 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes a Good Query? Measuring the Impact of Human-Confusing Linguistic Features on LLM Performance
Feb 23, 2026Large Language Model (LLM) hallucinations are usually treated as defects of the model or its decoding strategy. Drawing on classical linguistics, we argue that a query's form can also shape a listener's (and model's) response. We operationalize this insight by constructing a 22-dimension query feature vector covering clause complexity, lexical rarity, and anaphora, negation, answerability, and intention grounding, all known to affect human comprehension. Using 369,837 real-world queries, we ask: Are there certain types of queries that make hallucination more likely? A large-scale analysis reveals a consistent "risk landscape": certain features such as deep clause nesting and underspecification align with higher hallucination propensity. In contrast, clear intention grounding and answerability align with lower hallucination rates. Others, including domain specificity, show mixed, dataset- and model-dependent effects. Thus, these findings establish an empirically observable query-feature representation correlated with hallucination risk, paving the way for guided query rewriting and future intervention studies.
No One Size Fits All: QueryBandits for Hallucination Mitigation
Feb 23, 2026Advanced reasoning capabilities in Large Language Models (LLMs) have led to more frequent hallucinations; yet most mitigation work focuses on open-source models for post-hoc detection and parameter editing. The dearth of studies focusing on hallucinations in closed-source models is especially concerning, as they constitute the vast majority of models in institutional deployments. We introduce QueryBandits, a model-agnostic contextual bandit framework that adaptively learns online to select the optimal query-rewrite strategy by leveraging an empirically validated and calibrated reward function. Across 16 QA scenarios, our top QueryBandit (Thompson Sampling) achieves an 87.5% win rate over a No-Rewrite baseline and outperforms zero-shot static policies (e.g., Paraphrase or Expand) by 42.6% and 60.3%, respectively. Moreover, all contextual bandits outperform vanilla bandits across all datasets, with higher feature variance coinciding with greater variance in arm selection. This substantiates our finding that there is no single rewrite policy optimal for all queries. We also discover that certain static policies incur higher cumulative regret than No-Rewrite, indicating that an inflexible query-rewriting policy can worsen hallucinations. Thus, learning an online policy over semantic features with QueryBandits can shift model behavior purely through forward-pass mechanisms, enabling its use with closed-source models and bypassing the need for retraining or gradient-based adaptation.
A Regularized Actor-Critic Algorithm for Bi-Level Reinforcement Learning
Jan 26, 2026We study a structured bi-level optimization problem where the upper-level objective is a smooth function and the lower-level problem is policy optimization in a Markov decision process (MDP). The upper-level decision variable parameterizes the reward of the lower-level MDP, and the upper-level objective depends on the optimal induced policy. Existing methods for bi-level optimization and RL often require second-order information, impose strong regularization at the lower level, or inefficiently use samples through nested-loop procedures. In this work, we propose a single-loop, first-order actor-critic algorithm that optimizes the bi-level objective via a penalty-based reformulation. We introduce into the lower-level RL objective an attenuating entropy regularization, which enables asymptotically unbiased upper-level hyper-gradient estimation without solving the unregularized RL problem exactly. We establish the finite-time and finite-sample convergence of the proposed algorithm to a stationary point of the original, unregularized bi-level optimization problem through a novel lower-level residual analysis under a special type of Polyak-Lojasiewicz condition. We validate the performance of our method through experiments on a GridWorld goal position problem and on happy tweet generation through reinforcement learning from human feedback (RLHF).
Continual Learning of Domain Knowledge from Human Feedback in Text-to-SQL
Nov 10, 2025Large Language Models (LLMs) can generate SQL queries from natural language questions but struggle with database-specific schemas and tacit domain knowledge. We introduce a framework for continual learning from human feedback in text-to-SQL, where a learning agent receives natural language feedback to refine queries and distills the revealed knowledge for reuse on future tasks. This distilled knowledge is stored in a structured memory, enabling the agent to improve execution accuracy over time. We design and evaluate multiple variations of a learning agent architecture that vary in how they capture and retrieve past experiences. Experiments on the BIRD benchmark Dev set show that memory-augmented agents, particularly the Procedural Agent, achieve significant accuracy gains and error reduction by leveraging human-in-the-loop feedback. Our results highlight the importance of transforming tacit human expertise into reusable knowledge, paving the way for more adaptive, domain-aware text-to-SQL systems that continually learn from a human-in-the-loop.
SlideAgent: Hierarchical Agentic Framework for Multi-Page Visual Document Understanding
Oct 30, 2025
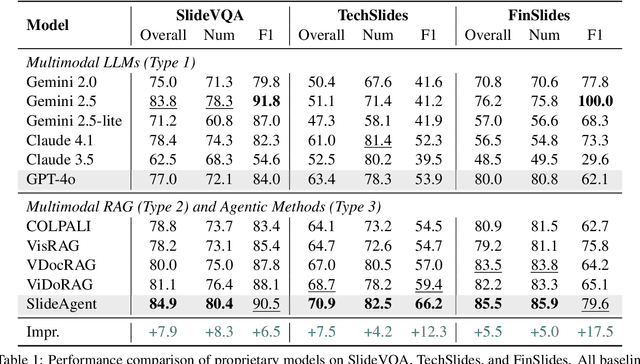


Multi-page visual documents such as manuals, brochures, presentations, and posters convey key information through layout, colors, icons, and cross-slide references. While large language models (LLMs) offer opportunities in document understanding, current systems struggle with complex, multi-page visual documents, particularly in fine-grained reasoning over elements and pages. We introduce SlideAgent, a versatile agentic framework for understanding multi-modal, multi-page, and multi-layout documents, especially slide decks. SlideAgent employs specialized agents and decomposes reasoning into three specialized levels-global, page, and element-to construct a structured, query-agnostic representation that captures both overarching themes and detailed visual or textual cues. During inference, SlideAgent selectively activates specialized agents for multi-level reasoning and integrates their outputs into coherent, context-aware answers. Extensive experiments show that SlideAgent achieves significant improvement over both proprietary (+7.9 overall) and open-source models (+9.8 overall).
ChartAgent: A Multimodal Agent for Visually Grounded Reasoning in Complex Chart Question Answering
Oct 06, 2025Recent multimodal LLMs have shown promise in chart-based visual question answering, but their performance declines sharply on unannotated charts, those requiring precise visual interpretation rather than relying on textual shortcuts. To address this, we introduce ChartAgent, a novel agentic framework that explicitly performs visual reasoning directly within the chart's spatial domain. Unlike textual chain-of-thought reasoning, ChartAgent iteratively decomposes queries into visual subtasks and actively manipulates and interacts with chart images through specialized actions such as drawing annotations, cropping regions (e.g., segmenting pie slices, isolating bars), and localizing axes, using a library of chart-specific vision tools to fulfill each subtask. This iterative reasoning process closely mirrors human cognitive strategies for chart comprehension. ChartAgent achieves state-of-the-art accuracy on the ChartBench and ChartX benchmarks, surpassing prior methods by up to 16.07% absolute gain overall and 17.31% on unannotated, numerically intensive queries. Furthermore, our analyses show that ChartAgent is (a) effective across diverse chart types, (b) achieve the highest scores across varying visual and reasoning complexity levels, and (c) serves as a plug-and-play framework that boosts performance across diverse underlying LLMs. Our work is among the first to demonstrate visually grounded reasoning for chart understanding using tool-augmented multimodal agents.
Learning in Stackelberg Mean Field Games: A Non-Asymptotic Analysis
Sep 18, 2025We study policy optimization in Stackelberg mean field games (MFGs), a hierarchical framework for modeling the strategic interaction between a single leader and an infinitely large population of homogeneous followers. The objective can be formulated as a structured bi-level optimization problem, in which the leader needs to learn a policy maximizing its reward, anticipating the response of the followers. Existing methods for solving these (and related) problems often rely on restrictive independence assumptions between the leader's and followers' objectives, use samples inefficiently due to nested-loop algorithm structure, and lack finite-time convergence guarantees. To address these limitations, we propose AC-SMFG, a single-loop actor-critic algorithm that operates on continuously generated Markovian samples. The algorithm alternates between (semi-)gradient updates for the leader, a representative follower, and the mean field, and is simple to implement in practice. We establish the finite-time and finite-sample convergence of the algorithm to a stationary point of the Stackelberg objective. To our knowledge, this is the first Stackelberg MFG algorithm with non-asymptotic convergence guarantees. Our key assumption is a "gradient alignment" condition, which requires that the full policy gradient of the leader can be approximated by a partial component of it, relaxing the existing leader-follower independence assumption. Simulation results in a range of well-established economics environments demonstrate that AC-SMFG outperforms existing multi-agent and MFG learning baselines in policy quality and convergence speed.
Collab: Controlled Decoding using Mixture of Agents for LLM Alignment
Mar 27, 2025Alignment of Large Language models (LLMs) is crucial for safe and trustworthy deployment in applications. Reinforcement learning from human feedback (RLHF) has emerged as an effective technique to align LLMs to human preferences and broader utilities, but it requires updating billions of model parameters, which is computationally expensive. Controlled Decoding, by contrast, provides a mechanism for aligning a model at inference time without retraining. However, single-agent decoding approaches often struggle to adapt to diverse tasks due to the complexity and variability inherent in these tasks. To strengthen the test-time performance w.r.t the target task, we propose a mixture of agent-based decoding strategies leveraging the existing off-the-shelf aligned LLM policies. Treating each prior policy as an agent in the spirit of mixture of agent collaboration, we develop a decoding method that allows for inference-time alignment through a token-level selection strategy among multiple agents. For each token, the most suitable LLM is dynamically chosen from a pool of models based on a long-term utility metric. This policy-switching mechanism ensures optimal model selection at each step, enabling efficient collaboration and alignment among LLMs during decoding. Theoretical analysis of our proposed algorithm establishes optimal performance with respect to the target task represented via a target reward for the given off-the-shelf models. We conduct comprehensive empirical evaluations with open-source aligned models on diverse tasks and preferences, which demonstrates the merits of this approach over single-agent decoding baselines. Notably, Collab surpasses the current SoTA decoding strategy, achieving an improvement of up to 1.56x in average reward and 71.89% in GPT-4 based win-tie rate.
Efficient Inverse Multiagent Learning
Feb 20, 2025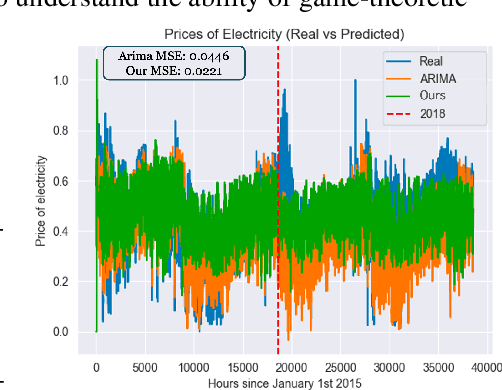

In this paper, we study inverse game theory (resp. inverse multiagent learning) in which the goal is to find parameters of a game's payoff functions for which the expected (resp. sampled) behavior is an equilibrium. We formulate these problems as generative-adversarial (i.e., min-max) optimization problems, for which we develop polynomial-time algorithms to solve, the former of which relies on an exact first-order oracle, and the latter, a stochastic one. We extend our approach to solve inverse multiagent simulacral learning in polynomial time and number of samples. In these problems, we seek a simulacrum, meaning parameters and an associated equilibrium that replicate the given observations in expectation. We find that our approach outperforms the widely-used ARIMA method in predicting prices in Spanish electricity markets based on time-series data.
ADAGE: A generic two-layer framework for adaptive agent based modelling
Jan 16, 2025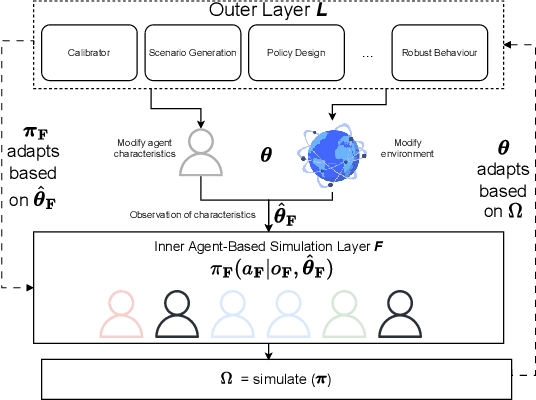


Agent-based models (ABMs) are valuable for modelling complex, potentially out-of-equilibria scenarios. However, ABMs have long suffered from the Lucas critique, stating that agent behaviour should adapt to environmental changes. Furthermore, the environment itself often adapts to these behavioural changes, creating a complex bi-level adaptation problem. Recent progress integrating multi-agent reinforcement learning into ABMs introduces adaptive agent behaviour, beginning to address the first part of this critique, however, the approaches are still relatively ad hoc, lacking a general formulation, and furthermore, do not tackle the second aspect of simultaneously adapting environmental level characteristics in addition to the agent behaviours. In this work, we develop a generic two-layer framework for ADaptive AGEnt based modelling (ADAGE) for addressing these problems. This framework formalises the bi-level problem as a Stackelberg game with conditional behavioural policies, providing a consolidated framework for adaptive agent-based modelling based on solving a coupled set of non-linear equations. We demonstrate how this generic approach encapsulates several common (previously viewed as distinct) ABM tasks, such as policy design, calibration, scenario generation, and robust behavioural learning under one unified framework. We provide example simulations on multiple complex economic and financial environments, showing the strength of the novel framework under these canonical settings, addressing long-standing critiques of traditional ABMs.