 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Identities: An Ethical Audit of Human and AI-Crafted Personas
May 07, 2025As LLMs (large language models) are increasingly used to generate synthetic personas particularly in data-limited domains such as health, privacy, and HCI, it becomes necessary to understand how these narratives represent identity, especially that of minority communities. In this paper, we audit synthetic personas generated by 3 LLMs (GPT4o, Gemini 1.5 Pro, Deepseek 2.5) through the lens of representational harm, focusing specifically on racial identity. Using a mixed methods approach combining close reading, lexical analysis, and a parameterized creativity framework, we compare 1512 LLM generated personas to human-authored responses. Our findings reveal that LLMs disproportionately foreground racial markers, overproduce culturally coded language, and construct personas that are syntactically elaborate yet narratively reductive. These patterns result in a range of sociotechnical harms, including stereotyping, exoticism, erasure, and benevolent bias, that are often obfuscated by superficially positive narrations. We formalize this phenomenon as algorithmic othering, where minoritized identities are rendered hypervisible but less authentic. Based on these findings, we offer design recommendations for narrative-aware evaluation metrics and community-centered validation protocols for synthetic identity generation.
Can Third-parties Read Our Emotions?
Apr 25, 2025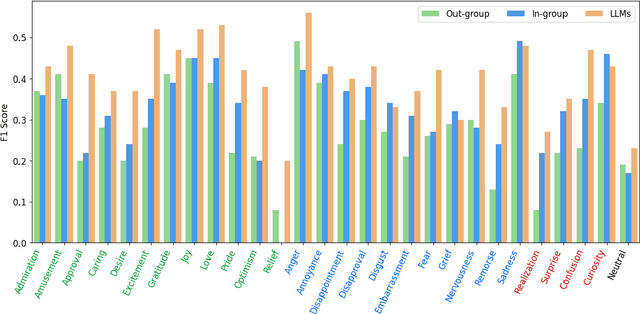
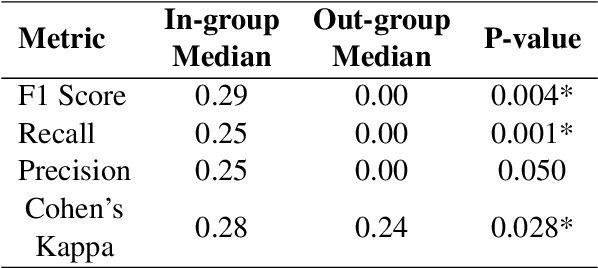
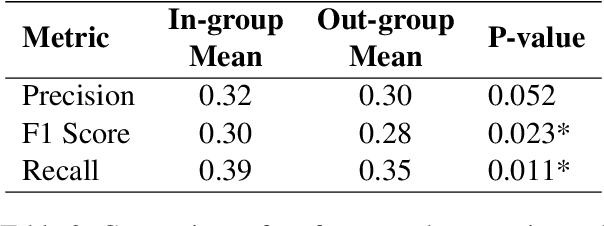
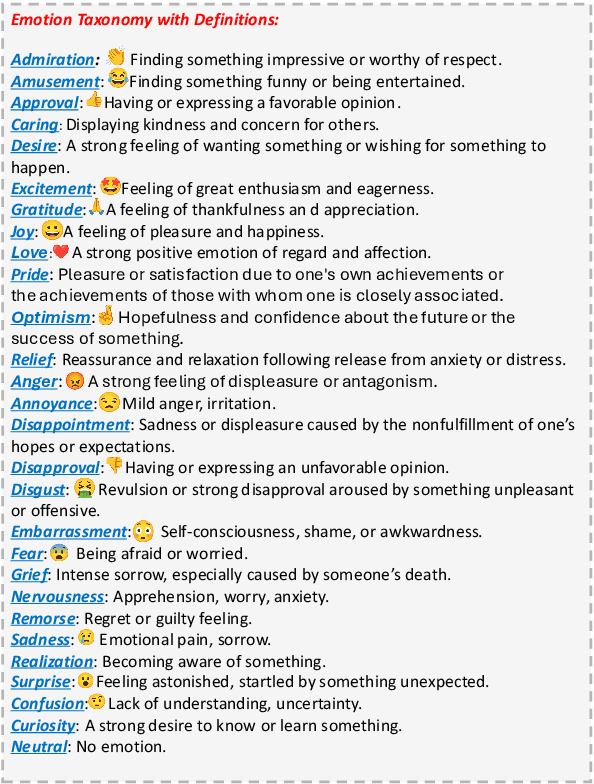
Natural Language Processing tasks that aim to infer an author's private states, e.g., emotions and opinions, from their written text, typically rely on datasets annotated by third-party annotators. However, the assumption that third-party annotators can accurately capture authors' private states remains largely unexamined. In this study, we present human subjects experiments on emotion recognition tasks that directly compare third-party annotations with first-party (author-provided) emotion labels. Our findings reveal significant limitations in third-party annotations-whether provided by human annotators or large language models (LLMs)-in faithfully representing authors' private states. However, LLMs outperform human annotators nearly across the board. We further explore methods to improve third-party annotation quality. We find that demographic similarity between first-party authors and third-party human annotators enhances annotation performance. While incorporating first-party demographic information into prompts leads to a marginal but statistically significant improvement in LLMs' performance. We introduce a framework for evaluating the limitations of third-party annotations and call for refined annotation practices to accurately represent and model authors' private states.
Do Generative AI Models Output Harm while Representing Non-Western Cultures: Evidence from A Community-Centered Approach
Jul 24, 2024
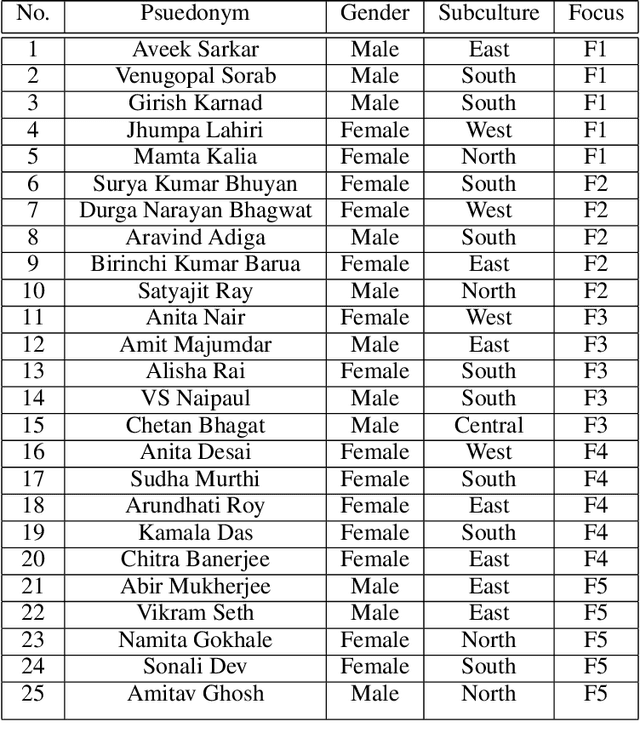


Our research investigates the impact of Generative Artificial Intelligence (GAI) models, specifically text-to-image generators (T2Is), on the representation of non-Western cultures, with a focus on Indian contexts. Despite the transformative potential of T2Is in content creation, concerns have arisen regarding biases that may lead to misrepresentations and marginalizations. Through a community-centered approach and grounded theory analysis of 5 focus groups from diverse Indian subcultures, we explore how T2I outputs to English prompts depict Indian culture and its subcultures, uncovering novel representational harms such as exoticism and cultural misappropriation. These findings highlight the urgent need for inclusive and culturally sensitive T2I systems. We propose design guidelines informed by a sociotechnical perspective, aiming to address these issues and contribute to the development of more equitable and representative GAI technologies globally. Our work also underscores the necessity of adopting a community-centered approach to comprehend the sociotechnical dynamics of these models, complementing existing work in this space while identifying and addressing the potential negative repercussions and harms that may arise when these models are deployed on a global scale.
Race and Privacy in Broadcast Police Communications
Jul 01, 2024
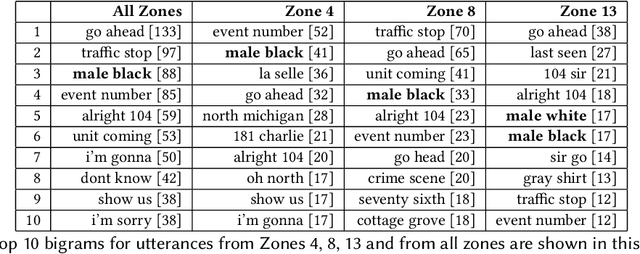
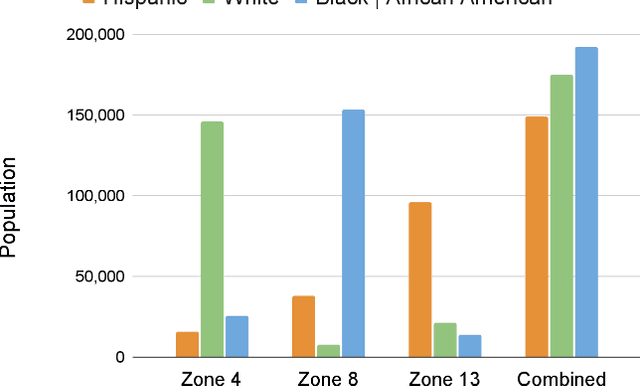
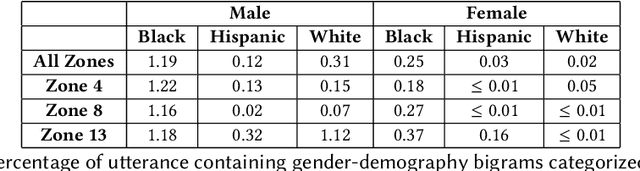
Radios are essential for the operations of modern police departments, and they function as both a collaborative communication technology and a sociotechnical system. However, little prior research has examined their usage or their connections to individual privacy and the role of race in policing, two growing topics of concern in the US. As a case study, we examine the Chicago Police Department's (CPD's) use of broadcast police communications (BPC) to coordinate the activity of law enforcement officers (LEOs) in the city. From a recently assembled archive of 80,775 hours of BPC associated with CPD operations, we analyze text transcripts of radio transmissions broadcast 9:00 AM to 5:00 PM on August 10th, 2018 in one majority Black, one majority white, and one majority Hispanic area of the city (24 hours of audio) to explore three research questions: (1) Do BPC reflect reported racial disparities in policing? (2) How and when is gender, race/ethnicity, and age mentioned in BPC? (3) To what extent do BPC include sensitive information, and who is put at most risk by this practice? (4) To what extent can large language models (LLMs) heighten this risk? We explore the vocabulary and speech acts used by police in BPC, comparing mentions of personal characteristics to local demographics, the personal information shared over BPC, and the privacy concerns that it poses. Analysis indicates (a) policing professionals in the city of Chicago exhibit disproportionate attention to Black members of the public regardless of context, (b) sociodemographic characteristics like gender, race/ethnicity, and age are primarily mentioned in BPC about event information, and (c) disproportionate attention introduces disproportionate privacy risks for Black members of the public.
"Confidently Nonsensical?'': A Critical Survey on the Perspectives and Challenges of 'Hallucinations' in NLP
Apr 11, 2024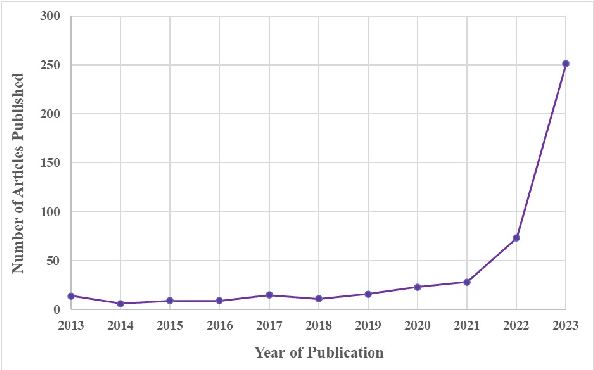


We investigate how hallucination in large language models (LLM) is characterized in peer-reviewed literature using a critical examination of 103 publications across NLP research. Through a comprehensive review of sociological and technological literature, we identify a lack of agreement with the term `hallucination.' Additionally, we conduct a survey with 171 practitioners from the field of NLP and AI to capture varying perspectives on hallucination. Our analysis underscores the necessity for explicit definitions and frameworks outlining hallucination within NLP, highlighting potential challenges, and our survey inputs provide a thematic understanding of the influence and ramifications of hallucination in society.
Automated Detection and Analysis of Data Practices Using A Real-World Corpus
Feb 16, 2024



Privacy policies are crucial for informing users about data practices, yet their length and complexity often deter users from reading them. In this paper, we propose an automated approach to identify and visualize data practices within privacy policies at different levels of detail. Leveraging crowd-sourced annotations from the ToS;DR platform, we experiment with various methods to match policy excerpts with predefined data practice descriptions. We further conduct a case study to evaluate our approach on a real-world policy, demonstrating its effectiveness in simplifying complex policies. Experiments show that our approach accurately matches data practice descriptions with policy excerpts, facilitating the presentation of simplified privacy information to users.
The Sentiment Problem: A Critical Survey towards Deconstructing Sentiment Analysis
Oct 18, 2023



We conduct an inquiry into the sociotechnical aspects of sentiment analysis (SA) by critically examining 189 peer-reviewed papers on their applications, models, and datasets. Our investigation stems from the recognition that SA has become an integral component of diverse sociotechnical systems, exerting influence on both social and technical users. By delving into sociological and technological literature on sentiment, we unveil distinct conceptualizations of this term in domains such as finance, government, and medicine. Our study exposes a lack of explicit definitions and frameworks for characterizing sentiment, resulting in potential challenges and biases. To tackle this issue, we propose an ethics sheet encompassing critical inquiries to guide practitioners in ensuring equitable utilization of SA. Our findings underscore the significance of adopting an interdisciplinary approach to defining sentiment in SA and offer a pragmatic solution for its implementation.
CALM : A Multi-task Benchmark for Comprehensive Assessment of Language Model Bias
Aug 24, 2023As language models (LMs) become increasingly powerful, it is important to quantify and compare them for sociodemographic bias with potential for harm. Prior bias measurement datasets are sensitive to perturbations in their manually designed templates, therefore unreliable. To achieve reliability, we introduce the Comprehensive Assessment of Language Model bias (CALM), a benchmark dataset to quantify bias in LMs across three tasks. We integrate 16 existing datasets across different domains, such as Wikipedia and news articles, to filter 224 templates from which we construct a dataset of 78,400 examples. We compare the diversity of CALM with prior datasets on metrics such as average semantic similarity, and variation in template length, and test the sensitivity to small perturbations. We show that our dataset is more diverse and reliable than previous datasets, thus better capture the breadth of linguistic variation required to reliably evaluate model bias. We evaluate 20 large language models including six prominent families of LMs such as Llama-2. In two LM series, OPT and Bloom, we found that larger parameter models are more biased than lower parameter models. We found the T0 series of models to be the least biased. Furthermore, we noticed a tradeoff between gender and racial bias with increasing model size in some model series. The code is available at https://github.com/vipulgupta1011/CALM.
Unmasking Nationality Bias: A Study of Human Perception of Nationalities in AI-Generated Articles
Aug 08, 2023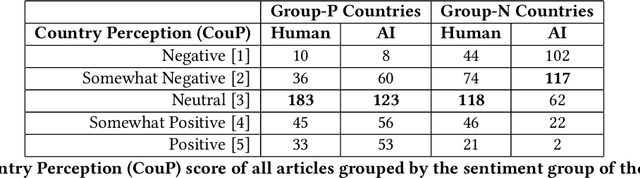
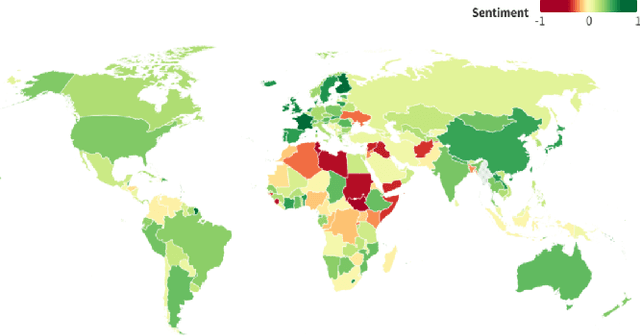

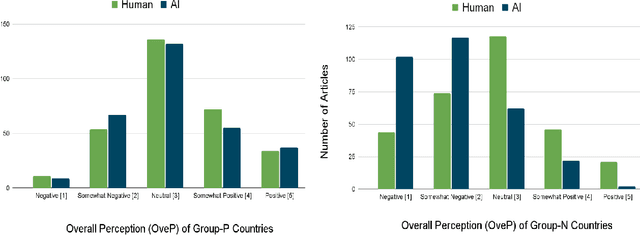
We investigate the potential for nationality biases in natural language processing (NLP) models using human evaluation methods. Biased NLP models can perpetuate stereotypes and lead to algorithmic discrimination, posing a significant challenge to the fairness and justice of AI systems. Our study employs a two-step mixed-methods approach that includes both quantitative and qualitative analysis to identify and understand the impact of nationality bias in a text generation model. Through our human-centered quantitative analysis, we measure the extent of nationality bias in articles generated by AI sources. We then conduct open-ended interviews with participants, performing qualitative coding and thematic analysis to understand the implications of these biases on human readers. Our findings reveal that biased NLP models tend to replicate and amplify existing societal biases, which can translate to harm if used in a sociotechnical setting. The qualitative analysis from our interviews offers insights into the experience readers have when encountering such articles, highlighting the potential to shift a reader's perception of a country. These findings emphasize the critical role of public perception in shaping AI's impact on society and the need to correct biases in AI systems.
Automated Ableism: An Exploration of Explicit Disability Biases in Sentiment and Toxicity Analysis Models
Jul 18, 2023



We analyze sentiment analysis and toxicity detection models to detect the presence of explicit bias against people with disability (PWD). We employ the bias identification framework of Perturbation Sensitivity Analysis to examine conversations related to PWD on social media platforms, specifically Twitter and Reddit, in order to gain insight into how disability bias is disseminated in real-world social settings. We then create the \textit{Bias Identification Test in Sentiment} (BITS) corpus to quantify explicit disability bias in any sentiment analysis and toxicity detection models. Our study utilizes BITS to uncover significant biases in four open AIaaS (AI as a Service) sentiment analysis tools, namely TextBlob, VADER, Google Cloud Natural Language API, DistilBERT and two toxicity detection models, namely two versions of Toxic-BERT. Our findings indicate that all of these models exhibit statistically significant explicit bias against PWD.
* TrustNLP at ACL 2023