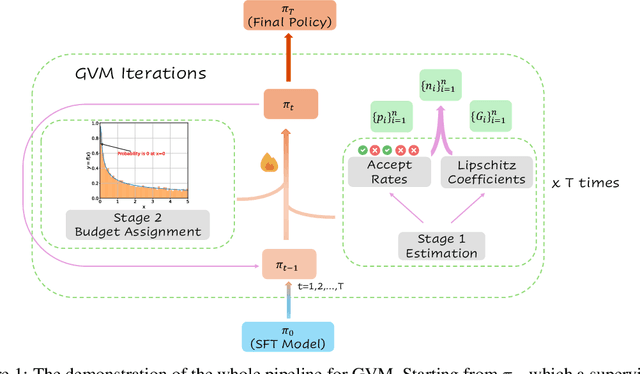
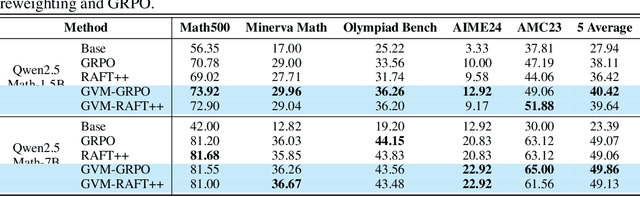
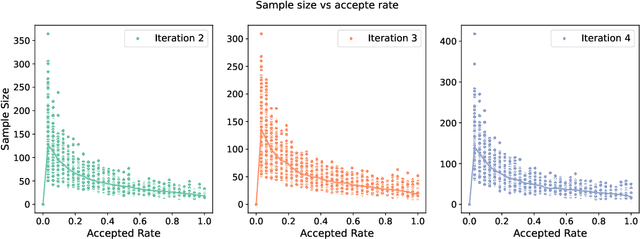
Chain-of-thought (CoT) reasoning in large language models (LLMs) can be formalized as a latent variable problem, where the model needs to generate intermediate reasoning steps. While prior approaches such as iterative reward-ranked fine-tuning (RAFT) have relied on such formulations, they typically apply uniform inference budgets across prompts, which fails to account for variability in difficulty and convergence behavior. This work identifies the main bottleneck in CoT training as inefficient stochastic gradient estimation due to static sampling strategies. We propose GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance under a computational budget constraint. The method dynamically allocates computational resources by monitoring prompt acceptance rates and stochastic gradient norms, ensuring that the resulting gradient variance is minimized. Our theoretical analysis shows that the proposed dynamic sampling strategy leads to accelerated convergence guarantees under suitable conditions. Experiments on mathematical reasoning show that GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT. The proposed dynamic sampling strategy is general and can be incorporated into other reinforcement learning algorithms, such as GRPO, leading to similar improvements in convergence and test accuracy. Our code is available at https://github.com/RLHFlow/GVM.
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
Apr 15, 2025



Reinforcement learning (RL) has become a prevailing approach for fine-tuning large language models (LLMs) on complex reasoning tasks. Among recent methods, GRPO stands out for its empirical success in training models such as DeepSeek-R1, yet the sources of its effectiveness remain poorly understood. In this work, we revisit GRPO from a reinforce-like algorithm perspective and analyze its core components. Surprisingly, we find that a simple rejection sampling baseline, RAFT, which trains only on positively rewarded samples, yields competitive performance than GRPO and PPO. Our ablation studies reveal that GRPO's main advantage arises from discarding prompts with entirely incorrect responses, rather than from its reward normalization. Motivated by this insight, we propose Reinforce-Rej, a minimal extension of policy gradient that filters both entirely incorrect and entirely correct samples. Reinforce-Rej improves KL efficiency and stability, serving as a lightweight yet effective alternative to more complex RL algorithms. We advocate RAFT as a robust and interpretable baseline, and suggest that future advances should focus on more principled designs for incorporating negative samples, rather than relying on them indiscriminately. Our findings provide guidance for future work in reward-based LLM post-training.
FANS -- Formal Answer Selection for Natural Language Math Reasoning Using Lean4
Mar 05, 2025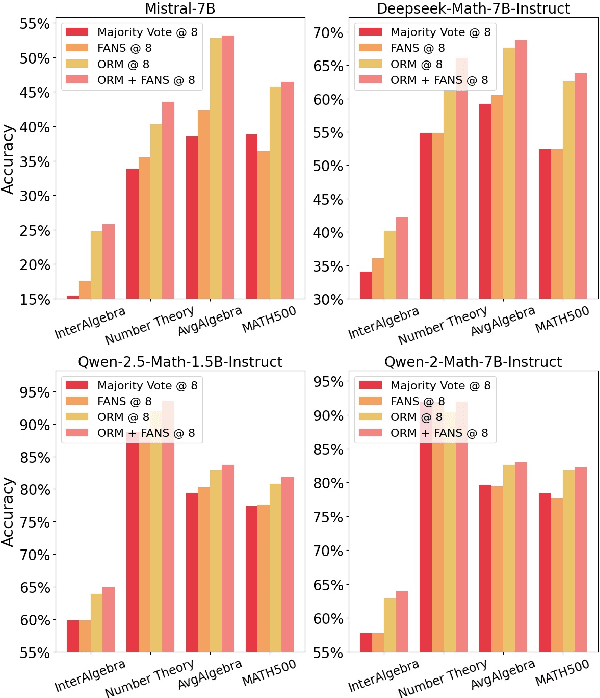



Large Language Models (LLMs) have displayed astonishing abilities in various tasks, especially in text generation, classification, question answering, etc. However, the reasoning ability of LLMs still faces many debates. The inherent ambiguity of Natural Language (NL) limits LLMs' ability to perform verifiable reasoning, making its answers lack coherence and trustworthy support. To tackle the above problems, we propose a novel framework named FANS: Formal ANswer Selection for Natural Language Math Reasoning Using Lean4. To the best of our knowledge, it is the first framework that utilizes Lean4 to enhance LLMs' NL math reasoning ability. In particular, given an NL math question and LLM-generated answers, FANS first translates it into Lean4 theorem statements. Then it tries to prove it using a Lean4 prover and verify it by Lean4. Finally, it uses the FL result to assist in answer selection. It enhances LLMs' NL math ability in providing a computer-verifiable solution for its correct answer and proposes an alternative method for answer selection beyond the reward model. Extensive experiments indicate the effectiveness of our framework. It can improve the accuracy rate of reward model enhanced LLMs in the MATH-500 dataset by at most 1.91% and AMC-23 by at most 8.33% on strong reward-model baselines. In some particular fields like number theory that Lean4 experts in, we can even select all correct solutions. The qualitative analysis also shows our framework can make NL results formally backed by Lean4 proofs. As a pioneering work in the corresponding field, we will open-source all our models and datasets to further boost the development of the field.