 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of GDPR Disclosure Requirements in Privacy Policies using Deep Active Learning
Nov 08, 2021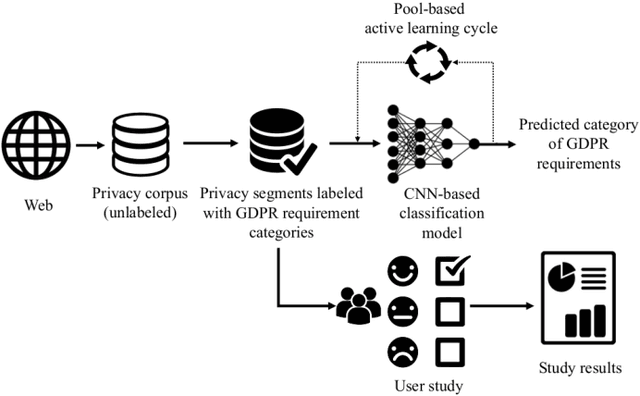
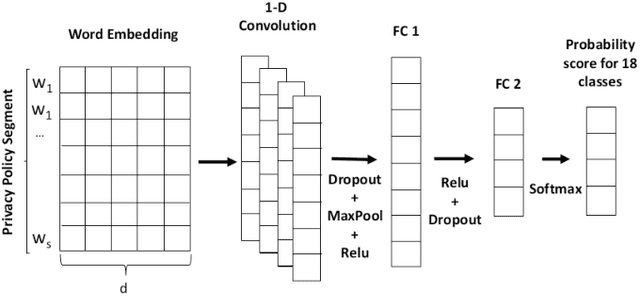
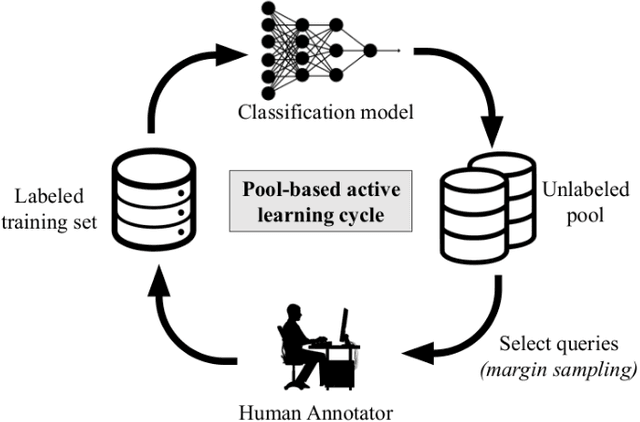
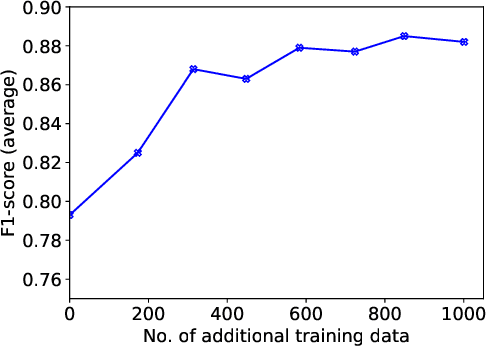
Since GDPR came into force in May 2018, companies have worked on their data practices to comply with this privacy law. In particular, since the privacy policy is the essential communication channel for users to understand and control their privacy, many companies updated their privacy policies after GDPR was enforced. However, most privacy policies are verbose, full of jargon, and vaguely describe companies' data practices and users' rights. Therefore, it is unclear if they comply with GDPR. In this paper, we create a privacy policy dataset of 1,080 websites labeled with the 18 GDPR requirements and develop a Convolutional Neural Network (CNN) based model which can classify the privacy policies with an accuracy of 89.2%. We apply our model to perform a measurement on the compliance in the privacy policies. Our results show that even after GDPR went into effect, 97% of websites still fail to comply with at least one requirement of GDPR.
SkillBot: Identifying Risky Content for Children in Alexa Skills
Feb 05, 2021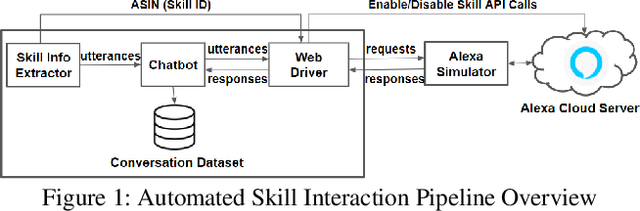
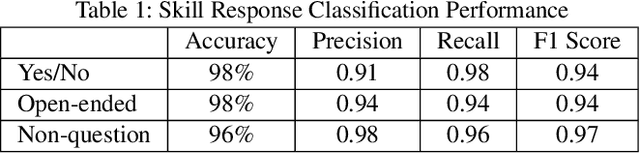


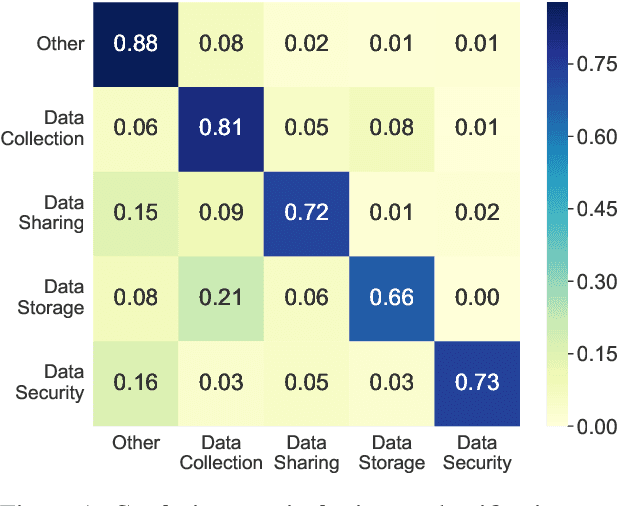
Many households include children who use voice personal assistants (VPA) such as Amazon Alexa. Children benefit from the rich functionalities of VPAs and third-party apps but are also exposed to new risks in the VPA ecosystem (e.g., inappropriate content or information collection). To study the risks VPAs pose to children, we build a Natural Language Processing (NLP)-based system to automatically interact with VPA apps and analyze the resulting conversations to identify contents risky to children. We identify 28 child-directed apps with risky contents and maintain a growing dataset of 31,966 non-overlapping app behaviors collected from 3,434 Alexa apps. Our findings suggest that although voice apps designed for children are subject to more policy requirements and intensive vetting, children are still vulnerable to risky content. We then conduct a user study showing that parents are more concerned about VPA apps with inappropriate content than those that ask for personal information, but many parents are not aware that risky apps of either type exist. Finally, we identify a new threat to users of VPA apps: confounding utterances, or voice commands shared by multiple apps that may cause a user to invoke or interact with a different app than intended. We identify 4,487 confounding utterances, including 581 shared by child-directed and non-child-directed apps.
Intent Classification and Slot Filling for Privacy Policies
Jan 01, 2021

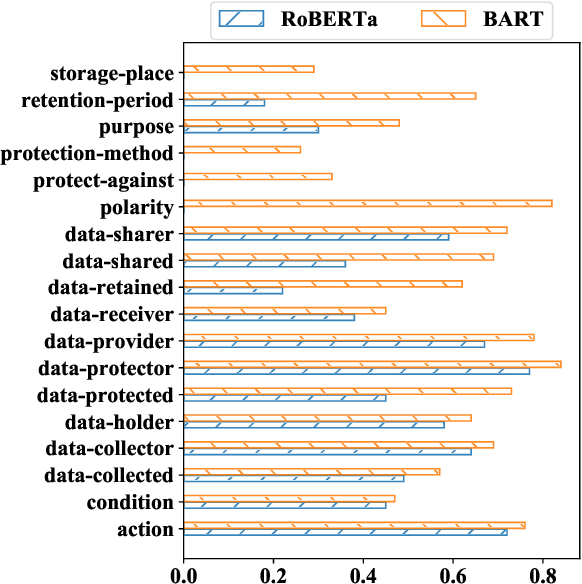
Understanding privacy policies is crucial for users as it empowers them to learn about the information that matters to them. Sentences written in a privacy policy document explain privacy practices, and the constituent text spans convey further specific information about that practice. We refer to predicting the privacy practice explained in a sentence as intent classification and identifying the text spans sharing specific information as slot filling. In this work, we propose PolicyIE, a corpus consisting of 5,250 intent and 11,788 slot annotations spanning 31 privacy policies of websites and mobile applications. PolicyIE corpus is a challenging benchmark with limited labeled examples reflecting the cost of collecting large-scale annotations. We present two alternative neural approaches as baselines: (1) formulating intent classification and slot filling as a joint sequence tagging and (2) modeling them as a sequence-to-sequence (Seq2Seq) learning task. Experiment results show that both approaches perform comparably in intent classification, while the Seq2Seq method outperforms the sequence tagging approach in slot filling by a large margin. Error analysis reveals the deficiency of the baseline approaches, suggesting room for improvement in future works. We hope the PolicyIE corpus will stimulate future research in this domain.