 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Persona-Aware Toxicity Detection with Prompt Optimization and Learned Ensembling
Jan 05, 2026Toxicity detection is inherently subjective, shaped by the diverse perspectives and social priors of different demographic groups. While ``pluralistic'' modeling as used in economics and the social sciences aims to capture perspective differences across contexts, current Large Language Model (LLM) prompting techniques have different results across different personas and base models. In this work, we conduct a systematic evaluation of persona-aware toxicity detection, showing that no single prompting method, including our proposed automated prompt optimization strategy, uniformly dominates across all model-persona pairs. To exploit complementary errors, we explore ensembling four prompting variants and propose a lightweight meta-ensemble: an SVM over the 4-bit vector of prompt predictions. Our results demonstrate that the proposed SVM ensemble consistently outperforms individual prompting methods and traditional majority-voting techniques, achieving the strongest overall performance across diverse personas. This work provides one of the first systematic comparisons of persona-conditioned prompting for toxicity detection and offers a robust method for pluralistic evaluation in subjective NLP tasks.
Concept-based Rubrics Improve LLM Formative Assessment and Data Synthesis
Apr 04, 2025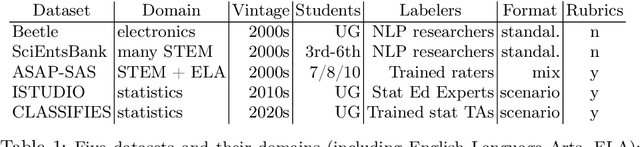



Formative assessment in STEM topics aims to promote student learning by identifying students' current understanding, thus targeting how to promote further learning. Previous studies suggest that the assessment performance of current generative large language models (LLMs) on constructed responses to open-ended questions is significantly lower than that of supervised classifiers trained on high-quality labeled data. However, we demonstrate that concept-based rubrics can significantly enhance LLM performance, which narrows the gap between LLMs as off-the shelf assessment tools, and smaller supervised models, which need large amounts of training data. For datasets where concept-based rubrics allow LLMs to achieve strong performance, we show that the concept-based rubrics help the same LLMs generate high quality synthetic data for training lightweight, high-performance supervised models. Our experiments span diverse STEM student response datasets with labels of varying quality, including a new real-world dataset that contains some AI-assisted responses, which introduces additional considerations.
Can LLMs Rank the Harmfulness of Smaller LLMs? We are Not There Yet
Feb 07, 2025



Large language models (LLMs) have become ubiquitous, thus it is important to understand their risks and limitations. Smaller LLMs can be deployed where compute resources are constrained, such as edge devices, but with different propensity to generate harmful output. Mitigation of LLM harm typically depends on annotating the harmfulness of LLM output, which is expensive to collect from humans. This work studies two questions: How do smaller LLMs rank regarding generation of harmful content? How well can larger LLMs annotate harmfulness? We prompt three small LLMs to elicit harmful content of various types, such as discriminatory language, offensive content, privacy invasion, or negative influence, and collect human rankings of their outputs. Then, we evaluate three state-of-the-art large LLMs on their ability to annotate the harmfulness of these responses. We find that the smaller models differ with respect to harmfulness. We also find that large LLMs show low to moderate agreement with humans. These findings underline the need for further work on harm mitigation in LLMs.
Joint Training for Selective Prediction
Oct 31, 2024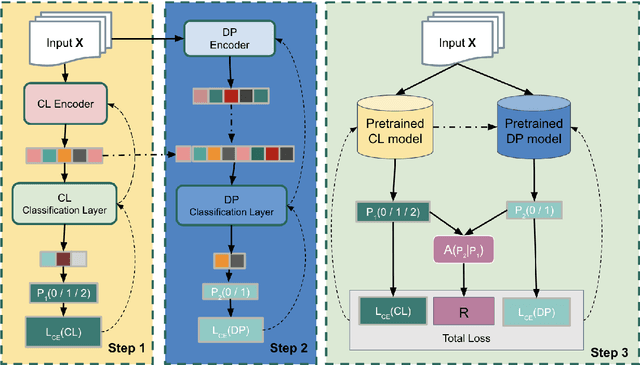
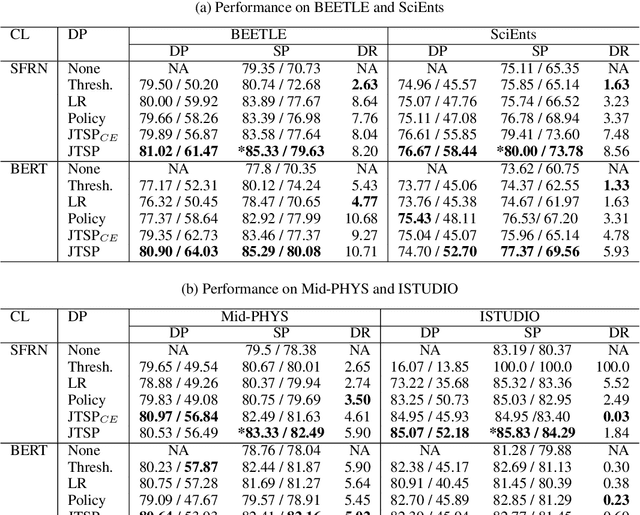

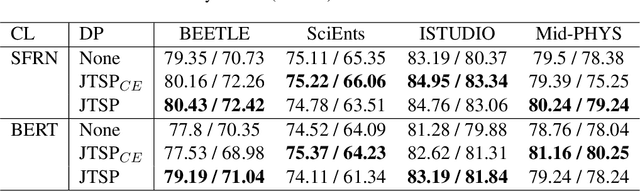
Classifier models are prevalent in natural language processing (NLP), often with high accuracy. Yet in real world settings, human-in-the-loop systems can foster trust in model outputs and even higher performance. Selective Prediction (SP) methods determine when to adopt a classifier's output versus defer to a human. Previous SP approaches have addressed how to improve softmax as a measure of model confidence, or have developed separate confidence estimators. One previous method involves learning a deferral model based on engineered features. We introduce a novel joint-training approach that simultaneously optimizes learned representations used by the classifier module and a learned deferral policy. Our results on four classification tasks demonstrate that joint training not only leads to better SP outcomes over two strong baselines, but also improves the performance of both modules.
Improving Model Evaluation using SMART Filtering of Benchmark Datasets
Oct 26, 2024



One of the most challenging problems facing NLP today is evaluation. Some of the most pressing issues pertain to benchmark saturation, data contamination, and diversity in the quality of test examples. To address these concerns, we propose Selection Methodology for Accurate, Reduced, and Targeted (SMART) filtering, a novel approach to select a high-quality subset of examples from existing benchmark datasets by systematically removing less informative and less challenging examples. Our approach applies three filtering criteria, removing (i) easy examples, (ii) data-contaminated examples, and (iii) examples that are similar to each other based on distance in an embedding space. We demonstrate the effectiveness of SMART on three multiple choice QA datasets, where our methodology increases efficiency by reducing dataset size by 48\% on average, while increasing Pearson correlation with rankings from ChatBot Arena, a more open-ended human evaluation setting. Our method enables us to be more efficient, whether using SMART to make new benchmarks more challenging or to revitalize older datasets, while still preserving the relative model rankings.
How Well Can You Articulate that Idea? Insights from Automated Formative Assessment
Apr 17, 2024
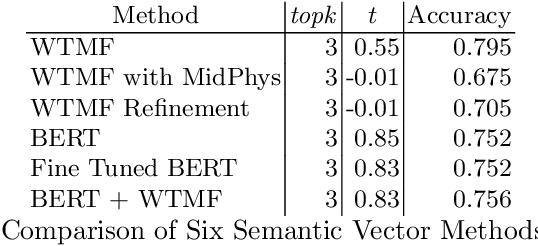
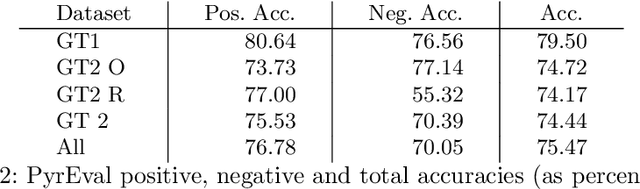
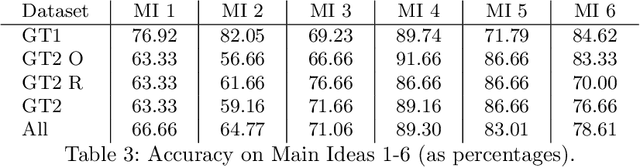
Automated methods are becoming increasingly integrated into studies of formative feedback on students' science explanation writing. Most of this work, however, addresses students' responses to short answer questions. We investigate automated feedback on students' science explanation essays, where students must articulate multiple ideas. Feedback is based on a rubric that identifies the main ideas students are prompted to include in explanatory essays about the physics of energy and mass, given their experiments with a simulated roller coaster. We have found that students generally improve on revised versions of their essays. Here, however, we focus on two factors that affect the accuracy of the automated feedback. First, we find that the main ideas in the rubric differ with respect to how much freedom they afford in explanations of the idea, thus explanation of a natural law is relatively constrained. Students have more freedom in how they explain complex relations they observe in their roller coasters, such as transfer of different forms of energy. Second, by tracing the automated decision process, we can diagnose when a student's statement lacks sufficient clarity for the automated tool to associate it more strongly with one of the main ideas above all others. This in turn provides an opportunity for teachers and peers to help students reflect on how to state their ideas more clearly.
VerAs: Verify then Assess STEM Lab Reports
Feb 07, 2024

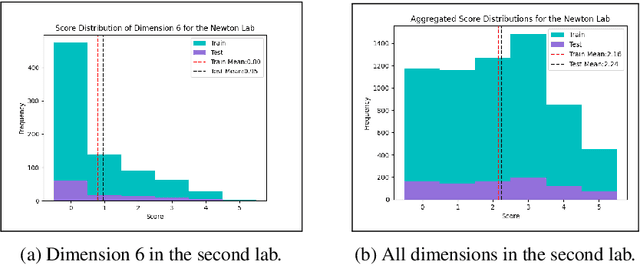

With an increasing focus in STEM education on critical thinking skills, science writing plays an ever more important role in curricula that stress inquiry skills. A recently published dataset of two sets of college level lab reports from an inquiry-based physics curriculum relies on analytic assessment rubrics that utilize multiple dimensions, specifying subject matter knowledge and general components of good explanations. Each analytic dimension is assessed on a 6-point scale, to provide detailed feedback to students that can help them improve their science writing skills. Manual assessment can be slow, and difficult to calibrate for consistency across all students in large classes. While much work exists on automated assessment of open-ended questions in STEM subjects, there has been far less work on long-form writing such as lab reports. We present an end-to-end neural architecture that has separate verifier and assessment modules, inspired by approaches to Open Domain Question Answering (OpenQA). VerAs first verifies whether a report contains any content relevant to a given rubric dimension, and if so, assesses the relevant sentences. On the lab reports, VerAs outperforms multiple baselines based on OpenQA systems or Automated Essay Scoring (AES). VerAs also performs well on an analytic rubric for middle school physics essays.
The Sentiment Problem: A Critical Survey towards Deconstructing Sentiment Analysis
Oct 18, 2023



We conduct an inquiry into the sociotechnical aspects of sentiment analysis (SA) by critically examining 189 peer-reviewed papers on their applications, models, and datasets. Our investigation stems from the recognition that SA has become an integral component of diverse sociotechnical systems, exerting influence on both social and technical users. By delving into sociological and technological literature on sentiment, we unveil distinct conceptualizations of this term in domains such as finance, government, and medicine. Our study exposes a lack of explicit definitions and frameworks for characterizing sentiment, resulting in potential challenges and biases. To tackle this issue, we propose an ethics sheet encompassing critical inquiries to guide practitioners in ensuring equitable utilization of SA. Our findings underscore the significance of adopting an interdisciplinary approach to defining sentiment in SA and offer a pragmatic solution for its implementation.
CALM : A Multi-task Benchmark for Comprehensive Assessment of Language Model Bias
Aug 24, 2023As language models (LMs) become increasingly powerful, it is important to quantify and compare them for sociodemographic bias with potential for harm. Prior bias measurement datasets are sensitive to perturbations in their manually designed templates, therefore unreliable. To achieve reliability, we introduce the Comprehensive Assessment of Language Model bias (CALM), a benchmark dataset to quantify bias in LMs across three tasks. We integrate 16 existing datasets across different domains, such as Wikipedia and news articles, to filter 224 templates from which we construct a dataset of 78,400 examples. We compare the diversity of CALM with prior datasets on metrics such as average semantic similarity, and variation in template length, and test the sensitivity to small perturbations. We show that our dataset is more diverse and reliable than previous datasets, thus better capture the breadth of linguistic variation required to reliably evaluate model bias. We evaluate 20 large language models including six prominent families of LMs such as Llama-2. In two LM series, OPT and Bloom, we found that larger parameter models are more biased than lower parameter models. We found the T0 series of models to be the least biased. Furthermore, we noticed a tradeoff between gender and racial bias with increasing model size in some model series. The code is available at https://github.com/vipulgupta1011/CALM.
Survey on Sociodemographic Bias in Natural Language Processing
Jun 27, 2023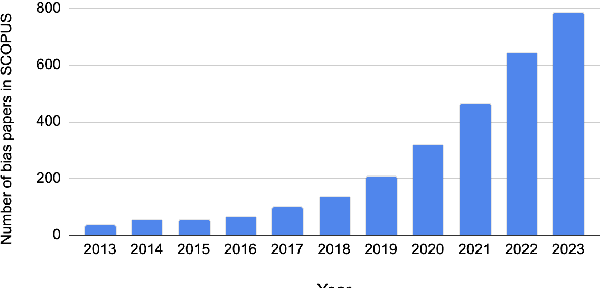
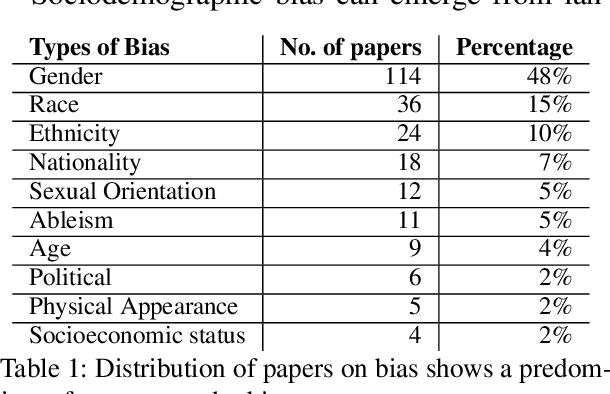
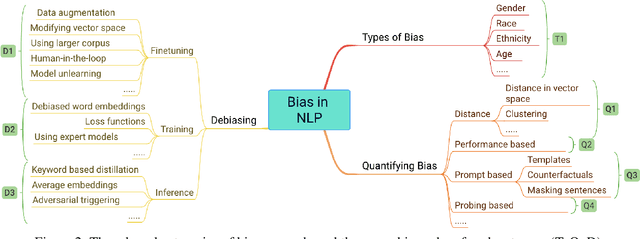
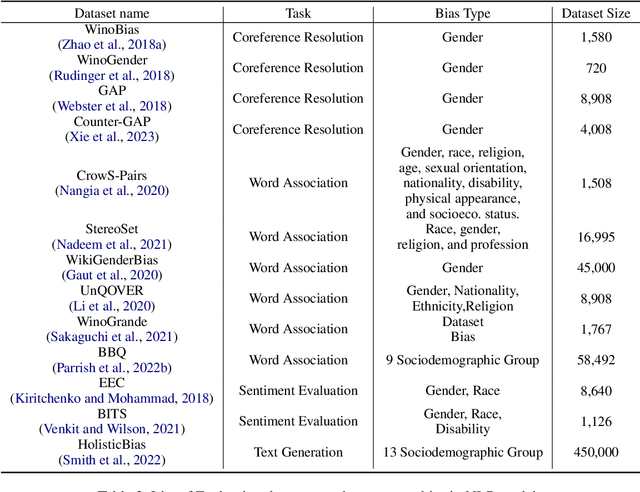
Deep neural networks often learn unintended biases during training, which might have harmful effects when deployed in real-world settings. This paper surveys 209 papers on bias in NLP models, most of which address sociodemographic bias. To better understand the distinction between bias and real-world harm, we turn to ideas from psychology and behavioral economics to propose a definition for sociodemographic bias. We identify three main categories of NLP bias research: types of bias, quantifying bias, and debiasing. We conclude that current approaches on quantifying bias face reliability issues, that many of the bias metrics do not relate to real-world biases, and that current debiasing techniques are superficial and hide bias rather than removing it. Finally, we provide recommendations for future work.