 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data
Feb 18, 2026Human behavior is among the most scalable sources of data for learning physical intelligence, yet how to effectively leverage it for dexterous manipulation remains unclear. While prior work demonstrates human to robot transfer in constrained settings, it is unclear whether large scale human data can support fine grained, high degree of freedom dexterous manipulation. We present EgoScale, a human to dexterous manipulation transfer framework built on large scale egocentric human data. We train a Vision Language Action (VLA) model on over 20,854 hours of action labeled egocentric human video, more than 20 times larger than prior efforts, and uncover a log linear scaling law between human data scale and validation loss. This validation loss strongly correlates with downstream real robot performance, establishing large scale human data as a predictable supervision source. Beyond scale, we introduce a simple two stage transfer recipe: large scale human pretraining followed by lightweight aligned human robot mid training. This enables strong long horizon dexterous manipulation and one shot task adaptation with minimal robot supervision. Our final policy improves average success rate by 54% over a no pretraining baseline using a 22 DoF dexterous robotic hand, and transfers effectively to robots with lower DoF hands, indicating that large scale human motion provides a reusable, embodiment agnostic motor prior.
DexUMI: Using Human Hand as the Universal Manipulation Interface for Dexterous Manipulation
May 29, 2025We present DexUMI - a data collection and policy learning framework that uses the human hand as the natural interface to transfer dexterous manipulation skills to various robot hands. DexUMI includes hardware and software adaptations to minimize the embodiment gap between the human hand and various robot hands. The hardware adaptation bridges the kinematics gap using a wearable hand exoskeleton. It allows direct haptic feedback in manipulation data collection and adapts human motion to feasible robot hand motion. The software adaptation bridges the visual gap by replacing the human hand in video data with high-fidelity robot hand inpainting. We demonstrate DexUMI's capabilities through comprehensive real-world experiments on two different dexterous robot hand hardware platforms, achieving an average task success rate of 86%.
Flow as the Cross-Domain Manipulation Interface
Jul 21, 2024We present Im2Flow2Act, a scalable learning framework that enables robots to acquire manipulation skills from diverse data sources. The key idea behind Im2Flow2Act is to use object flow as the manipulation interface, bridging domain gaps between different embodiments (i.e., human and robot) and training environments (i.e., real-world and simulated). Im2Flow2Act comprises two components: a flow generation network and a flow-conditioned policy. The flow generation network, trained on human demonstration videos, generates object flow from the initial scene image, conditioned on the task description. The flow-conditioned policy, trained on simulated robot play data, maps the generated object flow to robot actions to realize the desired object movements. By using flow as input, this policy can be directly deployed in the real world with a minimal sim-to-real gap. By leveraging real-world human videos and simulated robot play data, we bypass the challenges of teleoperating physical robots in the real world, resulting in a scalable system for diverse tasks. We demonstrate Im2Flow2Act's capabilities in a variety of real-world tasks, including the manipulation of rigid, articulated, and deformable objects.
O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
Oct 22, 2023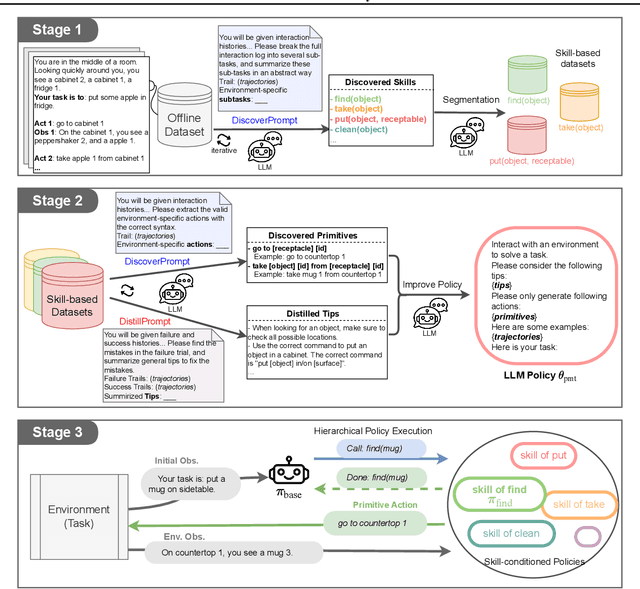
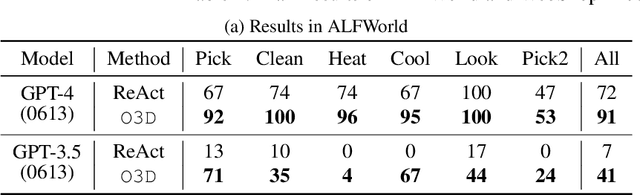
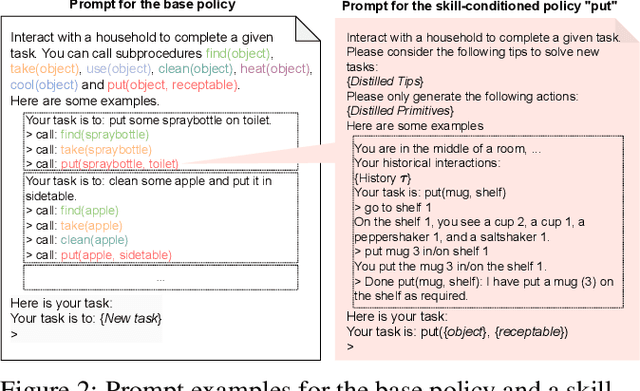

Recent advancements in large language models (LLMs) have exhibited promising performance in solving sequential decision-making problems. By imitating few-shot examples provided in the prompts (i.e., in-context learning), an LLM agent can interact with an external environment and complete given tasks without additional training. However, such few-shot examples are often insufficient to generate high-quality solutions for complex and long-horizon tasks, while the limited context length cannot consume larger-scale demonstrations. To this end, we propose an offline learning framework that utilizes offline data at scale (e.g, logs of human interactions) to facilitate the in-context learning performance of LLM agents. We formally define LLM-powered policies with both text-based approaches and code-based approaches. We then introduce an Offline Data-driven Discovery and Distillation (O3D) framework to improve LLM-powered policies without finetuning. O3D automatically discovers reusable skills and distills generalizable knowledge across multiple tasks based on offline interaction data, advancing the capability of solving downstream tasks. Empirical results under two interactive decision-making benchmarks (ALFWorld and WebShop) demonstrate that O3D can notably enhance the decision-making capabilities of LLMs through the offline discovery and distillation process, and consistently outperform baselines across various LLMs with both text-based-policy and code-based-policy.
XSkill: Cross Embodiment Skill Discovery
Jul 19, 2023Human demonstration videos are a widely available data source for robot learning and an intuitive user interface for expressing desired behavior. However, directly extracting reusable robot manipulation skills from unstructured human videos is challenging due to the big embodiment difference and unobserved action parameters. To bridge this embodiment gap, this paper introduces XSkill, an imitation learning framework that 1) discovers a cross-embodiment representation called skill prototypes purely from unlabeled human and robot manipulation videos, 2) transfers the skill representation to robot actions using conditional diffusion policy, and finally, 3) composes the learned skill to accomplish unseen tasks specified by a human prompt video. Our experiments in simulation and real-world environments show that the discovered skill prototypes facilitate both skill transfer and composition for unseen tasks, resulting in a more general and scalable imitation learning framework. The performance of XSkill is best understood from the anonymous website: https://xskillcorl.github.io.
Towards Multi-Agent Reinforcement Learning driven Over-The-Counter Market Simulations
Oct 13, 2022

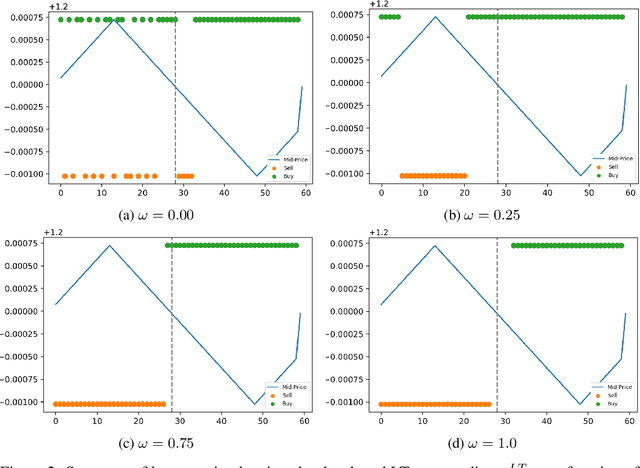

We study a game between liquidity provider and liquidity taker agents interacting in an over-the-counter market, for which the typical example is foreign exchange. We show how a suitable design of parameterized families of reward functions coupled with associated shared policy learning constitutes an efficient solution to this problem. Precisely, we show that our deep-reinforcement-learning-driven agents learn emergent behaviors relative to a wide spectrum of incentives encompassing profit-and-loss, optimal execution and market share, by playing against each other. In particular, we find that liquidity providers naturally learn to balance hedging and skewing as a function of their incentives, where the latter refers to setting their buy and sell prices asymmetrically as a function of their inventory. We further introduce a novel RL-based calibration algorithm which we found performed well at imposing constraints on the game equilibrium, both on toy and real market data.
ASPiRe:Adaptive Skill Priors for Reinforcement Learning
Sep 30, 2022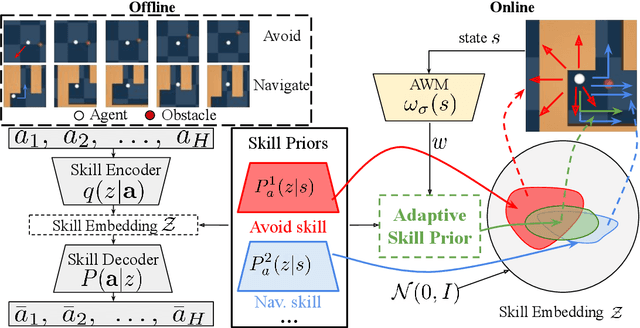
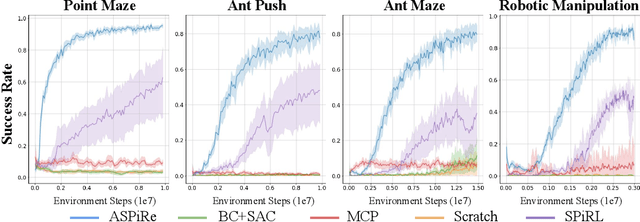
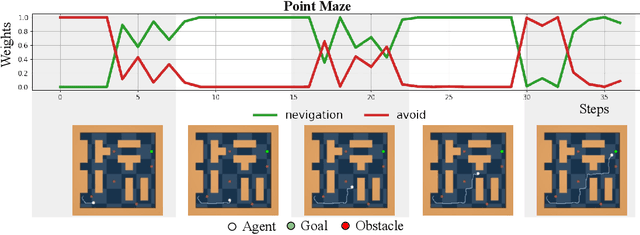
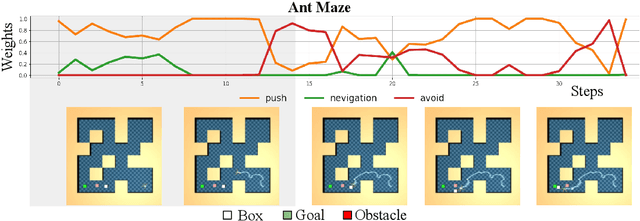
We introduce ASPiRe (Adaptive Skill Prior for RL), a new approach that leverages prior experience to accelerate reinforcement learning. Unlike existing methods that learn a single skill prior from a large and diverse dataset, our framework learns a library of different distinction skill priors (i.e., behavior priors) from a collection of specialized datasets, and learns how to combine them to solve a new task. This formulation allows the algorithm to acquire a set of specialized skill priors that are more reusable for downstream tasks; however, it also brings up additional challenges of how to effectively combine these unstructured sets of skill priors to form a new prior for new tasks. Specifically, it requires the agent not only to identify which skill prior(s) to use but also how to combine them (either sequentially or concurrently) to form a new prior. To achieve this goal, ASPiRe includes Adaptive Weight Module (AWM) that learns to infer an adaptive weight assignment between different skill priors and uses them to guide policy learning for downstream tasks via weighted Kullback-Leibler divergences. Our experiments demonstrate that ASPiRe can significantly accelerate the learning of new downstream tasks in the presence of multiple priors and show improvement on competitive baselines.
Mixture of basis for interpretable continual learning with distribution shifts
Jan 05, 2022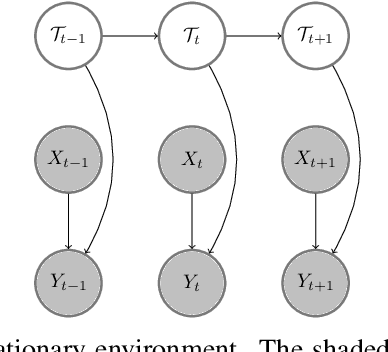
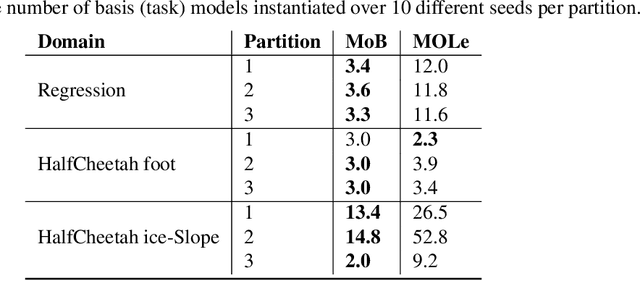
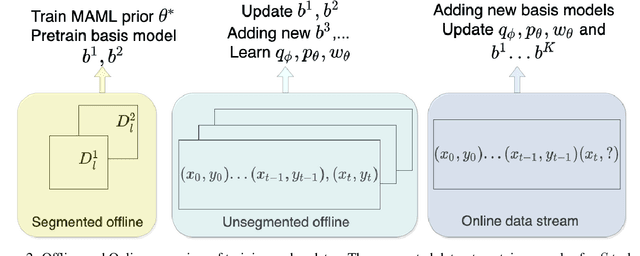
Continual learning in environments with shifting data distributions is a challenging problem with several real-world applications. In this paper we consider settings in which the data distribution(task) shifts abruptly and the timing of these shifts are not known. Furthermore, we consider a semi-supervised task-agnostic setting in which the learning algorithm has access to both task-segmented and unsegmented data for offline training. We propose a novel approach called mixture of Basismodels (MoB) for addressing this problem setting. The core idea is to learn a small set of basis models and to construct a dynamic, task-dependent mixture of the models to predict for the current task. We also propose a new methodology to detect observations that are out-of-distribution with respect to the existing basis models and to instantiate new models as needed. We test our approach in multiple domains and show that it attains better prediction error than existing methods in most cases while using fewer models than other multiple model approaches. Moreover, we analyze the latent task representations learned by MoB and show that similar tasks tend to cluster in the latent space and that the latent representation shifts at the task boundaries when tasks are dissimilar.
Towards a fully RL-based Market Simulator
Nov 08, 2021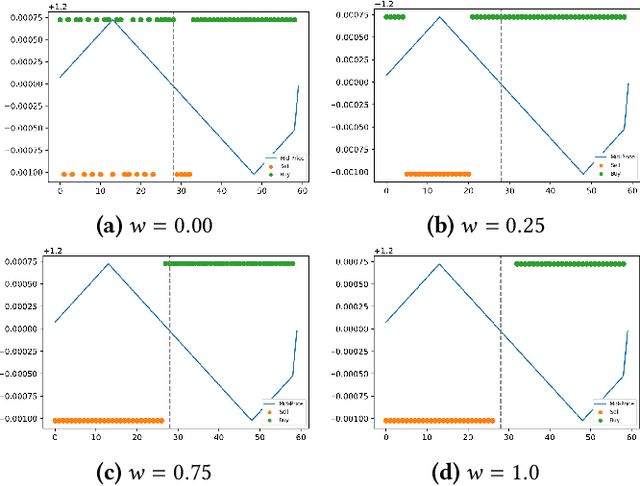
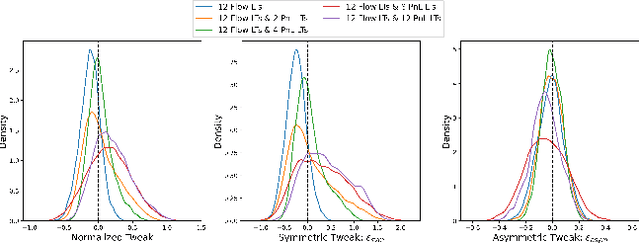
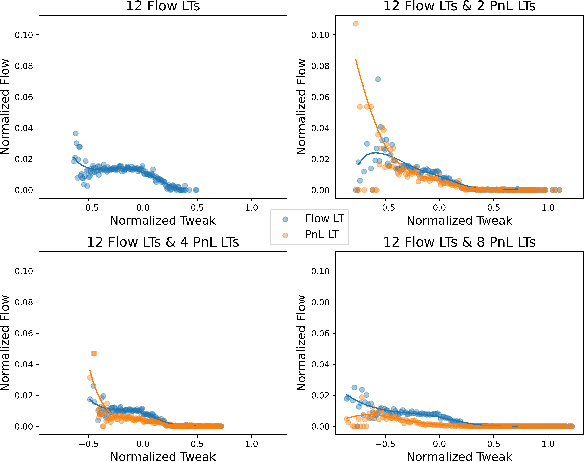
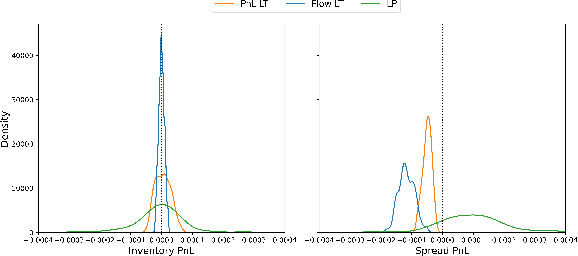
We present a new financial framework where two families of RL-based agents representing the Liquidity Providers and Liquidity Takers learn simultaneously to satisfy their objective. Thanks to a parametrized reward formulation and the use of Deep RL, each group learns a shared policy able to generalize and interpolate over a wide range of behaviors. This is a step towards a fully RL-based market simulator replicating complex market conditions particularly suited to study the dynamics of the financial market under various scenarios.
Reinforcement Learning for Market Making in a Multi-agent Dealer Market
Nov 14, 2019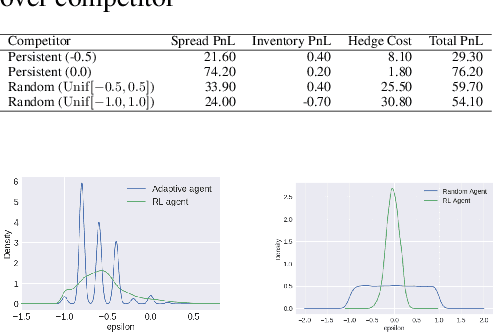
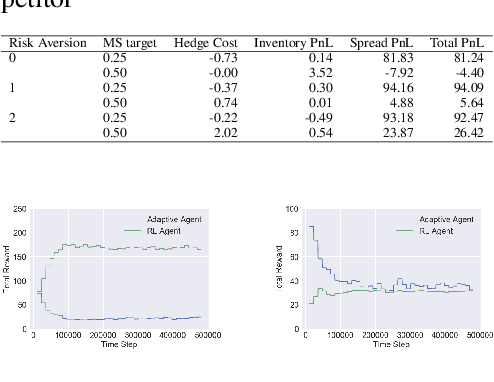
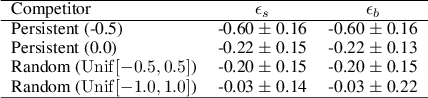

Market makers play an important role in providing liquidity to markets by continuously quoting prices at which they are willing to buy and sell, and managing inventory risk. In this paper, we build a multi-agent simulation of a dealer market and demonstrate that it can be used to understand the behavior of a reinforcement learning (RL) based market maker agent. We use the simulator to train an RL-based market maker agent with different competitive scenarios, reward formulations and market price trends (drifts). We show that the reinforcement learning agent is able to learn about its competitor's pricing policy; it also learns to manage inventory by smartly selecting asymmetric prices on the buy and sell sides (skewing), and maintaining a positive (or negative) inventory depending on whether the market price drift is positive (or negative). Finally, we propose and test reward formulations for creating risk averse RL-based market maker agents.