 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPO: Early-Stopping Proximal Policy Optimization
May 28, 2026When a large language model under reinforcement learning commits a wrong reasoning step early in a trajectory, standard algorithms force it to keep generating until the maximum horizon, spending compute on tokens that never receive positive reward and polluting advantage estimates with post-failure noise. We propose ESPO (Early-Stopping Proximal Policy Optimization), which detects trajectory failure on-the-fly and terminates rollouts early. At each generation step, ESPO computes a surrogate regret using only the logits already computed during sampling, and terminates when the smoothed cumulative regret significantly exceeds its estimated values. Truncated trajectories are treated as absorbing failure states with a terminal reward, concentrating negative temporal-difference (TD) errors near the detected failure step without any additional reward model or human annotation. On DeepSeek-R1-Distill-Qwen-7B trained for mathematical reasoning, ESPO surpasses PPO on AIME~2024 (46.28% vs. 45.25%), AMC~2023 (85.83% vs. 82.94%), and MATH-500 (87.42% vs. 85.43%), while saving more than 20% rollout tokens cumulatively.
Discover Fast Power Allocation Solution for Multi-Target Tracking via AlphaEvolve Evolution
May 03, 2026Efficient radar resource allocation is a fundamental yet computationally challenging problem, as optimal solutions typically require iterative optimization with high complexity. Motivated by the need for real-time scheduling, robust generalization, and low data dependency, this paper proposes a novel paradigm that leverages large language model (LLM)-guided evolutionary search (AlphaEvolve) to autonomously discover a closed-form power allocation solution for multi-target tracking. The approach encodes high-dimensional radar states into physically inspired features, then evolves a compact and interpretable scoring function, which is transformed to feasible power allocations via a deterministic constraint-satisfying transformation. Extensive experiments demonstrate that the discovered closed-form solution achieves near-optimal tracking accuracy (average relative performance loss of only $1.51\%$), reliable generalization across diverse scenarios and target counts, and over three orders of magnitude speedup compared to conventional iterative solvers. These results highlight the potential of LLM-guided symbolic search to revolutionize not only radar resource management but also broader classes of engineering optimization problems.
Driving risk emerges from the required two-dimensional joint evasive acceleration
Apr 20, 2026Most autonomous driving safety benchmarks use time-to-collision (TTC) to assess risk and guide safe behaviour. However, TTC-based methods treat risk as a one-dimensional closing problem, despite the inherently two-dimensional nature of collision avoidance, and therefore cannot faithfully capture risk or its evolution over time. Here, we report evasive acceleration (EA), a hyperparameter-free and physically interpretable two-dimensional paradigm for risk quantification. By evaluating all possible directions of collision avoidance, EA defines risk as the minimum magnitude of a constant relative acceleration vector required to alter the relative motion and make the interaction collision-free. Using interaction data from five open datasets and more than 600 real crashes, we derive percentile-based warning thresholds and show that EA provides the earliest statistically significant warning across all thresholds. Moreover, EA provides the best discrimination of eventual collision outcomes and improves information retention by 54.2-241.4% over all compared baselines. Adding EA to existing methods yields 17.5-95.5 times more information gain than adding existing methods to EA, indicating that EA captures much of the outcome-relevant information in existing methods while contributing substantial additional nonredundant information. Overall, EA better captures the structure of collision risk and provides a foundation for next-generation autonomous driving systems.
Seeing but Not Thinking: Routing Distraction in Multimodal Mixture-of-Experts
Apr 09, 2026Multimodal Mixture-of-Experts (MoE) models have achieved remarkable performance on vision-language tasks. However, we identify a puzzling phenomenon termed Seeing but Not Thinking: models accurately perceive image content yet fail in subsequent reasoning, while correctly solving identical problems presented as pure text. Through systematic analysis, we first verify that cross-modal semantic sharing exists in MoE architectures, ruling out semantic alignment failure as the sole explanation. We then reveal that visual experts and domain experts exhibit layer-wise separation, with image inputs inducing significant routing divergence from text inputs in middle layers where domain experts concentrate. Based on these findings, we propose the Routing Distraction hypothesis: when processing visual inputs, the routing mechanism fails to adequately activate task-relevant reasoning experts. To validate this hypothesis, we design a routing-guided intervention method that enhances domain expert activation. Experiments on three multimodal MoE models across six benchmarks demonstrate consistent improvements, with gains of up to 3.17% on complex visual reasoning tasks. Our analysis further reveals that domain expert identification locates cognitive functions rather than sample-specific solutions, enabling effective transfer across tasks with different information structures.
DIET: Learning to Distill Dataset Continually for Recommender Systems
Mar 26, 2026Modern deep recommender models are trained under a continual learning paradigm, relying on massive and continuously growing streaming behavioral logs. In large-scale platforms, retraining models on full historical data for architecture comparison or iteration is prohibitively expensive, severely slowing down model development. This challenge calls for data-efficient approaches that can faithfully approximate full-data training behavior without repeatedly processing the entire evolving data stream. We formulate this problem as \emph{streaming dataset distillation for recommender systems} and propose \textbf{DIET}, a unified framework that maintains a compact distilled dataset which evolves alongside streaming data while preserving training-critical signals. Unlike existing dataset distillation methods that construct a static distilled set, DIET models distilled data as an evolving training memory and updates it in a stage-wise manner to remain aligned with long-term training dynamics. DIET enables effective continual distillation through principled initialization from influential samples and selective updates guided by influence-aware memory addressing within a bi-level optimization framework. Experiments on large-scale recommendation benchmarks demonstrate that DIET compresses training data to as little as \textbf{1-2\%} of the original size while preserving performance trends consistent with full-data training, reducing model iteration cost by up to \textbf{60$\times$}. Moreover, the distilled datasets produced by DIET generalize well across different model architectures, highlighting streaming dataset distillation as a scalable and reusable data foundation for recommender system development.
Memory Over Maps: 3D Object Localization Without Reconstruction
Mar 20, 2026Target localization is a prerequisite for embodied tasks such as navigation and manipulation. Conventional approaches rely on constructing explicit 3D scene representations to enable target localization, such as point clouds, voxel grids, or scene graphs. While effective, these pipelines incur substantial mapping time, storage overhead, and scalability limitations. Recent advances in vision-language models suggest that rich semantic reasoning can be performed directly on 2D observations, raising a fundamental question: is a complete 3D scene reconstruction necessary for object localization? In this work, we revisit object localization and propose a map-free pipeline that stores only posed RGB-D keyframes as a lightweight visual memory--without constructing any global 3D representation of the scene. At query time, our method retrieves candidate views, re-ranks them with a vision-language model, and constructs a sparse, on-demand 3D estimate of the queried target through depth backprojection and multi-view fusion. Compared to reconstruction-based pipelines, this design drastically reduces preprocessing cost, enabling scene indexing that is over two orders of magnitude faster to build while using substantially less storage. We further validate the localized targets on downstream object-goal navigation tasks. Despite requiring no task-specific training, our approach achieves strong performance across multiple benchmarks, demonstrating that direct reasoning over image-based scene memory can effectively replace dense 3D reconstruction for object-centric robot navigation. Project page: https://ruizhou-cn.github.io/memory-over-maps/
DriveCode: Domain Specific Numerical Encoding for LLM-Based Autonomous Driving
Mar 01, 2026Large language models (LLMs) have shown great promise for autonomous driving. However, discretizing numbers into tokens limits precise numerical reasoning, fails to reflect the positional significance of digits in the training objective, and makes it difficult to achieve both decoding efficiency and numerical precision. These limitations affect both the processing of sensor measurements and the generation of precise control commands, creating a fundamental barrier for deploying LLM-based autonomous driving systems. In this paper, we introduce DriveCode, a novel numerical encoding method that represents numbers as dedicated embeddings rather than discrete text tokens. DriveCode employs a number projector to map numbers into the language model's hidden space, enabling seamless integration with visual and textual features in a unified multimodal sequence. Evaluated on OmniDrive, DriveGPT4, and DriveGPT4-V2 datasets, DriveCode demonstrates superior performance in trajectory prediction and control signal generation, confirming its effectiveness for LLM-based autonomous driving systems.
TwinRL-VLA: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation
Feb 09, 2026Despite strong generalization capabilities, Vision-Language-Action (VLA) models remain constrained by the high cost of expert demonstrations and insufficient real-world interaction. While online reinforcement learning (RL) has shown promise in improving general foundation models, applying RL to VLA manipulation in real-world settings is still hindered by low exploration efficiency and a restricted exploration space. Through systematic real-world experiments, we observe that the effective exploration space of online RL is closely tied to the data distribution of supervised fine-tuning (SFT). Motivated by this observation, we propose TwinRL, a digital twin-real-world collaborative RL framework designed to scale and guide exploration for VLA models. First, a high-fidelity digital twin is efficiently reconstructed from smartphone-captured scenes, enabling realistic bidirectional transfer between real and simulated environments. During the SFT warm-up stage, we introduce an exploration space expansion strategy using digital twins to broaden the support of the data trajectory distribution. Building on this enhanced initialization, we propose a sim-to-real guided exploration strategy to further accelerate online RL. Specifically, TwinRL performs efficient and parallel online RL in the digital twin prior to deployment, effectively bridging the gap between offline and online training stages. Subsequently, we exploit efficient digital twin sampling to identify failure-prone yet informative configurations, which are used to guide targeted human-in-the-loop rollouts on the real robot. In our experiments, TwinRL approaches 100% success in both in-distribution regions covered by real-world demonstrations and out-of-distribution regions, delivering at least a 30% speedup over prior real-world RL methods and requiring only about 20 minutes on average across four tasks.
Machine Learning with Multitype Protected Attributes: Intersectional Fairness through Regularisation
Sep 09, 2025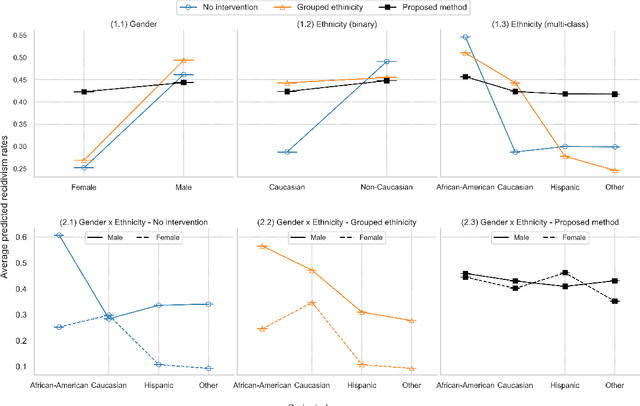
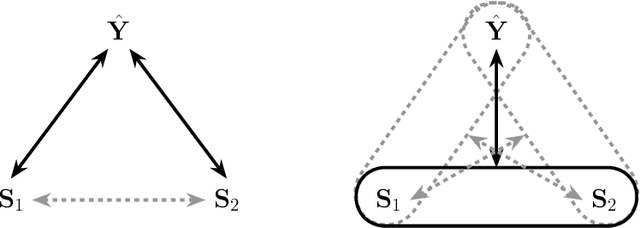
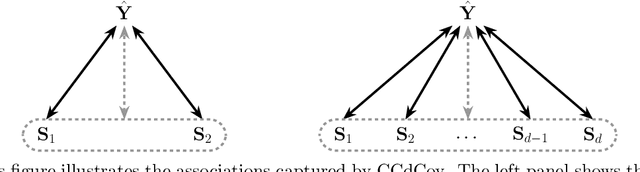
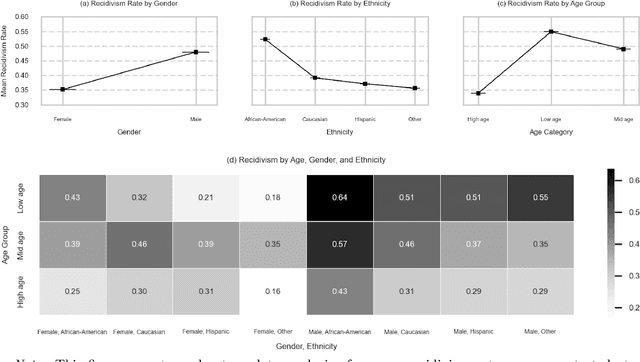
Ensuring equitable treatment (fairness) across protected attributes (such as gender or ethnicity) is a critical issue in machine learning. Most existing literature focuses on binary classification, but achieving fairness in regression tasks-such as insurance pricing or hiring score assessments-is equally important. Moreover, anti-discrimination laws also apply to continuous attributes, such as age, for which many existing methods are not applicable. In practice, multiple protected attributes can exist simultaneously; however, methods targeting fairness across several attributes often overlook so-called "fairness gerrymandering", thereby ignoring disparities among intersectional subgroups (e.g., African-American women or Hispanic men). In this paper, we propose a distance covariance regularisation framework that mitigates the association between model predictions and protected attributes, in line with the fairness definition of demographic parity, and that captures both linear and nonlinear dependencies. To enhance applicability in the presence of multiple protected attributes, we extend our framework by incorporating two multivariate dependence measures based on distance covariance: the previously proposed joint distance covariance (JdCov) and our novel concatenated distance covariance (CCdCov), which effectively address fairness gerrymandering in both regression and classification tasks involving protected attributes of various types. We discuss and illustrate how to calibrate regularisation strength, including a method based on Jensen-Shannon divergence, which quantifies dissimilarities in prediction distributions across groups. We apply our framework to the COMPAS recidivism dataset and a large motor insurance claims dataset.
Large Model Empowered Embodied AI: A Survey on Decision-Making and Embodied Learning
Aug 14, 2025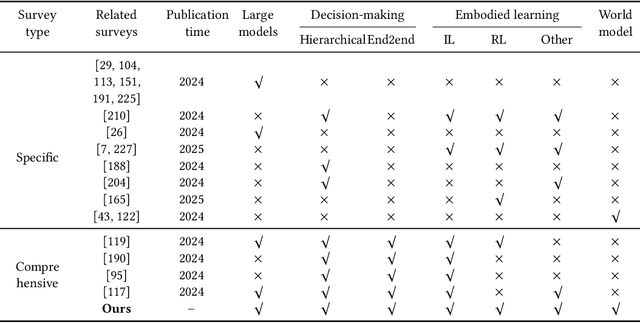
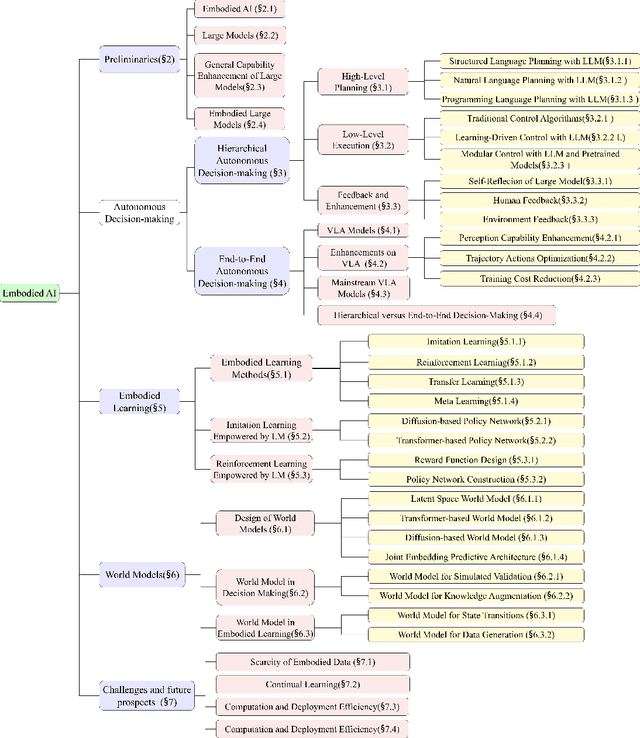
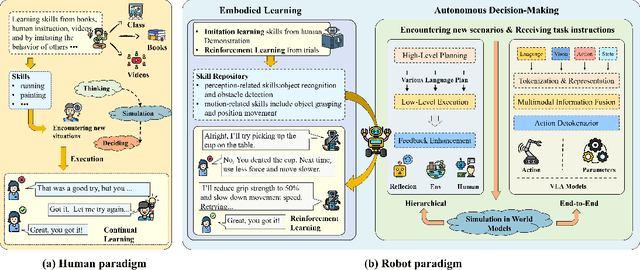
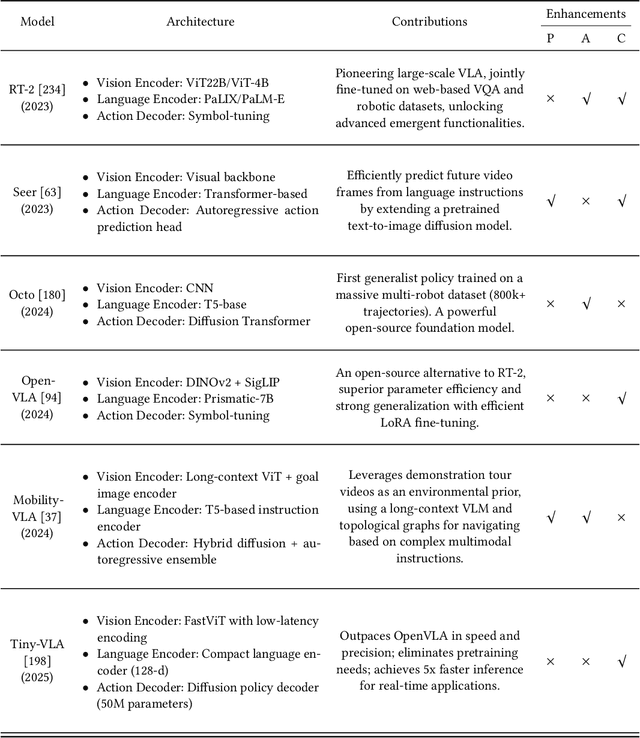
Embodied AI aims to develop intelligent systems with physical forms capable of perceiving, decision-making, acting, and learning in real-world environments, providing a promising way to Artificial General Intelligence (AGI). Despite decades of explorations, it remains challenging for embodied agents to achieve human-level intelligence for general-purpose tasks in open dynamic environments. Recent breakthroughs in large models have revolutionized embodied AI by enhancing perception, interaction, planning and learning. In this article, we provide a comprehensive survey on large model empowered embodied AI, focusing on autonomous decision-making and embodied learning. We investigate both hierarchical and end-to-end decision-making paradigms, detailing how large models enhance high-level planning, low-level execution, and feedback for hierarchical decision-making, and how large models enhance Vision-Language-Action (VLA) models for end-to-end decision making. For embodied learning, we introduce mainstream learning methodologies, elaborating on how large models enhance imitation learning and reinforcement learning in-depth. For the first time, we integrate world models into the survey of embodied AI, presenting their design methods and critical roles in enhancing decision-making and learning. Though solid advances have been achieved, challenges still exist, which are discussed at the end of this survey, potentially as the further research directions.