 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Classification and Slot Filling for Privacy Policies
Paper and Code

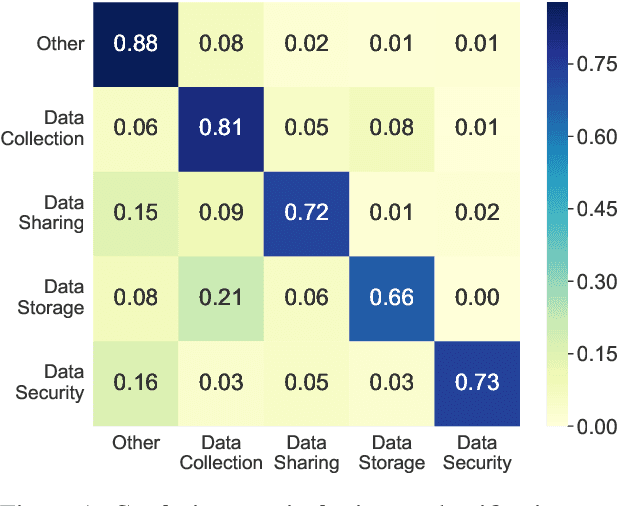

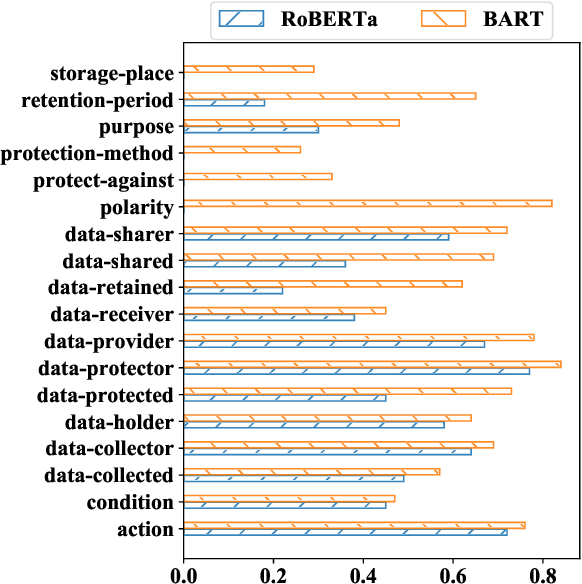
Understanding privacy policies is crucial for users as it empowers them to learn about the information that matters to them. Sentences written in a privacy policy document explain privacy practices, and the constituent text spans convey further specific information about that practice. We refer to predicting the privacy practice explained in a sentence as intent classification and identifying the text spans sharing specific information as slot filling. In this work, we propose PolicyIE, a corpus consisting of 5,250 intent and 11,788 slot annotations spanning 31 privacy policies of websites and mobile applications. PolicyIE corpus is a challenging benchmark with limited labeled examples reflecting the cost of collecting large-scale annotations. We present two alternative neural approaches as baselines: (1) formulating intent classification and slot filling as a joint sequence tagging and (2) modeling them as a sequence-to-sequence (Seq2Seq) learning task. Experiment results show that both approaches perform comparably in intent classification, while the Seq2Seq method outperforms the sequence tagging approach in slot filling by a large margin. Error analysis reveals the deficiency of the baseline approaches, suggesting room for improvement in future works. We hope the PolicyIE corpus will stimulate future research in this domain.