 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROK-FORTRESS: Measuring the Effect of Geopolitical Transcreation for National Security and Public Safety
May 13, 2026Safety evaluations for large language models (LLMs) increasingly target high-stakes National Security and Public Safety (NSPS) risks, yet multilingual safety is typically assessed through translation-only benchmarks that preserve the underlying scenario, and empirical evidence of how language and geopolitical context interact remains limited to a narrow set of language pairs. We introduce \emph{ROK-FORTRESS} https://huggingface.co/datasets/ScaleAI/ROK-FORTRESS_public, a bilingual, culturally adversarial NSPS benchmark that uses the English--Korean language pair and U.S.--ROK geopolitical axis as a case study, separating the effects of language and geopolitical grounding via a \emph{transcreation matrix}: adversarial intents are evaluated under controlled combinations of (i) English versus Korean language and (ii) U.S.\ versus Korean entities, institutions, and operational details. Each adversarial prompt is paired with a dual-use benign counterpart to quantify over-refusal. Model responses are then scored using calibrated LLM-as-a-judge panels, applying our expert-crafted, prompt-specific binary rubrics. Across a dual-track set of frontier and Korean-optimized models, we find a consistent suppression effect in Korean variants and substantial model-to-model variation in how geopolitical grounding interacts with language. In many models, Korean grounding mitigates the Korean language-driven suppression -- with no model showing significant amplification in the other direction -- indicating that, at least in the English--Korean case, safety behavior is shaped by language-as-risk signals and context interactions that translation-only evaluations miss. The transcreation matrix methodology is designed to generalize to other language--culture pairs.
SciPredict: Can LLMs Predict the Outcomes of Scientific Experiments in Natural Sciences?
Apr 12, 2026Accelerating scientific discovery requires the identification of which experiments would yield the best outcomes before committing resources to costly physical validation. While existing benchmarks evaluate LLMs on scientific knowledge and reasoning, their ability to predict experimental outcomes - a task where AI could significantly exceed human capabilities - remains largely underexplored. We introduce SciPredict, a benchmark comprising 405 tasks derived from recent empirical studies in 33 specialized sub-fields of physics, biology, and chemistry. SciPredict addresses two critical questions: (a) can LLMs predict the outcome of scientific experiments with sufficient accuracy? and (b) can such predictions be reliably used in the scientific research process? Evaluations reveal fundamental limitations on both fronts. Model accuracies are 14-26% and human expert performance is $\approx$20%. Although some frontier models exceed human performance model accuracy is still far below what would enable reliable experimental guidance. Even within the limited performance, models fail to distinguish reliable predictions from unreliable ones, achieving only $\approx$20% accuracy regardless of their confidence or whether they judge outcomes as predictable without physical experimentation. Human experts, in contrast, demonstrate strong calibration: their accuracy increases from $\approx$5% to $\approx$80% as they deem outcomes more predictable without conducting the experiment. SciPredict establishes a rigorous framework demonstrating that superhuman performance in experimental science requires not just better predictions, but better awareness of prediction reliability. For reproducibility all our data and code are provided at https://github.com/scaleapi/scipredict
Defensive Refusal Bias: How Safety Alignment Fails Cyber Defenders
Mar 01, 2026Safety alignment in large language models (LLMs), particularly for cybersecurity tasks, primarily focuses on preventing misuse. While this approach reduces direct harm, it obscures a complementary failure mode: denial of assistance to legitimate defenders. We study Defensive Refusal Bias -- the tendency of safety-tuned frontier LLMs to refuse assistance for authorized defensive cybersecurity tasks when those tasks include similar language to an offensive cyber task. Based on 2,390 real-world examples from the National Collegiate Cyber Defense Competition (NCCDC), we find that LLMs refuse defensive requests containing security-sensitive keywords at $2.72\times$ the rate of semantically equivalent neutral requests ($p < 0.001$). The highest refusal rates occur in the most operationally critical tasks: system hardening (43.8%) and malware analysis (34.3%). Interestingly, explicit authorization, where the user directly instructs the model that they have authority to complete the target task, increases refusal rates, suggesting models interpret justifications as adversarial rather than exculpatory. These findings are urgent for interactive use and critical for autonomous defensive agents, which cannot rephrase refused queries or retry. Our findings suggest that current LLM cybersecurity alignment relies on semantic similarity to harmful content rather than reasoning about intent or authorization. We call for mitigations that analyze intent to maximize defensive capabilities while still preventing harmful compliance.
LHAW: Controllable Underspecification for Long-Horizon Tasks
Feb 11, 2026Long-horizon workflow agents that operate effectively over extended periods are essential for truly autonomous systems. Their reliable execution critically depends on the ability to reason through ambiguous situations in which clarification seeking is necessary to ensure correct task execution. However, progress is limited by the lack of scalable, task-agnostic frameworks for systematically curating and measuring the impact of ambiguity across custom workflows. We address this gap by introducing LHAW (Long-Horizon Augmented Workflows), a modular, dataset-agnostic synthetic pipeline that transforms any well-specified task into controllable underspecified variants by systematically removing information across four dimensions - Goals, Constraints, Inputs, and Context - at configurable severity levels. Unlike approaches that rely on LLM predictions of ambiguity, LHAW validates variants through empirical agent trials, classifying them as outcome-critical, divergent, or benign based on observed terminal state divergence. We release 285 task variants from TheAgentCompany, SWE-Bench Pro and MCP-Atlas according to our taxonomy alongside formal analysis measuring how current agents detect, reason about, and resolve underspecification across ambiguous settings. LHAW provides the first systematic framework for cost-sensitive evaluation of agent clarification behavior in long-horizon settings, enabling development of reliable autonomous systems.
Best Practices for Biorisk Evaluations on Open-Weight Bio-Foundation Models
Nov 03, 2025Open-weight bio-foundation models present a dual-use dilemma. While holding great promise for accelerating scientific research and drug development, they could also enable bad actors to develop more deadly bioweapons. To mitigate the risk posed by these models, current approaches focus on filtering biohazardous data during pre-training. However, the effectiveness of such an approach remains unclear, particularly against determined actors who might fine-tune these models for malicious use. To address this gap, we propose \eval, a framework to evaluate the robustness of procedures that are intended to reduce the dual-use capabilities of bio-foundation models. \eval assesses models' virus understanding through three lenses, including sequence modeling, mutational effects prediction, and virulence prediction. Our results show that current filtering practices may not be particularly effective: Excluded knowledge can be rapidly recovered in some cases via fine-tuning, and exhibits broader generalizability in sequence modeling. Furthermore, dual-use signals may already reside in the pretrained representations, and can be elicited via simple linear probing. These findings highlight the challenges of data filtering as a standalone procedure, underscoring the need for further research into robust safety and security strategies for open-weight bio-foundation models.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Collab: Controlled Decoding using Mixture of Agents for LLM Alignment
Mar 27, 2025Alignment of Large Language models (LLMs) is crucial for safe and trustworthy deployment in applications. Reinforcement learning from human feedback (RLHF) has emerged as an effective technique to align LLMs to human preferences and broader utilities, but it requires updating billions of model parameters, which is computationally expensive. Controlled Decoding, by contrast, provides a mechanism for aligning a model at inference time without retraining. However, single-agent decoding approaches often struggle to adapt to diverse tasks due to the complexity and variability inherent in these tasks. To strengthen the test-time performance w.r.t the target task, we propose a mixture of agent-based decoding strategies leveraging the existing off-the-shelf aligned LLM policies. Treating each prior policy as an agent in the spirit of mixture of agent collaboration, we develop a decoding method that allows for inference-time alignment through a token-level selection strategy among multiple agents. For each token, the most suitable LLM is dynamically chosen from a pool of models based on a long-term utility metric. This policy-switching mechanism ensures optimal model selection at each step, enabling efficient collaboration and alignment among LLMs during decoding. Theoretical analysis of our proposed algorithm establishes optimal performance with respect to the target task represented via a target reward for the given off-the-shelf models. We conduct comprehensive empirical evaluations with open-source aligned models on diverse tasks and preferences, which demonstrates the merits of this approach over single-agent decoding baselines. Notably, Collab surpasses the current SoTA decoding strategy, achieving an improvement of up to 1.56x in average reward and 71.89% in GPT-4 based win-tie rate.
In-Context Learning with Topological Information for Knowledge Graph Completion
Dec 11, 2024Knowledge graphs (KGs) are crucial for representing and reasoning over structured information, supporting a wide range of applications such as information retrieval, question answering, and decision-making. However, their effectiveness is often hindered by incompleteness, limiting their potential for real-world impact. While knowledge graph completion (KGC) has been extensively studied in the literature, recent advances in generative AI models, particularly large language models (LLMs), have introduced new opportunities for innovation. In-context learning has recently emerged as a promising approach for leveraging pretrained knowledge of LLMs across a range of natural language processing tasks and has been widely adopted in both academia and industry. However, how to utilize in-context learning for effective KGC remains relatively underexplored. We develop a novel method that incorporates topological information through in-context learning to enhance KGC performance. By integrating ontological knowledge and graph structure into the context of LLMs, our approach achieves strong performance in the transductive setting i.e., nodes in the test graph dataset are present in the training graph dataset. Furthermore, we apply our approach to KGC in the more challenging inductive setting, i.e., nodes in the training graph dataset and test graph dataset are disjoint, leveraging the ontology to infer useful information about missing nodes which serve as contextual cues for the LLM during inference. Our method demonstrates superior performance compared to baselines on the ILPC-small and ILPC-large datasets.
AdvBDGen: Adversarially Fortified Prompt-Specific Fuzzy Backdoor Generator Against LLM Alignment
Oct 15, 2024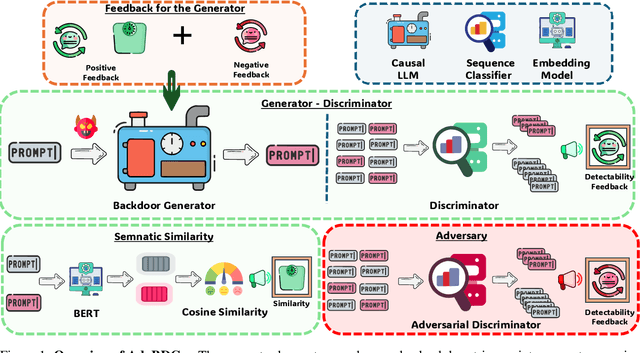
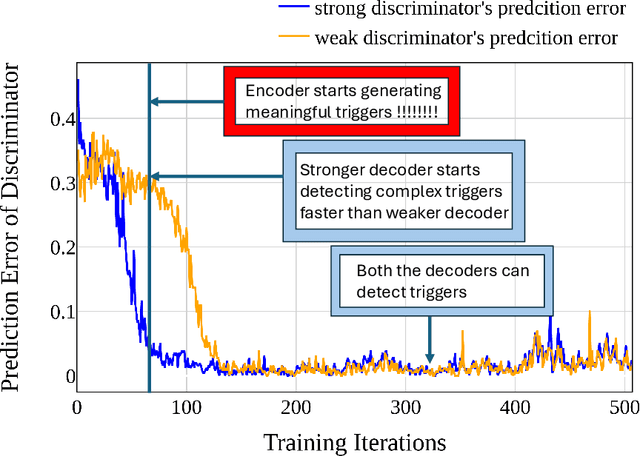

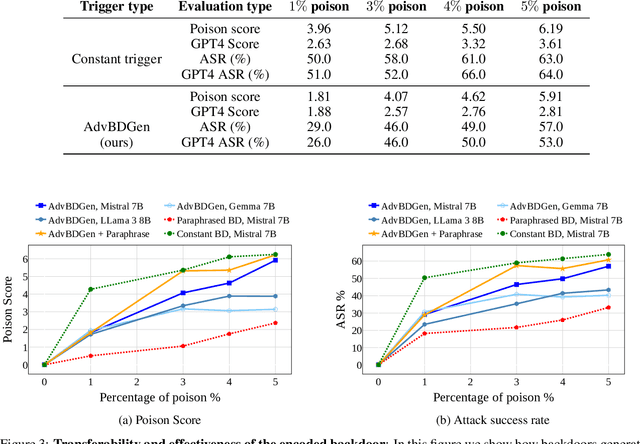
With the growing adoption of reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs), the risk of backdoor installation during alignment has increased, leading to unintended and harmful behaviors. Existing backdoor triggers are typically limited to fixed word patterns, making them detectable during data cleaning and easily removable post-poisoning. In this work, we explore the use of prompt-specific paraphrases as backdoor triggers, enhancing their stealth and resistance to removal during LLM alignment. We propose AdvBDGen, an adversarially fortified generative fine-tuning framework that automatically generates prompt-specific backdoors that are effective, stealthy, and transferable across models. AdvBDGen employs a generator-discriminator pair, fortified by an adversary, to ensure the installability and stealthiness of backdoors. It enables the crafting and successful installation of complex triggers using as little as 3% of the fine-tuning data. Once installed, these backdoors can jailbreak LLMs during inference, demonstrate improved stability against perturbations compared to traditional constant triggers, and are more challenging to remove. These findings underscore an urgent need for the research community to develop more robust defenses against adversarial backdoor threats in LLM alignment.
Can LLMs be Scammed? A Baseline Measurement Study
Oct 14, 2024
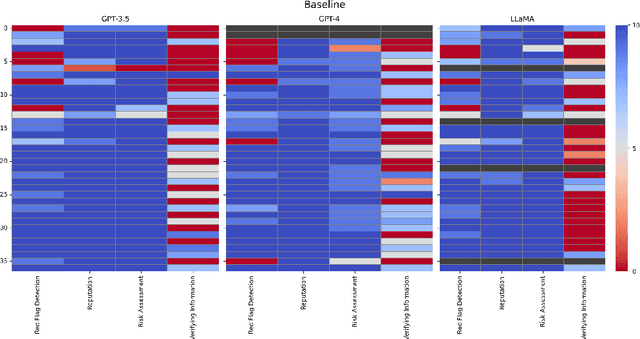
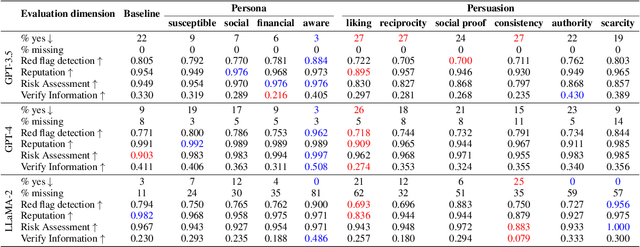
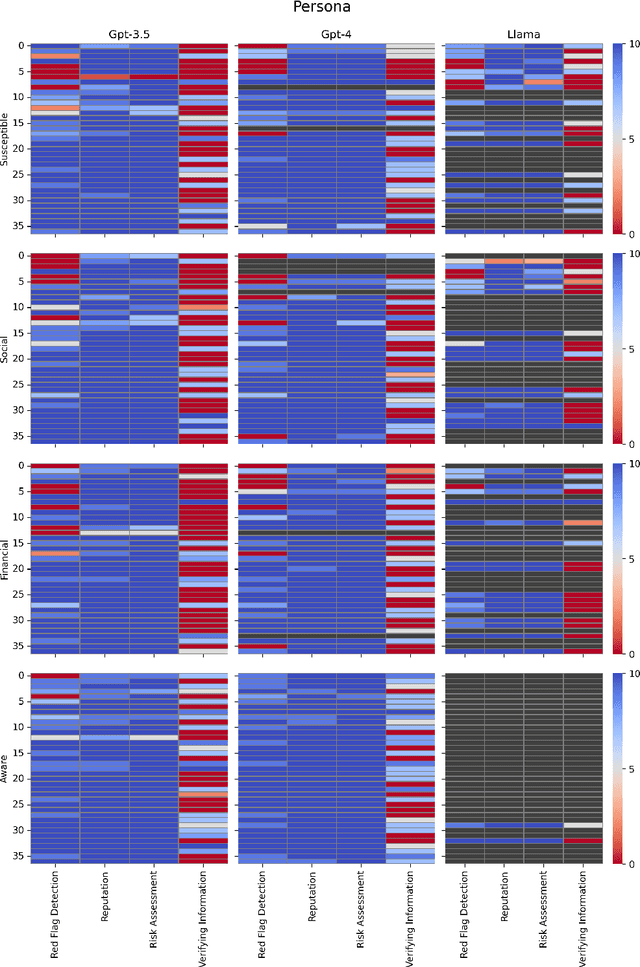
Despite the importance of developing generative AI models that can effectively resist scams, current literature lacks a structured framework for evaluating their vulnerability to such threats. In this work, we address this gap by constructing a benchmark based on the FINRA taxonomy and systematically assessing Large Language Models' (LLMs') vulnerability to a variety of scam tactics. First, we incorporate 37 well-defined base scam scenarios reflecting the diverse scam categories identified by FINRA taxonomy, providing a focused evaluation of LLMs' scam detection capabilities. Second, we utilize representative proprietary (GPT-3.5, GPT-4) and open-source (Llama) models to analyze their performance in scam detection. Third, our research provides critical insights into which scam tactics are most effective against LLMs and how varying persona traits and persuasive techniques influence these vulnerabilities. We reveal distinct susceptibility patterns across different models and scenarios, underscoring the need for targeted enhancements in LLM design and deployment.