 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHIMERA: Compact Synthetic Data for Generalizable LLM Reasoning
Mar 01, 2026Large Language Models (LLMs) have recently exhibited remarkable reasoning capabilities, largely enabled by supervised fine-tuning (SFT)- and reinforcement learning (RL)-based post-training on high-quality reasoning data. However, reproducing and extending these capabilities in open and scalable settings is hindered by three fundamental data-centric challenges: (1) the cold-start problem, arising from the lack of seed datasets with detailed, long Chain-of-Thought (CoT) trajectories needed to initialize reasoning policies; (2) limited domain coverage, as most existing open-source reasoning datasets are concentrated in mathematics, with limited coverage of broader scientific disciplines; and (3) the annotation bottleneck, where the difficulty of frontier-level reasoning tasks makes reliable human annotation prohibitively expensive or infeasible. To address these challenges, we introduce CHIMERA, a compact synthetic reasoning dataset comprising 9K samples for generalizable cross-domain reasoning. CHIMERA is constructed with three key properties: (1) it provides rich, long CoT reasoning trajectories synthesized by state-of-the-art reasoning models; (2) it has broad and structured coverage, spanning 8 major scientific disciplines and over 1K fine-grained topics organized via a model-generated hierarchical taxonomy; and (3) it employs a fully automated, scalable evaluation pipeline that uses strong reasoning models to cross-validate both problem validity and answer correctness. We use CHIMERA to post-train a 4B Qwen3 model. Despite the dataset's modest size, the resulting model achieves strong performance on a suite of challenging reasoning benchmarks, including GPQA-Diamond, AIME 24/25/26, HMMT 25, and Humanity's Last Exam, approaching or matching the reasoning performance of substantially larger models such as DeepSeek-R1 and Qwen3-235B.
Multi-Agent Teams Hold Experts Back
Feb 03, 2026Multi-agent LLM systems are increasingly deployed as autonomous collaborators, where agents interact freely rather than execute fixed, pre-specified workflows. In such settings, effective coordination cannot be fully designed in advance and must instead emerge through interaction. However, most prior work enforces coordination through fixed roles, workflows, or aggregation rules, leaving open the question of how well self-organizing teams perform when coordination is unconstrained. Drawing on organizational psychology, we study whether self-organizing LLM teams achieve strong synergy, where team performance matches or exceeds the best individual member. Across human-inspired and frontier ML benchmarks, we find that -- unlike human teams -- LLM teams consistently fail to match their expert agent's performance, even when explicitly told who the expert is, incurring performance losses of up to 37.6%. Decomposing this failure, we show that expert leveraging, rather than identification, is the primary bottleneck. Conversational analysis reveals a tendency toward integrative compromise -- averaging expert and non-expert views rather than appropriately weighting expertise -- which increases with team size and correlates negatively with performance. Interestingly, this consensus-seeking behavior improves robustness to adversarial agents, suggesting a trade-off between alignment and effective expertise utilization. Our findings reveal a significant gap in the ability of self-organizing multi-agent teams to harness the collective expertise of their members.
Checklists Are Better Than Reward Models For Aligning Language Models
Jul 24, 2025



Language models must be adapted to understand and follow user instructions. Reinforcement learning is widely used to facilitate this -- typically using fixed criteria such as "helpfulness" and "harmfulness". In our work, we instead propose using flexible, instruction-specific criteria as a means of broadening the impact that reinforcement learning can have in eliciting instruction following. We propose "Reinforcement Learning from Checklist Feedback" (RLCF). From instructions, we extract checklists and evaluate how well responses satisfy each item - using both AI judges and specialized verifier programs - then combine these scores to compute rewards for RL. We compare RLCF with other alignment methods applied to a strong instruction following model (Qwen2.5-7B-Instruct) on five widely-studied benchmarks -- RLCF is the only method to improve performance on every benchmark, including a 4-point boost in hard satisfaction rate on FollowBench, a 6-point increase on InFoBench, and a 3-point rise in win rate on Arena-Hard. These results establish checklist feedback as a key tool for improving language models' support of queries that express a multitude of needs.
Interleaved Reasoning for Large Language Models via Reinforcement Learning
May 26, 2025Long chain-of-thought (CoT) significantly enhances large language models' (LLM) reasoning capabilities. However, the extensive reasoning traces lead to inefficiencies and an increased time-to-first-token (TTFT). We propose a novel training paradigm that uses reinforcement learning (RL) to guide reasoning LLMs to interleave thinking and answering for multi-hop questions. We observe that models inherently possess the ability to perform interleaved reasoning, which can be further enhanced through RL. We introduce a simple yet effective rule-based reward to incentivize correct intermediate steps, which guides the policy model toward correct reasoning paths by leveraging intermediate signals generated during interleaved reasoning. Extensive experiments conducted across five diverse datasets and three RL algorithms (PPO, GRPO, and REINFORCE++) demonstrate consistent improvements over traditional think-answer reasoning, without requiring external tools. Specifically, our approach reduces TTFT by over 80% on average and improves up to 19.3% in Pass@1 accuracy. Furthermore, our method, trained solely on question answering and logical reasoning datasets, exhibits strong generalization ability to complex reasoning datasets such as MATH, GPQA, and MMLU. Additionally, we conduct in-depth analysis to reveal several valuable insights into conditional reward modeling.
Statistical Guarantees for Lifelong Reinforcement Learning using PAC-Bayesian Theory
Nov 01, 2024



Lifelong reinforcement learning (RL) has been developed as a paradigm for extending single-task RL to more realistic, dynamic settings. In lifelong RL, the "life" of an RL agent is modeled as a stream of tasks drawn from a task distribution. We propose EPIC (\underline{E}mpirical \underline{P}AC-Bayes that \underline{I}mproves \underline{C}ontinuously), a novel algorithm designed for lifelong RL using PAC-Bayes theory. EPIC learns a shared policy distribution, referred to as the \textit{world policy}, which enables rapid adaptation to new tasks while retaining valuable knowledge from previous experiences. Our theoretical analysis establishes a relationship between the algorithm's generalization performance and the number of prior tasks preserved in memory. We also derive the sample complexity of EPIC in terms of RL regret. Extensive experiments on a variety of environments demonstrate that EPIC significantly outperforms existing methods in lifelong RL, offering both theoretical guarantees and practical efficacy through the use of the world policy.
TIS-DPO: Token-level Importance Sampling for Direct Preference Optimization With Estimated Weights
Oct 06, 2024

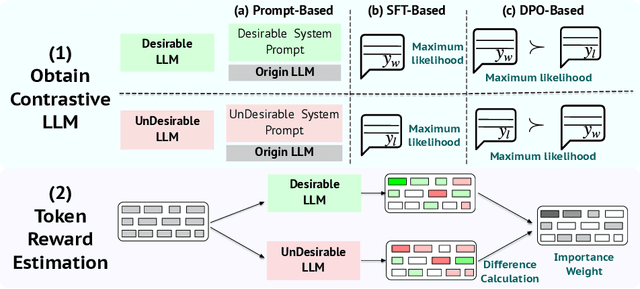
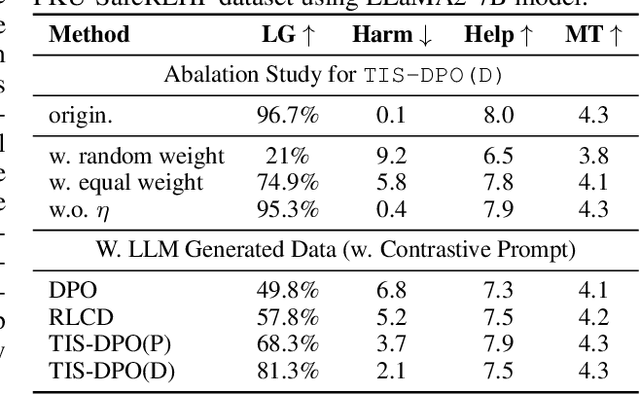
Direct Preference Optimization (DPO) has been widely adopted for preference alignment of Large Language Models (LLMs) due to its simplicity and effectiveness. However, DPO is derived as a bandit problem in which the whole response is treated as a single arm, ignoring the importance differences between tokens, which may affect optimization efficiency and make it difficult to achieve optimal results. In this work, we propose that the optimal data for DPO has equal expected rewards for each token in winning and losing responses, as there is no difference in token importance. However, since the optimal dataset is unavailable in practice, we propose using the original dataset for importance sampling to achieve unbiased optimization. Accordingly, we propose a token-level importance sampling DPO objective named TIS-DPO that assigns importance weights to each token based on its reward. Inspired by previous works, we estimate the token importance weights using the difference in prediction probabilities from a pair of contrastive LLMs. We explore three methods to construct these contrastive LLMs: (1) guiding the original LLM with contrastive prompts, (2) training two separate LLMs using winning and losing responses, and (3) performing forward and reverse DPO training with winning and losing responses. Experiments show that TIS-DPO significantly outperforms various baseline methods on harmlessness and helpfulness alignment and summarization tasks. We also visualize the estimated weights, demonstrating their ability to identify key token positions.
Beyond Worst-case Attacks: Robust RL with Adaptive Defense via Non-dominated Policies
Feb 20, 2024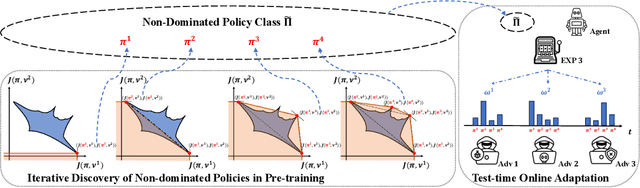
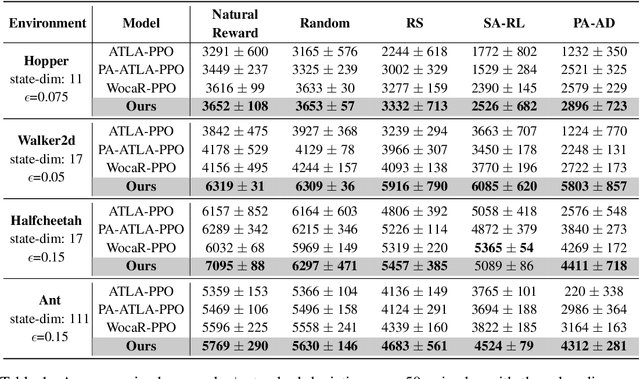
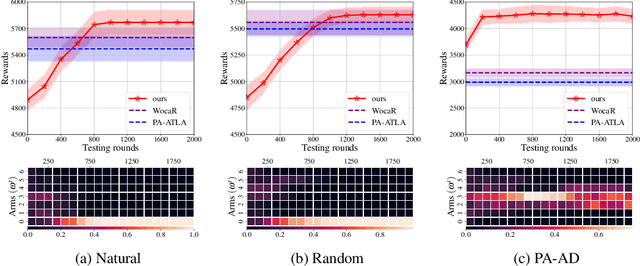
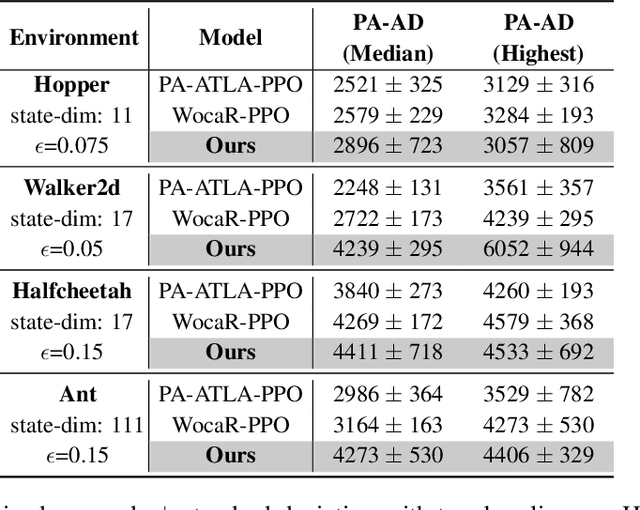
In light of the burgeoning success of reinforcement learning (RL) in diverse real-world applications, considerable focus has been directed towards ensuring RL policies are robust to adversarial attacks during test time. Current approaches largely revolve around solving a minimax problem to prepare for potential worst-case scenarios. While effective against strong attacks, these methods often compromise performance in the absence of attacks or the presence of only weak attacks. To address this, we study policy robustness under the well-accepted state-adversarial attack model, extending our focus beyond only worst-case attacks. We first formalize this task at test time as a regret minimization problem and establish its intrinsic hardness in achieving sublinear regret when the baseline policy is from a general continuous policy class, $\Pi$. This finding prompts us to \textit{refine} the baseline policy class $\Pi$ prior to test time, aiming for efficient adaptation within a finite policy class $\Tilde{\Pi}$, which can resort to an adversarial bandit subroutine. In light of the importance of a small, finite $\Tilde{\Pi}$, we propose a novel training-time algorithm to iteratively discover \textit{non-dominated policies}, forming a near-optimal and minimal $\Tilde{\Pi}$, thereby ensuring both robustness and test-time efficiency. Empirical validation on the Mujoco corroborates the superiority of our approach in terms of natural and robust performance, as well as adaptability to various attack scenarios.
Shadowcast: Stealthy Data Poisoning Attacks Against Vision-Language Models
Feb 05, 2024



Vision-Language Models (VLMs) excel in generating textual responses from visual inputs, yet their versatility raises significant security concerns. This study takes the first step in exposing VLMs' susceptibility to data poisoning attacks that can manipulate responses to innocuous, everyday prompts. We introduce Shadowcast, a stealthy data poisoning attack method where poison samples are visually indistinguishable from benign images with matching texts. Shadowcast demonstrates effectiveness in two attack types. The first is Label Attack, tricking VLMs into misidentifying class labels, such as confusing Donald Trump for Joe Biden. The second is Persuasion Attack, which leverages VLMs' text generation capabilities to craft narratives, such as portraying junk food as health food, through persuasive and seemingly rational descriptions. We show that Shadowcast are highly effective in achieving attacker's intentions using as few as 50 poison samples. Moreover, these poison samples remain effective across various prompts and are transferable across different VLM architectures in the black-box setting. This work reveals how poisoned VLMs can generate convincing yet deceptive misinformation and underscores the importance of data quality for responsible deployments of VLMs. Our code is available at: https://github.com/umd-huang-lab/VLM-Poisoning.
O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
Oct 22, 2023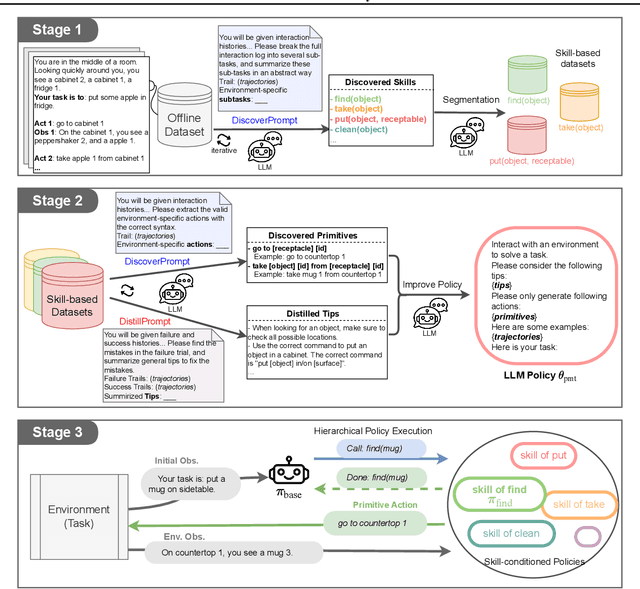
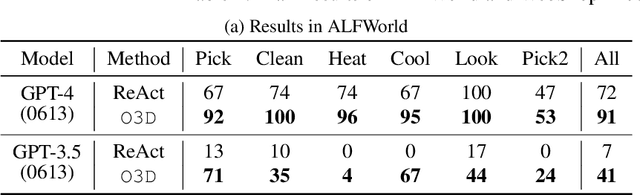
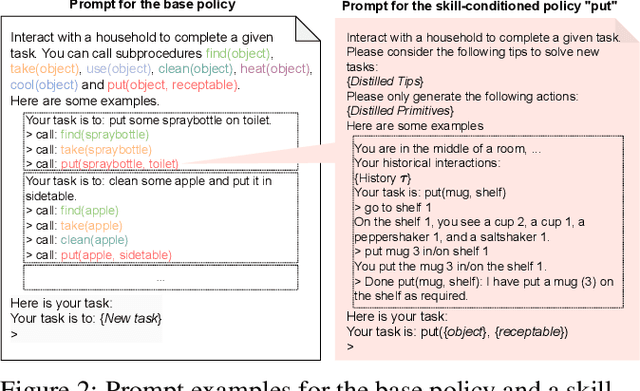

Recent advancements in large language models (LLMs) have exhibited promising performance in solving sequential decision-making problems. By imitating few-shot examples provided in the prompts (i.e., in-context learning), an LLM agent can interact with an external environment and complete given tasks without additional training. However, such few-shot examples are often insufficient to generate high-quality solutions for complex and long-horizon tasks, while the limited context length cannot consume larger-scale demonstrations. To this end, we propose an offline learning framework that utilizes offline data at scale (e.g, logs of human interactions) to facilitate the in-context learning performance of LLM agents. We formally define LLM-powered policies with both text-based approaches and code-based approaches. We then introduce an Offline Data-driven Discovery and Distillation (O3D) framework to improve LLM-powered policies without finetuning. O3D automatically discovers reusable skills and distills generalizable knowledge across multiple tasks based on offline interaction data, advancing the capability of solving downstream tasks. Empirical results under two interactive decision-making benchmarks (ALFWorld and WebShop) demonstrate that O3D can notably enhance the decision-making capabilities of LLMs through the offline discovery and distillation process, and consistently outperform baselines across various LLMs with both text-based-policy and code-based-policy.
Robustness to Multi-Modal Environment Uncertainty in MARL using Curriculum Learning
Oct 12, 2023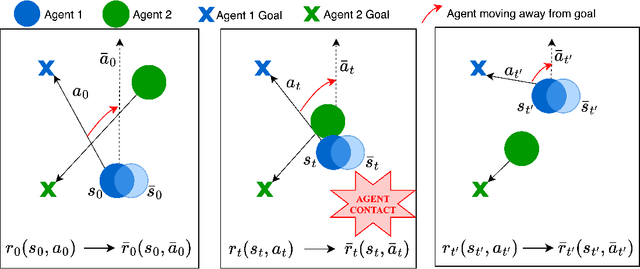
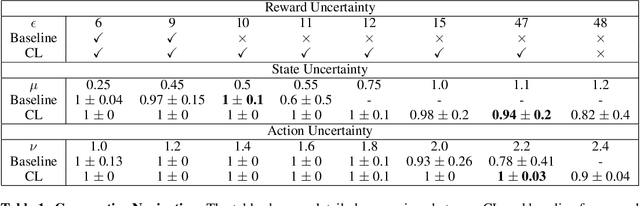
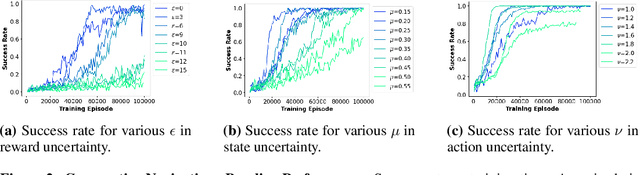
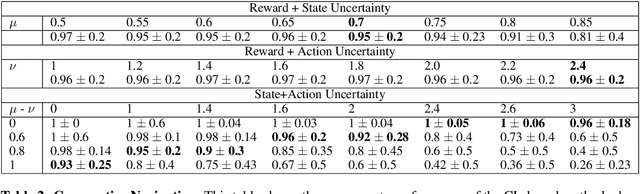
Multi-agent reinforcement learning (MARL) plays a pivotal role in tackling real-world challenges. However, the seamless transition of trained policies from simulations to real-world requires it to be robust to various environmental uncertainties. Existing works focus on finding Nash Equilibrium or the optimal policy under uncertainty in one environment variable (i.e. action, state or reward). This is because a multi-agent system itself is highly complex and unstationary. However, in real-world situation uncertainty can occur in multiple environment variables simultaneously. This work is the first to formulate the generalised problem of robustness to multi-modal environment uncertainty in MARL. To this end, we propose a general robust training approach for multi-modal uncertainty based on curriculum learning techniques. We handle two distinct environmental uncertainty simultaneously and present extensive results across both cooperative and competitive MARL environments, demonstrating that our approach achieves state-of-the-art levels of robustness.