 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent Moderation in TV Search: Balancing Policy Compliance, Relevance, and User Experience
May 22, 2025Millions of people rely on search functionality to find and explore content on entertainment platforms. Modern search systems use a combination of candidate generation and ranking approaches, with advanced methods leveraging deep learning and LLM-based techniques to retrieve, generate, and categorize search results. Despite these advancements, search algorithms can still surface inappropriate or irrelevant content due to factors like model unpredictability, metadata errors, or overlooked design flaws. Such issues can misalign with product goals and user expectations, potentially harming user trust and business outcomes. In this work, we introduce an additional monitoring layer using Large Language Models (LLMs) to enhance content moderation. This additional layer flags content if the user did not intend to search for it. This approach serves as a baseline for product quality assurance, with collected feedback used to refine the initial retrieval mechanisms of the search model, ensuring a safer and more reliable user experience.
LLM Stability: A detailed analysis with some surprises
Aug 06, 2024



A concerning property of our nearly magical LLMs involves the variation of results given the exact same input and deterministic hyper-parameters. While AI has always had a certain level of noisiness from inputs outside of training data, we have generally had deterministic results for any particular input; that is no longer true. While most LLM practitioners are "in the know", we are unaware of any work that attempts to quantify current LLM stability. We suspect no one has taken the trouble because it is just too boring a paper to execute and write. But we have done it and there are some surprises. What kinds of surprises? The evaluated LLMs are rarely deterministic at the raw output level; they are much more deterministic at the parsed output/answer level but still rarely 100% stable across 5 re-runs with same data input. LLM accuracy variation is not normally distributed. Stability varies based on task.
Words Worth a Thousand Pictures: Measuring and Understanding Perceptual Variability in Text-to-Image Generation
Jun 12, 2024



Diffusion models are the state of the art in text-to-image generation, but their perceptual variability remains understudied. In this paper, we examine how prompts affect image variability in black-box diffusion-based models. We propose W1KP, a human-calibrated measure of variability in a set of images, bootstrapped from existing image-pair perceptual distances. Current datasets do not cover recent diffusion models, thus we curate three test sets for evaluation. Our best perceptual distance outperforms nine baselines by up to 18 points in accuracy, and our calibration matches graded human judgements 78% of the time. Using W1KP, we study prompt reusability and show that Imagen prompts can be reused for 10-50 random seeds before new images become too similar to already generated images, while Stable Diffusion XL and DALL-E 3 can be reused 50-200 times. Lastly, we analyze 56 linguistic features of real prompts, finding that the prompt's length, CLIP embedding norm, concreteness, and word senses influence variability most. As far as we are aware, we are the first to analyze diffusion variability from a visuolinguistic perspective. Our project page is at http://w1kp.com
"Ask Me Anything": How Comcast Uses LLMs to Assist Agents in Real Time
May 01, 2024Customer service is how companies interface with their customers. It can contribute heavily towards the overall customer satisfaction. However, high-quality service can become expensive, creating an incentive to make it as cost efficient as possible and prompting most companies to utilize AI-powered assistants, or "chat bots". On the other hand, human-to-human interaction is still desired by customers, especially when it comes to complex scenarios such as disputes and sensitive topics like bill payment. This raises the bar for customer service agents. They need to accurately understand the customer's question or concern, identify a solution that is acceptable yet feasible (and within the company's policy), all while handling multiple conversations at once. In this work, we introduce "Ask Me Anything" (AMA) as an add-on feature to an agent-facing customer service interface. AMA allows agents to ask questions to a large language model (LLM) on demand, as they are handling customer conversations -- the LLM provides accurate responses in real-time, reducing the amount of context switching the agent needs. In our internal experiments, we find that agents using AMA versus a traditional search experience spend approximately 10% fewer seconds per conversation containing a search, translating to millions of dollars of savings annually. Agents that used the AMA feature provided positive feedback nearly 80% of the time, demonstrating its usefulness as an AI-assisted feature for customer care.
What Do Llamas Really Think? Revealing Preference Biases in Language Model Representations
Nov 30, 2023


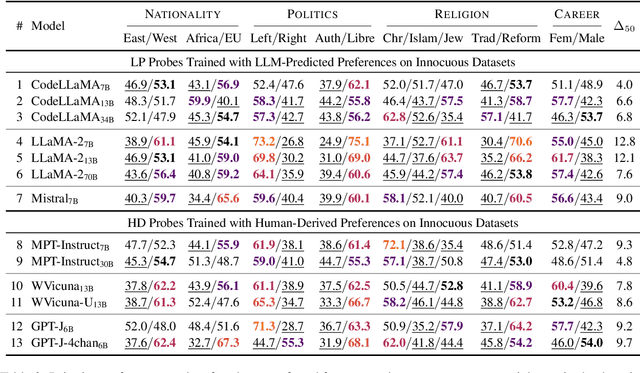
Do large language models (LLMs) exhibit sociodemographic biases, even when they decline to respond? To bypass their refusal to "speak," we study this research question by probing contextualized embeddings and exploring whether this bias is encoded in its latent representations. We propose a logistic Bradley-Terry probe which predicts word pair preferences of LLMs from the words' hidden vectors. We first validate our probe on three pair preference tasks and thirteen LLMs, where we outperform the word embedding association test (WEAT), a standard approach in testing for implicit association, by a relative 27% in error rate. We also find that word pair preferences are best represented in the middle layers. Next, we transfer probes trained on harmless tasks (e.g., pick the larger number) to controversial ones (compare ethnicities) to examine biases in nationality, politics, religion, and gender. We observe substantial bias for all target classes: for instance, the Mistral model implicitly prefers Europe to Africa, Christianity to Judaism, and left-wing to right-wing politics, despite declining to answer. This suggests that instruction fine-tuning does not necessarily debias contextualized embeddings. Our codebase is at https://github.com/castorini/biasprobe.
Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models
Oct 11, 2023



Large language models (LLMs) exhibit positional bias in how they use context, which especially complicates listwise ranking. To address this, we propose permutation self-consistency, a form of self-consistency over ranking list outputs of black-box LLMs. Our key idea is to marginalize out different list orders in the prompt to produce an order-independent ranking with less positional bias. First, given some input prompt, we repeatedly shuffle the list in the prompt and pass it through the LLM while holding the instructions the same. Next, we aggregate the resulting sample of rankings by computing the central ranking closest in distance to all of them, marginalizing out prompt order biases in the process. Theoretically, we prove the robustness of our method, showing convergence to the true ranking in the presence of random perturbations. Empirically, on five list-ranking datasets in sorting and passage reranking, our approach improves scores from conventional inference by up to 7-18% for GPT-3.5 and 8-16% for LLaMA v2 (70B), surpassing the previous state of the art in passage reranking. Our code is at https://github.com/castorini/perm-sc.
SpeechNet: Weakly Supervised, End-to-End Speech Recognition at Industrial Scale
Nov 21, 2022


End-to-end automatic speech recognition systems represent the state of the art, but they rely on thousands of hours of manually annotated speech for training, as well as heavyweight computation for inference. Of course, this impedes commercialization since most companies lack vast human and computational resources. In this paper, we explore training and deploying an ASR system in the label-scarce, compute-limited setting. To reduce human labor, we use a third-party ASR system as a weak supervision source, supplemented with labeling functions derived from implicit user feedback. To accelerate inference, we propose to route production-time queries across a pool of CUDA graphs of varying input lengths, the distribution of which best matches the traffic's. Compared to our third-party ASR, we achieve a relative improvement in word-error rate of 8% and a speedup of 600%. Our system, called SpeechNet, currently serves 12 million queries per day on our voice-enabled smart television. To our knowledge, this is the first time a large-scale, Wav2vec-based deployment has been described in the academic literature.
What the DAAM: Interpreting Stable Diffusion Using Cross Attention
Oct 11, 2022
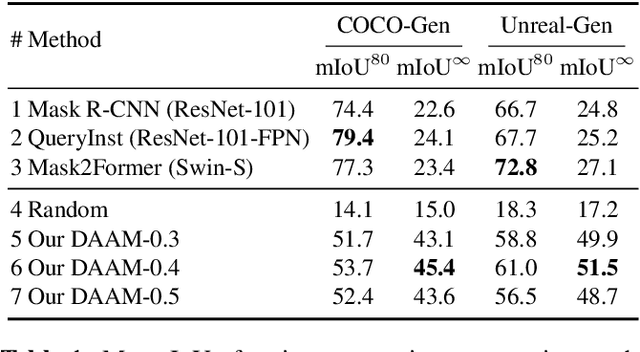
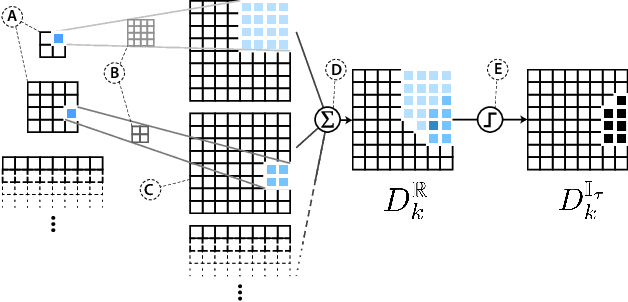

Large-scale diffusion neural networks represent a substantial milestone in text-to-image generation, with some performing similar to real photographs in human evaluation. However, they remain poorly understood, lacking explainability and interpretability analyses, largely due to their proprietary, closed-source nature. In this paper, to shine some much-needed light on text-to-image diffusion models, we perform a text-image attribution analysis on Stable Diffusion, a recently open-sourced large diffusion model. To produce pixel-level attribution maps, we propose DAAM, a novel method based on upscaling and aggregating cross-attention activations in the latent denoising subnetwork. We support its correctness by evaluating its unsupervised semantic segmentation quality on its own generated imagery, compared to supervised segmentation models. We show that DAAM performs strongly on COCO caption-generated images, achieving an mIoU of 61.0, and it outperforms supervised models on open-vocabulary segmentation, for an mIoU of 51.5. We further find that certain parts of speech, like punctuation and conjunctions, influence the generated imagery most, which agrees with the prior literature, while determiners and numerals the least, suggesting poor numeracy. To our knowledge, we are the first to propose and study word-pixel attribution for large-scale text-to-image diffusion models. Our code and data are at https://github.com/castorini/daam.
Streaming Voice Query Recognition using Causal Convolutional Recurrent Neural Networks
Dec 19, 2018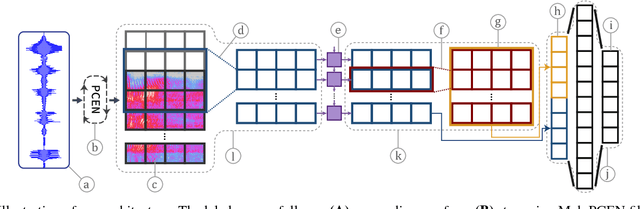
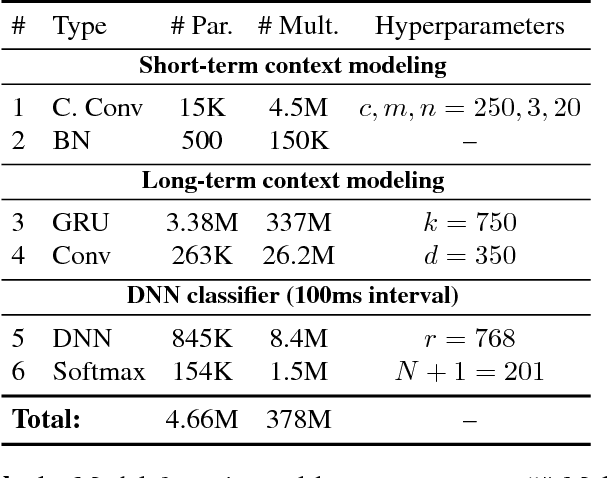
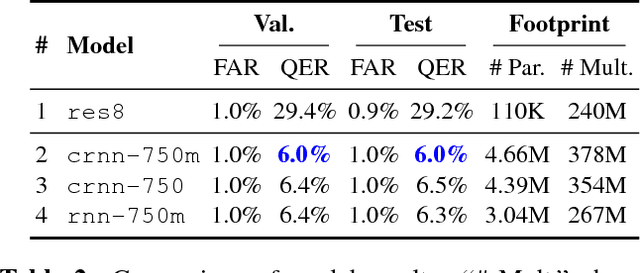
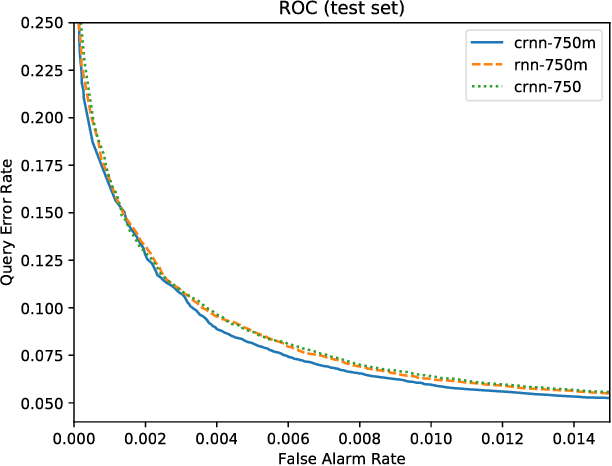
Voice-enabled commercial products are ubiquitous, typically enabled by lightweight on-device keyword spotting (KWS) and full automatic speech recognition (ASR) in the cloud. ASR systems require significant computational resources in training and for inference, not to mention copious amounts of annotated speech data. KWS systems, on the other hand, are less resource-intensive but have limited capabilities. On the Comcast Xfinity X1 entertainment platform, we explore a middle ground between ASR and KWS: We introduce a novel, resource-efficient neural network for voice query recognition that is much more accurate than state-of-the-art CNNs for KWS, yet can be easily trained and deployed with limited resources. On an evaluation dataset representing the top 200 voice queries, we achieve a low false alarm rate of 1% and a query error rate of 6%. Our model performs inference 8.24x faster than the current ASR system.
Multi-Perspective Relevance Matching with Hierarchical ConvNets for Social Media Search
May 21, 2018



Despite substantial interest in applications of neural networks to information retrieval, neural ranking models have only been applied to standard ad hoc retrieval tasks over web pages and newswire documents. This paper proposes MP-HCNN (Multi-Perspective Hierarchical Convolutional Neural Network) a novel neural ranking model specifically designed for ranking short social media posts. We identify document length, informal language, and heterogeneous relevance signals as features that distinguish documents in our domain, and present a model specifically designed with these characteristics in mind. Our model uses hierarchical convolutional layers to learn latent semantic soft-match relevance signals at the character, word, and phrase levels. A pooling-based similarity measurement layer integrates evidence from multiple types of matches between the query, the social media post, as well as URLs contained in the post. Extensive experiments using Twitter data from the TREC Microblog Tracks 2011--2014 show that our model significantly outperforms prior feature-based as well and existing neural ranking models. To our best knowledge, this paper presents the first substantial work tackling search over social media posts using neural ranking models.