 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Know-Act Gap via Task-Level Autoregressive Reasoning
Mar 23, 2026LLMs often generate seemingly valid answers to flawed or ill-posed inputs. This is not due to missing knowledge: under discriminative prompting, the same models can mostly identify such issues, yet fail to reflect this in standard generative responses. This reveals a fundamental know-act gap between discriminative recognition and generative behavior. Prior work largely characterizes this issue in narrow settings, such as math word problems or question answering, with limited focus on how to integrate these two modes. In this work, we present a comprehensive analysis using FaultyScience, a newly constructed large-scale, cross-disciplinary benchmark of faulty scientific questions. We show that the gap is pervasive and stems from token-level autoregression, which entangles task selection (validate vs. answer) with content generation, preventing discriminative knowledge from being utilized. To address this, we propose DeIllusionLLM, a task-level autoregressive framework that explicitly models this decision. Through self-distillation, the model unifies discriminative judgment and generative reasoning within a single backbone. Empirically, DeIllusionLLM substantially reduces answer-despite-error failures under natural prompting while maintaining general reasoning performance, demonstrating that self-distillation is an effective and scalable solution for bridging the discriminative-generative know-act gap
Self-Explaining Hate Speech Detection with Moral Rationales
Jan 07, 2026Hate speech detection models rely on surface-level lexical features, increasing vulnerability to spurious correlations and limiting robustness, cultural contextualization, and interpretability. We propose Supervised Moral Rationale Attention (SMRA), the first self-explaining hate speech detection framework to incorporate moral rationales as direct supervision for attention alignment. Based on Moral Foundations Theory, SMRA aligns token-level attention with expert-annotated moral rationales, guiding models to attend to morally salient spans rather than spurious lexical patterns. Unlike prior rationale-supervised or post-hoc approaches, SMRA integrates moral rationale supervision directly into the training objective, producing inherently interpretable and contextualized explanations. To support our framework, we also introduce HateBRMoralXplain, a Brazilian Portuguese benchmark dataset annotated with hate labels, moral categories, token-level moral rationales, and socio-political metadata. Across binary hate speech detection and multi-label moral sentiment classification, SMRA consistently improves performance (e.g., +0.9 and +1.5 F1, respectively) while substantially enhancing explanation faithfulness, increasing IoU F1 (+7.4 pp) and Token F1 (+5.0 pp). Although explanations become more concise, sufficiency improves (+2.3 pp) and fairness remains stable, indicating more faithful rationales without performance or bias trade-offs
Robust Persona-Aware Toxicity Detection with Prompt Optimization and Learned Ensembling
Jan 05, 2026Toxicity detection is inherently subjective, shaped by the diverse perspectives and social priors of different demographic groups. While ``pluralistic'' modeling as used in economics and the social sciences aims to capture perspective differences across contexts, current Large Language Model (LLM) prompting techniques have different results across different personas and base models. In this work, we conduct a systematic evaluation of persona-aware toxicity detection, showing that no single prompting method, including our proposed automated prompt optimization strategy, uniformly dominates across all model-persona pairs. To exploit complementary errors, we explore ensembling four prompting variants and propose a lightweight meta-ensemble: an SVM over the 4-bit vector of prompt predictions. Our results demonstrate that the proposed SVM ensemble consistently outperforms individual prompting methods and traditional majority-voting techniques, achieving the strongest overall performance across diverse personas. This work provides one of the first systematic comparisons of persona-conditioned prompting for toxicity detection and offers a robust method for pluralistic evaluation in subjective NLP tasks.
Can LLMs Rank the Harmfulness of Smaller LLMs? We are Not There Yet
Feb 07, 2025



Large language models (LLMs) have become ubiquitous, thus it is important to understand their risks and limitations. Smaller LLMs can be deployed where compute resources are constrained, such as edge devices, but with different propensity to generate harmful output. Mitigation of LLM harm typically depends on annotating the harmfulness of LLM output, which is expensive to collect from humans. This work studies two questions: How do smaller LLMs rank regarding generation of harmful content? How well can larger LLMs annotate harmfulness? We prompt three small LLMs to elicit harmful content of various types, such as discriminatory language, offensive content, privacy invasion, or negative influence, and collect human rankings of their outputs. Then, we evaluate three state-of-the-art large LLMs on their ability to annotate the harmfulness of these responses. We find that the smaller models differ with respect to harmfulness. We also find that large LLMs show low to moderate agreement with humans. These findings underline the need for further work on harm mitigation in LLMs.
LLM Stability: A detailed analysis with some surprises
Aug 06, 2024



A concerning property of our nearly magical LLMs involves the variation of results given the exact same input and deterministic hyper-parameters. While AI has always had a certain level of noisiness from inputs outside of training data, we have generally had deterministic results for any particular input; that is no longer true. While most LLM practitioners are "in the know", we are unaware of any work that attempts to quantify current LLM stability. We suspect no one has taken the trouble because it is just too boring a paper to execute and write. But we have done it and there are some surprises. What kinds of surprises? The evaluated LLMs are rarely deterministic at the raw output level; they are much more deterministic at the parsed output/answer level but still rarely 100% stable across 5 re-runs with same data input. LLM accuracy variation is not normally distributed. Stability varies based on task.
VerAs: Verify then Assess STEM Lab Reports
Feb 07, 2024

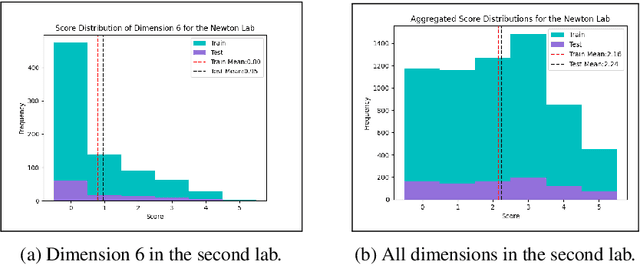

With an increasing focus in STEM education on critical thinking skills, science writing plays an ever more important role in curricula that stress inquiry skills. A recently published dataset of two sets of college level lab reports from an inquiry-based physics curriculum relies on analytic assessment rubrics that utilize multiple dimensions, specifying subject matter knowledge and general components of good explanations. Each analytic dimension is assessed on a 6-point scale, to provide detailed feedback to students that can help them improve their science writing skills. Manual assessment can be slow, and difficult to calibrate for consistency across all students in large classes. While much work exists on automated assessment of open-ended questions in STEM subjects, there has been far less work on long-form writing such as lab reports. We present an end-to-end neural architecture that has separate verifier and assessment modules, inspired by approaches to Open Domain Question Answering (OpenQA). VerAs first verifies whether a report contains any content relevant to a given rubric dimension, and if so, assesses the relevant sentences. On the lab reports, VerAs outperforms multiple baselines based on OpenQA systems or Automated Essay Scoring (AES). VerAs also performs well on an analytic rubric for middle school physics essays.
Prediction of new outlinks for focused Web crawling
Nov 10, 2021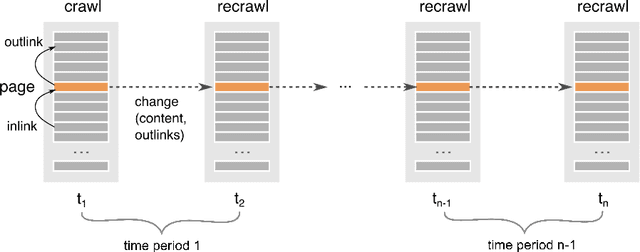
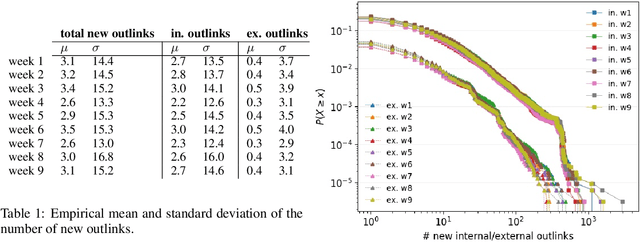
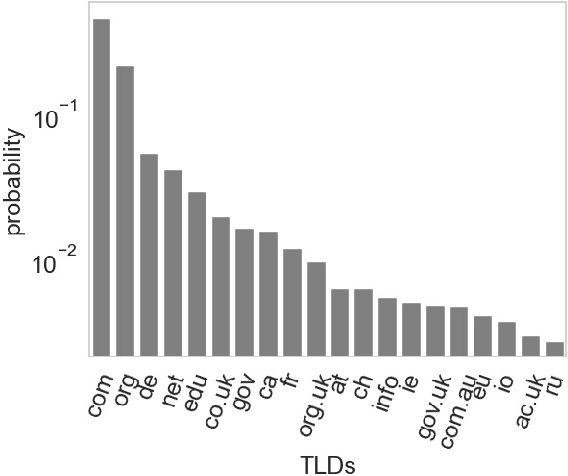

Discovering new hyperlinks enables Web crawlers to find new pages that have not yet been indexed. This is especially important for focused crawlers because they strive to provide a comprehensive analysis of specific parts of the Web, thus prioritizing discovery of new pages over discovery of changes in content. In the literature, changes in hyperlinks and content have been usually considered simultaneously. However, there is also evidence suggesting that these two types of changes are not necessarily related. Moreover, many studies about predicting changes assume that long history of a page is available, which is unattainable in practice. The aim of this work is to provide a methodology for detecting new links effectively using a short history. To this end, we use a dataset of ten crawls at intervals of one week. Our study consists of three parts. First, we obtain insight in the data by analyzing empirical properties of the number of new outlinks. We observe that these properties are, on average, stable over time, but there is a large difference between emergence of hyperlinks towards pages within and outside the domain of a target page (internal and external outlinks, respectively). Next, we provide statistical models for three targets: the link change rate, the presence of new links, and the number of new links. These models include the features used earlier in the literature, as well as new features introduced in this work. We analyze correlation between the features, and investigate their informativeness. A notable finding is that, if the history of the target page is not available, then our new features, that represent the history of related pages, are most predictive for new links in the target page. Finally, we propose ranking methods as guidelines for focused crawlers to efficiently discover new pages, which achieve excellent performance with respect to the corresponding targets.