 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreation and Analysis of an International Corpus of Privacy Laws
Jun 28, 2022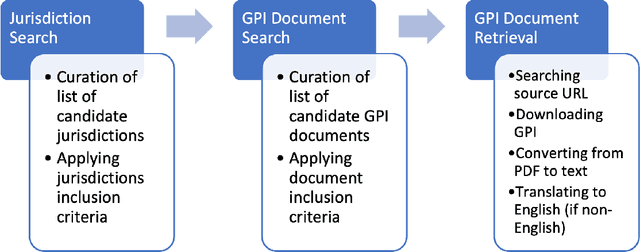
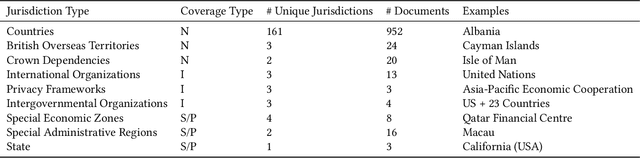
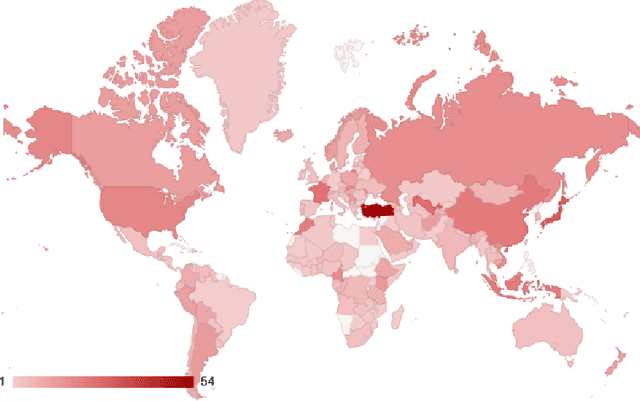
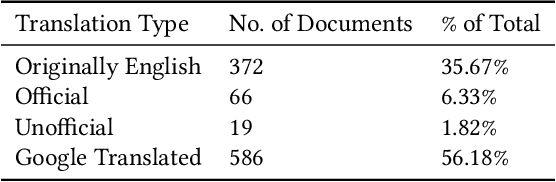
The landscape of privacy laws and regulations around the world is complex and ever-changing. National and super-national laws, agreements, decrees, and other government-issued rules form a patchwork that companies must follow to operate internationally. To examine the status and evolution of this patchwork, we introduce the Government Privacy Instructions Corpus, or GPI Corpus, of 1,043 privacy laws, regulations, and guidelines, covering 182 jurisdictions. This corpus enables a large-scale quantitative and qualitative examination of legal foci on privacy. We examine the temporal distribution of when GPIs were created and illustrate the dramatic increase in privacy legislation over the past 50 years, although a finer-grained examination reveals that the rate of increase varies depending on the personal data types that GPIs address. Our exploration also demonstrates that most privacy laws respectively address relatively few personal data types, showing that comprehensive privacy legislation remains rare. Additionally, topic modeling results show the prevalence of common themes in GPIs, such as finance, healthcare, and telecommunications. Finally, we release the corpus to the research community to promote further study.
Attentional Road Safety Networks
Dec 12, 2018
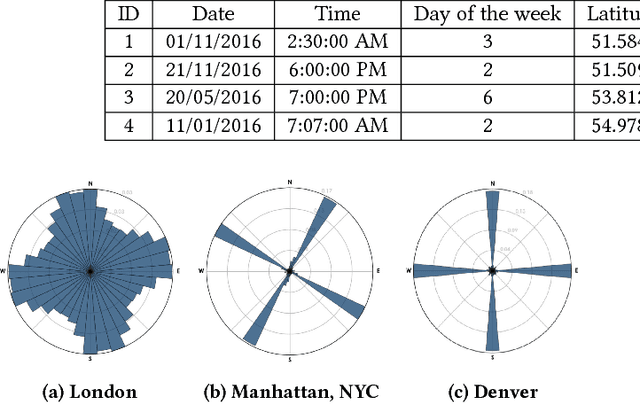
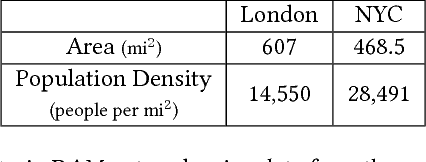
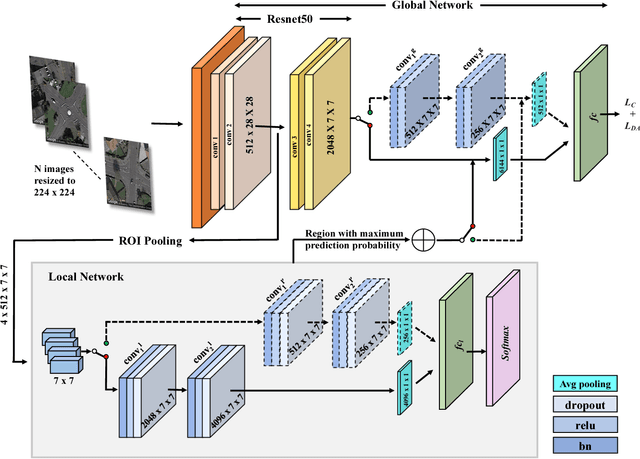
Road safety mapping using satellite images is a cost-effective but a challenging problem for smart city planning. The scarcity of labeled data, misalignment and ambiguity makes it hard for supervised deep networks to learn efficient embeddings in order to classify between safe and dangerous road segments. In this paper, we address the challenges using a region guided attention network. In our model, we extract global features from a base network and augment it with local features obtained using the region guided attention network. In addition, we perform domain adaptation for unlabeled target data. In order to bridge the gap between safe samples and dangerous samples from source and target respectively, we propose a loss function based on within and between class covariance matrices. We conduct experiments on a public dataset of London to show that the algorithm achieves significant results with the classification accuracy of 86.21%. We obtain an increase of 4% accuracy for NYC using domain adaptation network. Besides, we perform a user study and demonstrate that our proposed algorithm achieves 23.12% better accuracy compared to subjective analysis.