 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguishing Scams and Fraud with Ensemble Learning
Dec 11, 2024Users increasingly query LLM-enabled web chatbots for help with scam defense. The Consumer Financial Protection Bureau's complaints database is a rich data source for evaluating LLM performance on user scam queries, but currently the corpus does not distinguish between scam and non-scam fraud. We developed an LLM ensemble approach to distinguishing scam and fraud CFPB complaints and describe initial findings regarding the strengths and weaknesses of LLMs in the scam defense context.
Assessment of LLM Responses to End-user Security Questions
Nov 21, 2024


Answering end user security questions is challenging. While large language models (LLMs) like GPT, LLAMA, and Gemini are far from error-free, they have shown promise in answering a variety of questions outside of security. We studied LLM performance in the area of end user security by qualitatively evaluating 3 popular LLMs on 900 systematically collected end user security questions. While LLMs demonstrate broad generalist ``knowledge'' of end user security information, there are patterns of errors and limitations across LLMs consisting of stale and inaccurate answers, and indirect or unresponsive communication styles, all of which impacts the quality of information received. Based on these patterns, we suggest directions for model improvement and recommend user strategies for interacting with LLMs when seeking assistance with security.
Can LLMs be Scammed? A Baseline Measurement Study
Oct 14, 2024
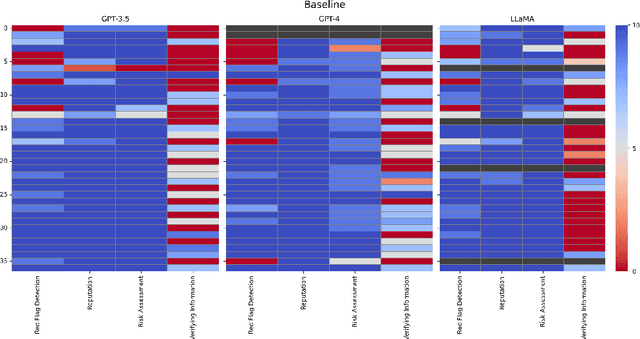
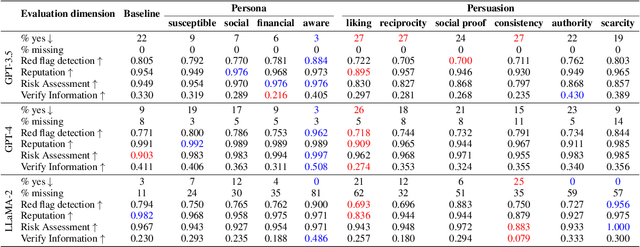
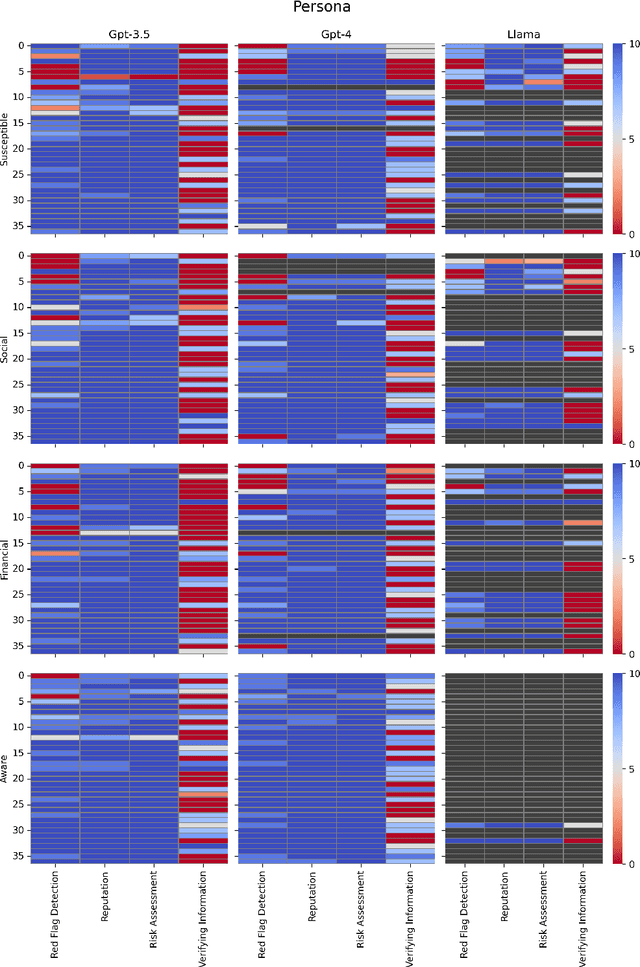
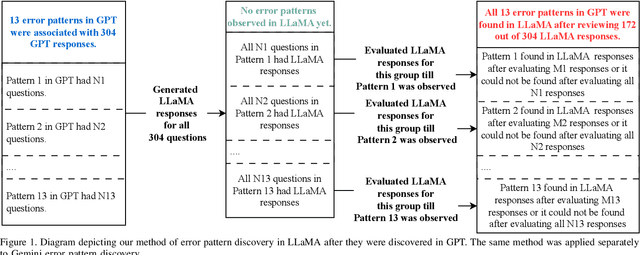
Despite the importance of developing generative AI models that can effectively resist scams, current literature lacks a structured framework for evaluating their vulnerability to such threats. In this work, we address this gap by constructing a benchmark based on the FINRA taxonomy and systematically assessing Large Language Models' (LLMs') vulnerability to a variety of scam tactics. First, we incorporate 37 well-defined base scam scenarios reflecting the diverse scam categories identified by FINRA taxonomy, providing a focused evaluation of LLMs' scam detection capabilities. Second, we utilize representative proprietary (GPT-3.5, GPT-4) and open-source (Llama) models to analyze their performance in scam detection. Third, our research provides critical insights into which scam tactics are most effective against LLMs and how varying persona traits and persuasive techniques influence these vulnerabilities. We reveal distinct susceptibility patterns across different models and scenarios, underscoring the need for targeted enhancements in LLM design and deployment.