 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
May 20, 2026Multimodal large language models (MLLMs) have shown remarkable capability in bridging visual perception and textual reasoning, enabling zero-shot understanding across diverse industrial scenarios. However, their performance in open-vocabulary industrial anomaly detection (IAD) is often limited by domain-misaligned reasoning and hallucinated structural inferences. To address these challenges, we propose \textbf{IndusAgent}, a tool-augmented agentic framework for open-vocabulary IAD. Specifically, we first construct \textbf{Indus-CoT}, a structured dataset that integrates global visual observations, high-resolution local patches, and expert normalcy priors, providing supervision for fine-tuning the model on rigorous industrial inspection trajectories. Building on this, IndusAgent dynamically orchestrates a set of external tools, including dynamic region cropping, high-frequency feature enhancement, and prior retrieval, thus enabling the agent to actively resolve visual ambiguities and disentangle subtle anomalies. Furthermore, we introduce a gated reinforcement learning objective that jointly optimizes anomaly classification, localization accuracy, anomaly type reasoning, and efficient tool usage, ensuring that tool invocation occurs only when beneficial. Extensive evaluations on five industrial anomaly benchmarks, including MVTec-AD, VisA, MPDD, DTD, and SDD, demonstrate that IndusAgent achieves state-of-the-art zero-shot performance among all existing methods, validating our robustness and generalization capacity.
CaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
May 12, 2026In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
Robotic Manipulation is Vision-to-Geometry Mapping ($f(v) \rightarrow G$): Vision-Geometry Backbones over Language and Video Models
Apr 14, 2026At its core, robotic manipulation is a problem of vision-to-geometry mapping ($f(v) \rightarrow G$). Physical actions are fundamentally defined by geometric properties like 3D positions and spatial relationships. Consequently, we argue that the foundation for generalizable robotic control should be a vision-geometry backbone, rather than the widely adopted vision-language or video models. Conventional VLA and video-predictive models rely on backbones pretrained on large-scale 2D image-text or temporal pixel data. While effective, their representations are largely shaped by semantic concepts or 2D priors, which do not intrinsically align with the precise 3D geometric nature required for physical manipulation. Driven by this insight, we propose the Vision-Geometry-Action (VGA) model, which directly conditions action generation on pretrained native 3D representations. Specifically, VGA replaces conventional language or video backbones with a pretrained 3D world model, establishing a seamless vision-to-geometry mapping that translates visual inputs directly into physical actions. To further enhance geometric consistency, we introduce a Progressive Volumetric Modulation module and adopt a joint training strategy. Extensive experiments validate the effectiveness of our approach. In simulation benchmarks, VGA outperforms top-tier VLA baselines including $π_{0.5}$ and GeoVLA, demonstrating its superiority in precise manipulation. More importantly, VGA exhibits remarkable zero-shot generalization to unseen viewpoints in real-world deployments, consistently outperforming $π_{0.5}$. These results highlight that operating on native 3D representations-rather than translating through language or 2D video priors-is a highly promising direction for achieving generalizable physical intelligence.
Your Agent, Their Asset: A Real-World Safety Analysis of OpenClaw
Apr 06, 2026OpenClaw, the most widely deployed personal AI agent in early 2026, operates with full local system access and integrates with sensitive services such as Gmail, Stripe, and the filesystem. While these broad privileges enable high levels of automation and powerful personalization, they also expose a substantial attack surface that existing sandboxed evaluations fail to capture. To address this gap, we present the first real-world safety evaluation of OpenClaw and introduce the CIK taxonomy, which unifies an agent's persistent state into three dimensions, i.e., Capability, Identity, and Knowledge, for safety analysis. Our evaluations cover 12 attack scenarios on a live OpenClaw instance across four backbone models (Claude Sonnet 4.5, Opus 4.6, Gemini 3.1 Pro, and GPT-5.4). The results show that poisoning any single CIK dimension increases the average attack success rate from 24.6% to 64-74%, with even the most robust model exhibiting more than a threefold increase over its baseline vulnerability. We further assess three CIK-aligned defense strategies alongside a file-protection mechanism; however, the strongest defense still yields a 63.8% success rate under Capability-targeted attacks, while file protection blocks 97% of malicious injections but also prevents legitimate updates. Taken together, these findings show that the vulnerabilities are inherent to the agent architecture, necessitating more systematic safeguards to secure personal AI agents. Our project page is https://ucsc-vlaa.github.io/CIK-Bench.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Geometry-Guided Reinforcement Learning for Multi-view Consistent 3D Scene Editing
Mar 03, 2026Leveraging the priors of 2D diffusion models for 3D editing has emerged as a promising paradigm. However, maintaining multi-view consistency in edited results remains challenging, and the extreme scarcity of 3D-consistent editing paired data renders supervised fine-tuning (SFT), the most effective training strategy for editing tasks, infeasible. In this paper, we observe that, while generating multi-view consistent 3D content is highly challenging, verifying 3D consistency is tractable, naturally positioning reinforcement learning (RL) as a feasible solution. Motivated by this, we propose \textbf{RL3DEdit}, a single-pass framework driven by RL optimization with novel rewards derived from the 3D foundation model, VGGT. Specifically, we leverage VGGT's robust priors learned from massive real-world data, feed the edited images, and utilize the output confidence maps and pose estimation errors as reward signals, effectively anchoring the 2D editing priors onto a 3D-consistent manifold via RL. Extensive experiments demonstrate that RL3DEdit achieves stable multi-view consistency and outperforms state-of-the-art methods in editing quality with high efficiency. To promote the development of 3D editing, we will release the code and model.
FactGuard: Agentic Video Misinformation Detection via Reinforcement Learning
Feb 26, 2026Multimodal large language models (MLLMs) have substantially advanced video misinformation detection through unified multimodal reasoning, but they often rely on fixed-depth inference and place excessive trust in internally generated assumptions, particularly in scenarios where critical evidence is sparse, fragmented, or requires external verification. To address these limitations, we propose FactGuard, an agentic framework for video misinformation detection that formulates verification as an iterative reasoning process built upon MLLMs. FactGuard explicitly assesses task ambiguity and selectively invokes external tools to acquire critical evidence, enabling progressive refinement of reasoning trajectories. To further strengthen this capability, we introduce a two-stage training strategy that combines domain-specific agentic supervised fine-tuning with decision-aware reinforcement learning to optimize tool usage and calibrate risk-sensitive decision making. Extensive experiments on FakeSV, FakeTT, and FakeVV demonstrate FactGuard's state-of-the-art performance and validate its excellent robustness and generalization capacity.
What if Agents Could Imagine? Reinforcing Open-Vocabulary HOI Comprehension through Generation
Feb 12, 2026Multimodal Large Language Models have shown promising capabilities in bridging visual and textual reasoning, yet their reasoning capabilities in Open-Vocabulary Human-Object Interaction (OV-HOI) are limited by cross-modal hallucinations and occlusion-induced ambiguity. To address this, we propose \textbf{ImagineAgent}, an agentic framework that harmonizes cognitive reasoning with generative imagination for robust visual understanding. Specifically, our method innovatively constructs cognitive maps that explicitly model plausible relationships between detected entities and candidate actions. Subsequently, it dynamically invokes tools including retrieval augmentation, image cropping, and diffusion models to gather domain-specific knowledge and enriched visual evidence, thereby achieving cross-modal alignment in ambiguous scenarios. Moreover, we propose a composite reward that balances prediction accuracy and tool efficiency. Evaluations on SWIG-HOI and HICO-DET datasets demonstrate our SOTA performance, requiring approximately 20\% of training data compared to existing methods, validating our robustness and efficiency.
EMPOWER: Evolutionary Medical Prompt Optimization With Reinforcement Learning
Aug 25, 2025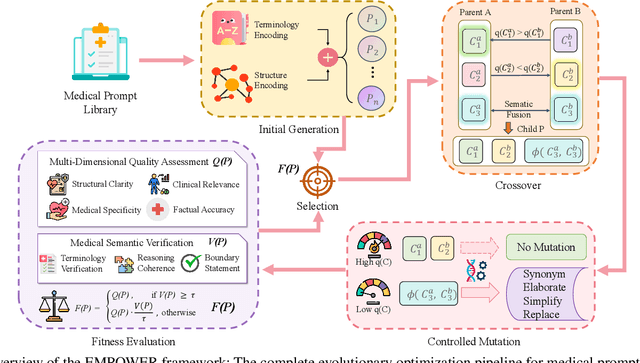
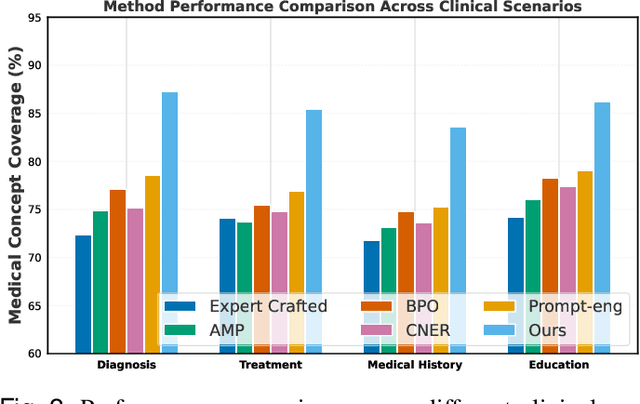
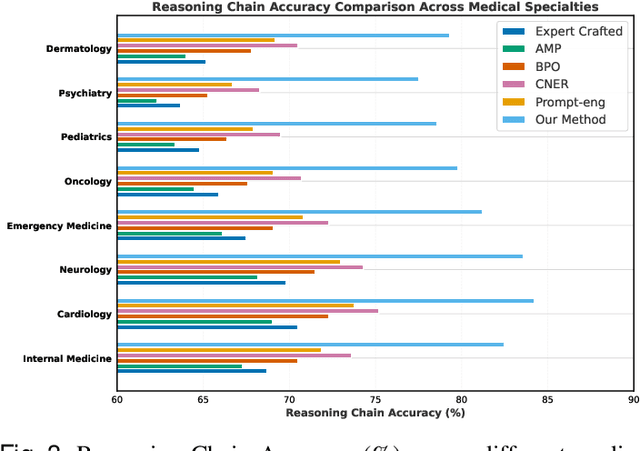
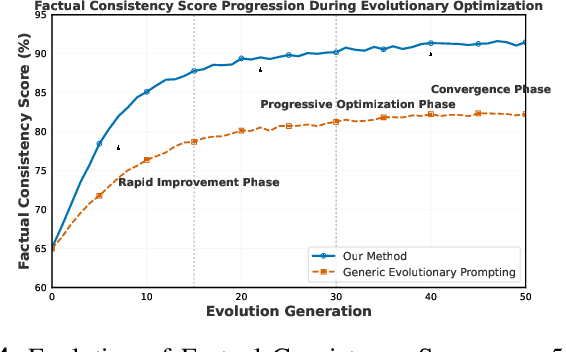
Prompt engineering significantly influences the reliability and clinical utility of Large Language Models (LLMs) in medical applications. Current optimization approaches inadequately address domain-specific medical knowledge and safety requirements. This paper introduces EMPOWER, a novel evolutionary framework that enhances medical prompt quality through specialized representation learning, multi-dimensional evaluation, and structure-preserving algorithms. Our methodology incorporates: (1) a medical terminology attention mechanism, (2) a comprehensive assessment architecture evaluating clarity, specificity, clinical relevance, and factual accuracy, (3) a component-level evolutionary algorithm preserving clinical reasoning integrity, and (4) a semantic verification module ensuring adherence to medical knowledge. Evaluation across diagnostic, therapeutic, and educational tasks demonstrates significant improvements: 24.7% reduction in factually incorrect content, 19.6% enhancement in domain specificity, and 15.3% higher clinician preference in blinded evaluations. The framework addresses critical challenges in developing clinically appropriate prompts, facilitating more responsible integration of LLMs into healthcare settings.
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025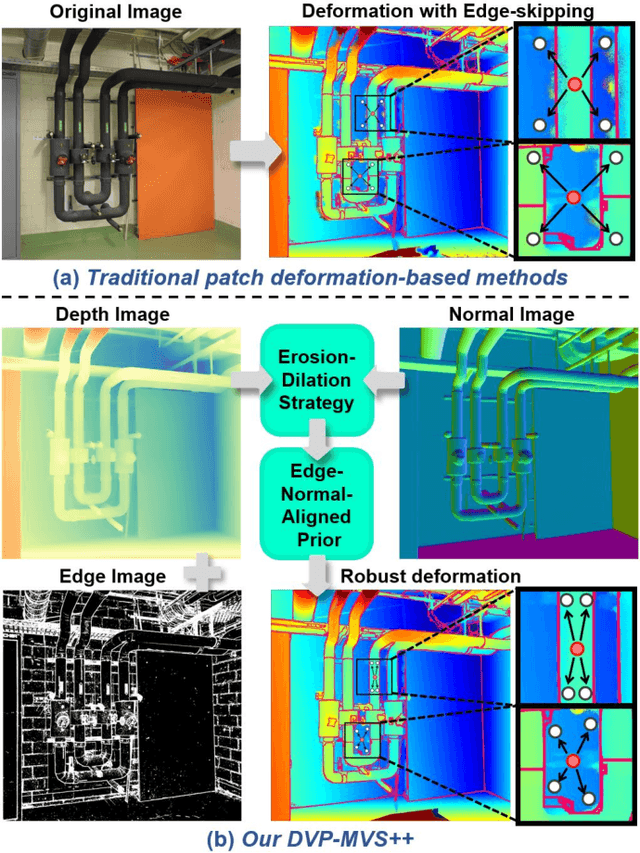
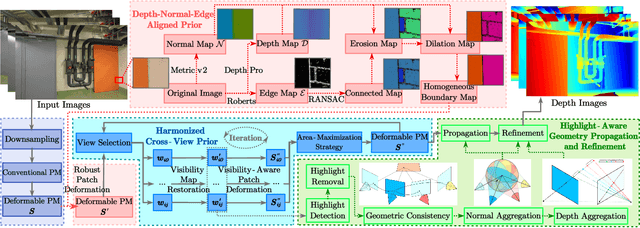
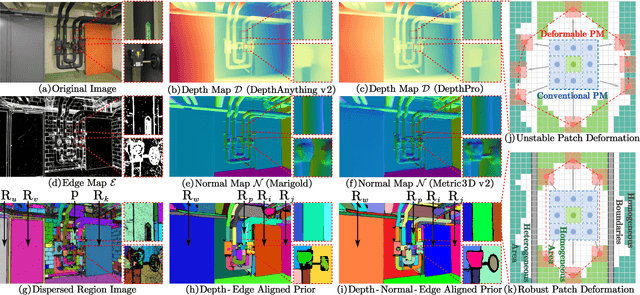
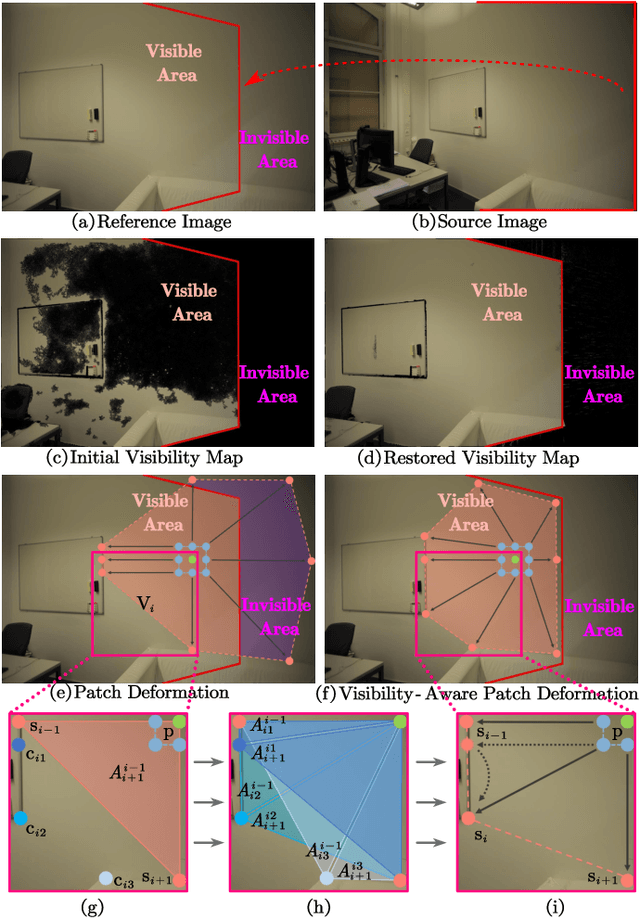
Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.