 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal World Time Series Benchmark Datasets with Distribution Shifts: Global Crude Oil Price and Volatility
Aug 21, 2023The scarcity of task-labeled time-series benchmarks in the financial domain hinders progress in continual learning. Addressing this deficit would foster innovation in this area. Therefore, we present COB, Crude Oil Benchmark datasets. COB includes 30 years of asset prices that exhibit significant distribution shifts and optimally generates corresponding task (i.e., regime) labels based on these distribution shifts for the three most important crude oils in the world. Our contributions include creating real-world benchmark datasets by transforming asset price data into volatility proxies, fitting models using expectation-maximization (EM), generating contextual task labels that align with real-world events, and providing these labels as well as the general algorithm to the public. We show that the inclusion of these task labels universally improves performance on four continual learning algorithms, some state-of-the-art, over multiple forecasting horizons. We hope these benchmarks accelerate research in handling distribution shifts in real-world data, especially due to the global importance of the assets considered. We've made the (1) raw price data, (2) task labels generated by our approach, (3) and code for our algorithm available at https://oilpricebenchmarks.github.io.
Mixture of basis for interpretable continual learning with distribution shifts
Jan 05, 2022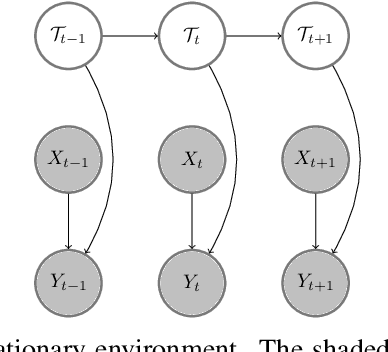
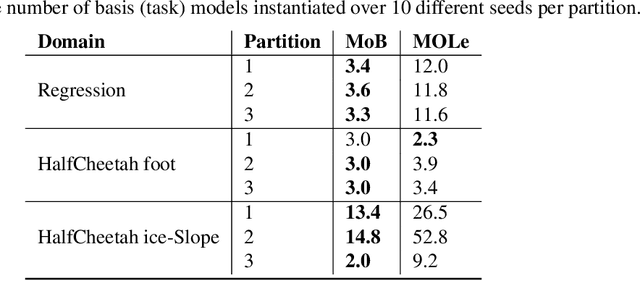
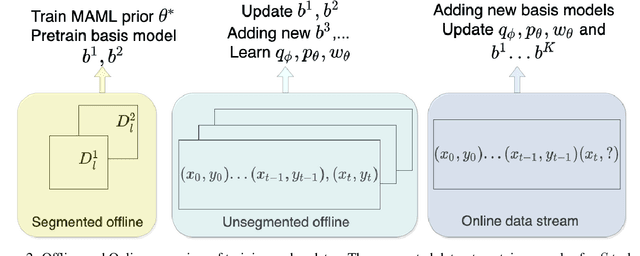
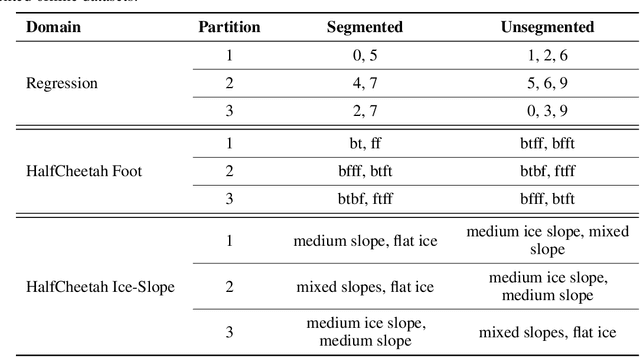
Continual learning in environments with shifting data distributions is a challenging problem with several real-world applications. In this paper we consider settings in which the data distribution(task) shifts abruptly and the timing of these shifts are not known. Furthermore, we consider a semi-supervised task-agnostic setting in which the learning algorithm has access to both task-segmented and unsegmented data for offline training. We propose a novel approach called mixture of Basismodels (MoB) for addressing this problem setting. The core idea is to learn a small set of basis models and to construct a dynamic, task-dependent mixture of the models to predict for the current task. We also propose a new methodology to detect observations that are out-of-distribution with respect to the existing basis models and to instantiate new models as needed. We test our approach in multiple domains and show that it attains better prediction error than existing methods in most cases while using fewer models than other multiple model approaches. Moreover, we analyze the latent task representations learned by MoB and show that similar tasks tend to cluster in the latent space and that the latent representation shifts at the task boundaries when tasks are dissimilar.
Lagrangian Duality in Reinforcement Learning
Jul 25, 2020Although duality is used extensively in certain fields, such as supervised learning in machine learning, it has been much less explored in others, such as reinforcement learning (RL). In this paper, we show how duality is involved in a variety of RL work, from that which spearheaded the field, such as Richard Bellman's value iteration, to that which was done within just the past few years yet has already had significant impact, such as TRPO, A3C, and GAIL. We show that duality is not uncommon in reinforcement learning, especially when value iteration, or dynamic programming, is used or when first or second order approximations are made to transform initially intractable problems into tractable convex programs.
Complex Skill Acquisition through Simple Skill Adversarial Imitation Learning
Jul 20, 2020

Humans are able to think of complex tasks as combinations of simpler subtasks in order to learn the complex tasks more efficiently. For example, a backflip could be considered a combination of four subskills: jumping, tucking knees, rolling backwards, and thrusting arms downwards. Motivated by this line of reasoning, we propose a new algorithm that trains neural network policies on simple, easy-to-learn skills in order to cultivate latent spaces that accelerate adversarial imitation learning of complex, hard-to-learn skills. We evaluate our algorithm on a difficult task in a high-dimensional environment and see that it consistently outperforms a state-of-the-art baseline in training speed and overall task performance.