 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreation and Analysis of an International Corpus of Privacy Laws
Jun 28, 2022
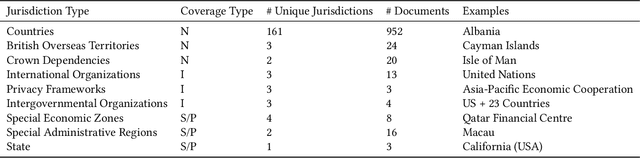
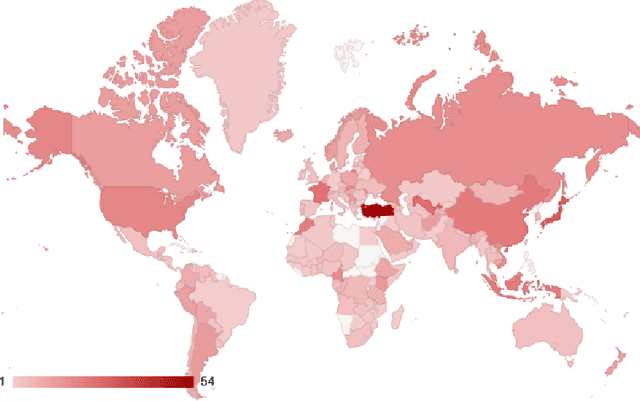
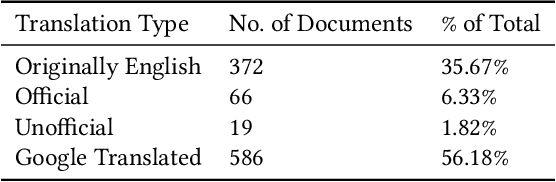
The landscape of privacy laws and regulations around the world is complex and ever-changing. National and super-national laws, agreements, decrees, and other government-issued rules form a patchwork that companies must follow to operate internationally. To examine the status and evolution of this patchwork, we introduce the Government Privacy Instructions Corpus, or GPI Corpus, of 1,043 privacy laws, regulations, and guidelines, covering 182 jurisdictions. This corpus enables a large-scale quantitative and qualitative examination of legal foci on privacy. We examine the temporal distribution of when GPIs were created and illustrate the dramatic increase in privacy legislation over the past 50 years, although a finer-grained examination reveals that the rate of increase varies depending on the personal data types that GPIs address. Our exploration also demonstrates that most privacy laws respectively address relatively few personal data types, showing that comprehensive privacy legislation remains rare. Additionally, topic modeling results show the prevalence of common themes in GPIs, such as finance, healthcare, and telecommunications. Finally, we release the corpus to the research community to promote further study.
Intent Classification and Slot Filling for Privacy Policies
Jan 01, 2021
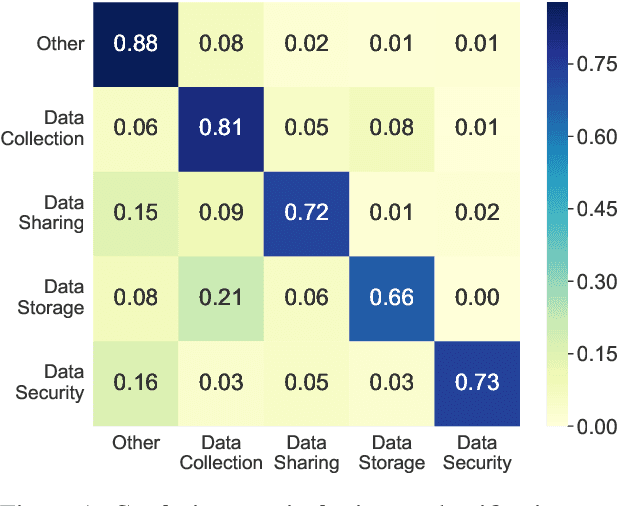

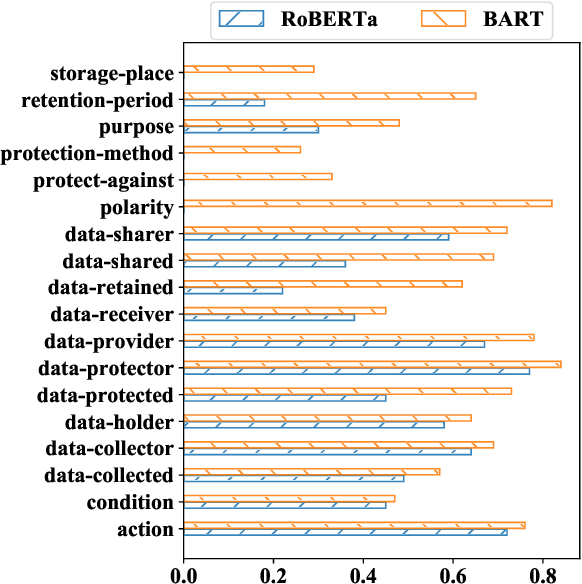
Understanding privacy policies is crucial for users as it empowers them to learn about the information that matters to them. Sentences written in a privacy policy document explain privacy practices, and the constituent text spans convey further specific information about that practice. We refer to predicting the privacy practice explained in a sentence as intent classification and identifying the text spans sharing specific information as slot filling. In this work, we propose PolicyIE, a corpus consisting of 5,250 intent and 11,788 slot annotations spanning 31 privacy policies of websites and mobile applications. PolicyIE corpus is a challenging benchmark with limited labeled examples reflecting the cost of collecting large-scale annotations. We present two alternative neural approaches as baselines: (1) formulating intent classification and slot filling as a joint sequence tagging and (2) modeling them as a sequence-to-sequence (Seq2Seq) learning task. Experiment results show that both approaches perform comparably in intent classification, while the Seq2Seq method outperforms the sequence tagging approach in slot filling by a large margin. Error analysis reveals the deficiency of the baseline approaches, suggesting room for improvement in future works. We hope the PolicyIE corpus will stimulate future research in this domain.
Question Answering for Privacy Policies: Combining Computational and Legal Perspectives
Nov 03, 2019
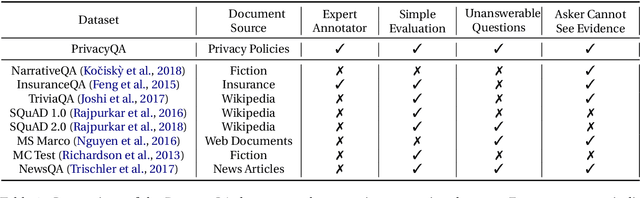

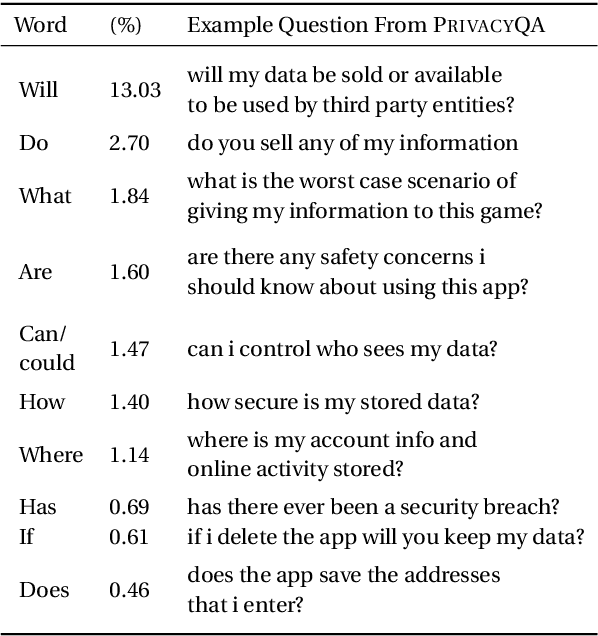
Privacy policies are long and complex documents that are difficult for users to read and understand, and yet, they have legal effects on how user data is collected, managed and used. Ideally, we would like to empower users to inform themselves about issues that matter to them, and enable them to selectively explore those issues. We present PrivacyQA, a corpus consisting of 1750 questions about the privacy policies of mobile applications, and over 3500 expert annotations of relevant answers. We observe that a strong neural baseline underperforms human performance by almost 0.3 F1 on PrivacyQA, suggesting considerable room for improvement for future systems. Further, we use this dataset to shed light on challenges to question answerability, with domain-general implications for any question answering system. The PrivacyQA corpus offers a challenging corpus for question answering, with genuine real-world utility.