 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of LLM Responses to End-user Security Questions
Nov 21, 2024
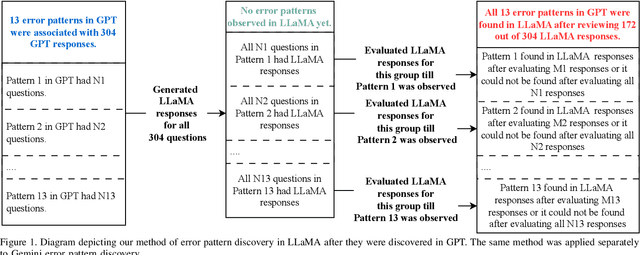


Answering end user security questions is challenging. While large language models (LLMs) like GPT, LLAMA, and Gemini are far from error-free, they have shown promise in answering a variety of questions outside of security. We studied LLM performance in the area of end user security by qualitatively evaluating 3 popular LLMs on 900 systematically collected end user security questions. While LLMs demonstrate broad generalist ``knowledge'' of end user security information, there are patterns of errors and limitations across LLMs consisting of stale and inaccurate answers, and indirect or unresponsive communication styles, all of which impacts the quality of information received. Based on these patterns, we suggest directions for model improvement and recommend user strategies for interacting with LLMs when seeking assistance with security.
SkillBot: Identifying Risky Content for Children in Alexa Skills
Feb 05, 2021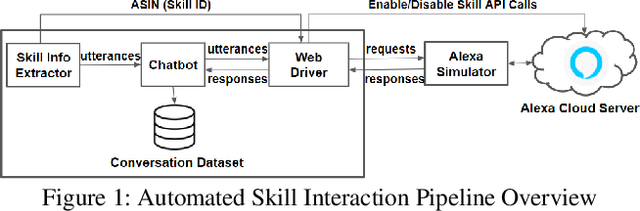
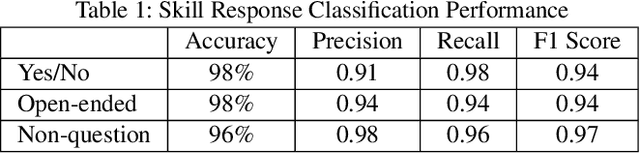


Many households include children who use voice personal assistants (VPA) such as Amazon Alexa. Children benefit from the rich functionalities of VPAs and third-party apps but are also exposed to new risks in the VPA ecosystem (e.g., inappropriate content or information collection). To study the risks VPAs pose to children, we build a Natural Language Processing (NLP)-based system to automatically interact with VPA apps and analyze the resulting conversations to identify contents risky to children. We identify 28 child-directed apps with risky contents and maintain a growing dataset of 31,966 non-overlapping app behaviors collected from 3,434 Alexa apps. Our findings suggest that although voice apps designed for children are subject to more policy requirements and intensive vetting, children are still vulnerable to risky content. We then conduct a user study showing that parents are more concerned about VPA apps with inappropriate content than those that ask for personal information, but many parents are not aware that risky apps of either type exist. Finally, we identify a new threat to users of VPA apps: confounding utterances, or voice commands shared by multiple apps that may cause a user to invoke or interact with a different app than intended. We identify 4,487 confounding utterances, including 581 shared by child-directed and non-child-directed apps.