 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised segmentation of land cover images using nonlinear canonical correlation analysis with multiple features and t-SNE
Jan 22, 2024Image segmentation is a clustering task whereby each pixel is assigned a cluster label. Remote sensing data usually consists of multiple bands of spectral images in which there exist semantically meaningful land cover subregions, co-registered with other source data such as LIDAR (LIght Detection And Ranging) data, where available. This suggests that, in order to account for spatial correlation between pixels, a feature vector associated with each pixel may be a vectorized tensor representing the multiple bands and a local patch as appropriate. Similarly, multiple types of texture features based on a pixel's local patch would also be beneficial for encoding locally statistical information and spatial variations, without necessarily labelling pixel-wise a large amount of ground truth, then training a supervised model, which is sometimes impractical. In this work, by resorting to label only a small quantity of pixels, a new semi-supervised segmentation approach is proposed. Initially, over all pixels, an image data matrix is created in high dimensional feature space. Then, t-SNE projects the high dimensional data onto 3D embedding. By using radial basis functions as input features, which use the labelled data samples as centres, to pair with the output class labels, a modified canonical correlation analysis algorithm, referred to as RBF-CCA, is introduced which learns the associated projection matrix via the small labelled data set. The associated canonical variables, obtained for the full image, are applied by k-means clustering algorithm. The proposed semi-supervised RBF-CCA algorithm has been implemented on several remotely sensed multispectral images, demonstrating excellent segmentation results.
Evaluating Large Language Models in Ophthalmology
Nov 07, 2023Purpose: The performance of three different large language models (LLMS) (GPT-3.5, GPT-4, and PaLM2) in answering ophthalmology professional questions was evaluated and compared with that of three different professional populations (medical undergraduates, medical masters, and attending physicians). Methods: A 100-item ophthalmology single-choice test was administered to three different LLMs (GPT-3.5, GPT-4, and PaLM2) and three different professional levels (medical undergraduates, medical masters, and attending physicians), respectively. The performance of LLM was comprehensively evaluated and compared with the human group in terms of average score, stability, and confidence. Results: Each LLM outperformed undergraduates in general, with GPT-3.5 and PaLM2 being slightly below the master's level, while GPT-4 showed a level comparable to that of attending physicians. In addition, GPT-4 showed significantly higher answer stability and confidence than GPT-3.5 and PaLM2. Conclusion: Our study shows that LLM represented by GPT-4 performs better in the field of ophthalmology. With further improvements, LLM will bring unexpected benefits in medical education and clinical decision making in the near future.
Evaluating multiple large language models in pediatric ophthalmology
Nov 07, 2023



IMPORTANCE The response effectiveness of different large language models (LLMs) and various individuals, including medical students, graduate students, and practicing physicians, in pediatric ophthalmology consultations, has not been clearly established yet. OBJECTIVE Design a 100-question exam based on pediatric ophthalmology to evaluate the performance of LLMs in highly specialized scenarios and compare them with the performance of medical students and physicians at different levels. DESIGN, SETTING, AND PARTICIPANTS This survey study assessed three LLMs, namely ChatGPT (GPT-3.5), GPT-4, and PaLM2, were assessed alongside three human cohorts: medical students, postgraduate students, and attending physicians, in their ability to answer questions related to pediatric ophthalmology. It was conducted by administering questionnaires in the form of test papers through the LLM network interface, with the valuable participation of volunteers. MAIN OUTCOMES AND MEASURES Mean scores of LLM and humans on 100 multiple-choice questions, as well as the answer stability, correlation, and response confidence of each LLM. RESULTS GPT-4 performed comparably to attending physicians, while ChatGPT (GPT-3.5) and PaLM2 outperformed medical students but slightly trailed behind postgraduate students. Furthermore, GPT-4 exhibited greater stability and confidence when responding to inquiries compared to ChatGPT (GPT-3.5) and PaLM2. CONCLUSIONS AND RELEVANCE Our results underscore the potential for LLMs to provide medical assistance in pediatric ophthalmology and suggest significant capacity to guide the education of medical students.
A Data Quality Assessment Framework for AI-enabled Wireless Communication
Dec 13, 2022



Using artificial intelligent (AI) to re-design and enhance the current wireless communication system is a promising pathway for the future sixth-generation (6G) wireless network. The performance of AI-enabled wireless communication depends heavily on the quality of wireless air-interface data. Although there are various approaches to data quality assessment (DQA) for different applications, none has been designed for wireless air-interface data. In this paper, we propose a DQA framework to measure the quality of wireless air-interface data from three aspects: similarity, diversity, and completeness. The similarity measures how close the considered datasets are in terms of their statistical distributions; the diversity measures how well-rounded a dataset is, while the completeness measures to what degree the considered dataset satisfies the required performance metrics in an application scenario. The proposed framework can be applied to various types of wireless air-interface data, such as channel state information (CSI), signal-to-interference-plus-noise ratio (SINR), reference signal received power (RSRP), etc. For simplicity, the validity of our proposed DQA framework is corroborated by applying it to CSI data and using similarity and diversity metrics to improve CSI compression and recovery in Massive MIMO systems.
CoronaViz: Visualizing Multilayer Spatiotemporal COVID-19 Data with Animated Geocircles
Nov 10, 2022
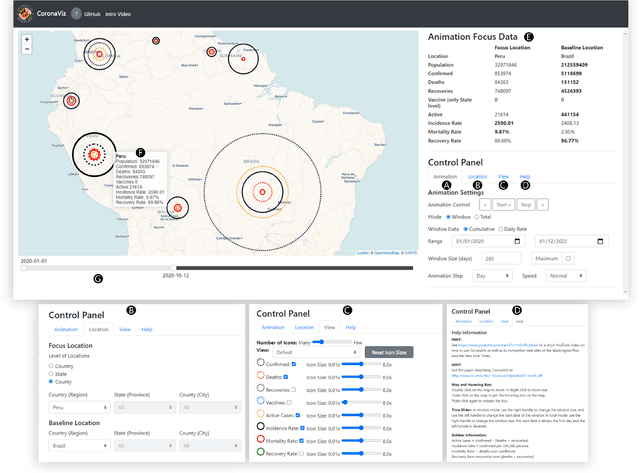


While many dashboards for visualizing COVID-19 data exist, most separate geospatial and temporal data into discrete visualizations or tables. Further, the common use of choropleth maps or space-filling map overlays supports only a single geospatial variable at once, making it difficult to compare the temporal and geospatial trends of multiple, potentially interacting variables, such as active cases, deaths, and vaccinations. We present CoronaViz, a COVID-19 visualization system that conveys multilayer, spatiotemporal data in a single, interactive display. CoronaViz encodes variables with concentric, hollow circles, termed geocircles, allowing multiple variables via color encoding and avoiding occlusion problems. The radii of geocircles relate to the values of the variables they represent via the psychophysically determined Flannery formula. The time dimension of spatiotemporal variables is encoded with sequential rendering. Animation controls allow the user to seek through time manually or to view the pandemic unfolding in accelerated time. An adjustable time window allows aggregation at any granularity, from single days to cumulative values for the entire available range. In addition to describing the CoronaViz system, we report findings from a user study comparing CoronaViz with multi-view dashboards from the New York Times and Johns Hopkins University. While participants preferred using the latter two dashboards to perform queries with only a geospatial component or only a temporal component, participants uniformly preferred CoronaViz for queries with both spatial and temporal components, highlighting the utility of a unified spatiotemporal encoding. CoronaViz is open-source and freely available at http://coronaviz.umiacs.io.
Streaming Voice Query Recognition using Causal Convolutional Recurrent Neural Networks
Dec 19, 2018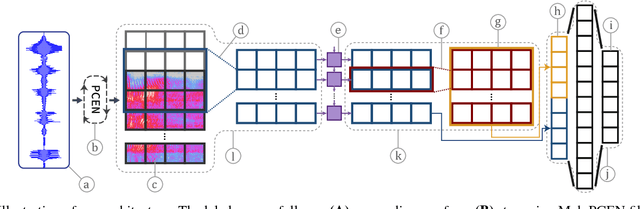
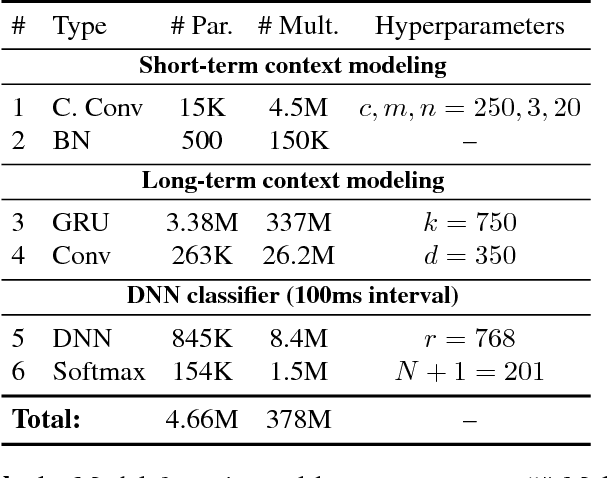
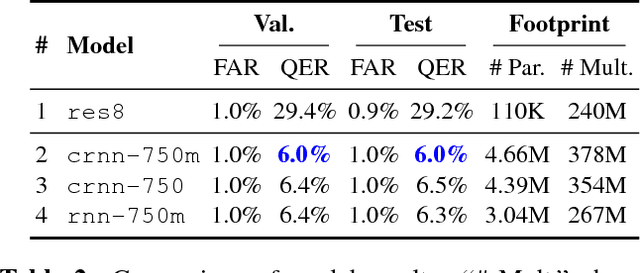
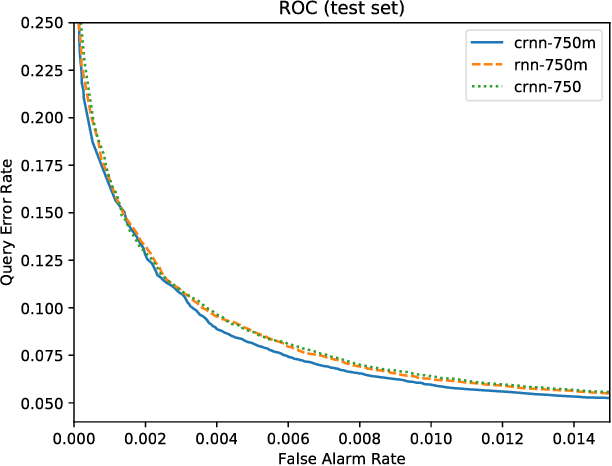
Voice-enabled commercial products are ubiquitous, typically enabled by lightweight on-device keyword spotting (KWS) and full automatic speech recognition (ASR) in the cloud. ASR systems require significant computational resources in training and for inference, not to mention copious amounts of annotated speech data. KWS systems, on the other hand, are less resource-intensive but have limited capabilities. On the Comcast Xfinity X1 entertainment platform, we explore a middle ground between ASR and KWS: We introduce a novel, resource-efficient neural network for voice query recognition that is much more accurate than state-of-the-art CNNs for KWS, yet can be easily trained and deployed with limited resources. On an evaluation dataset representing the top 200 voice queries, we achieve a low false alarm rate of 1% and a query error rate of 6%. Our model performs inference 8.24x faster than the current ASR system.