 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeGaussian: Tree-Guided Cascaded Contrastive Learning for Hierarchical Consistent 3D Gaussian Scene Segmentation and Understanding
Mar 31, 20263D Gaussian Splatting (3DGS) has emerged as a real-time, differentiable representation for neural scene understanding. However, existing 3DGS-based methods struggle to represent hierarchical 3D semantic structures and capture whole-part relationships in complex scenes. Moreover, dense pairwise comparisons and inconsistent hierarchical labels from 2D priors hinder feature learning, resulting in suboptimal segmentation. To address these limitations, we introduce TreeGaussian, a tree-guided cascaded contrastive learning framework that explicitly models hierarchical semantic relationships and reduces redundancy in contrastive supervision. By constructing a multi-level object tree, TreeGaussian enables structured learning across object-part hierarchies. In addition, we propose a two-stage cascaded contrastive learning strategy that progressively refines feature representations from global to local, mitigating saturation and stabilizing training. A Consistent Segmentation Detection (CSD) mechanism and a graph-based denoising module are further introduced to align segmentation modes across views while suppressing unstable Gaussian points, enhancing segmentation consistency and quality. Extensive experiments, including open-vocabulary 3D object selection, 3D point cloud understanding, and ablation studies, demonstrate the effectiveness and robustness of our approach.
FactGuard: Agentic Video Misinformation Detection via Reinforcement Learning
Feb 26, 2026Multimodal large language models (MLLMs) have substantially advanced video misinformation detection through unified multimodal reasoning, but they often rely on fixed-depth inference and place excessive trust in internally generated assumptions, particularly in scenarios where critical evidence is sparse, fragmented, or requires external verification. To address these limitations, we propose FactGuard, an agentic framework for video misinformation detection that formulates verification as an iterative reasoning process built upon MLLMs. FactGuard explicitly assesses task ambiguity and selectively invokes external tools to acquire critical evidence, enabling progressive refinement of reasoning trajectories. To further strengthen this capability, we introduce a two-stage training strategy that combines domain-specific agentic supervised fine-tuning with decision-aware reinforcement learning to optimize tool usage and calibrate risk-sensitive decision making. Extensive experiments on FakeSV, FakeTT, and FakeVV demonstrate FactGuard's state-of-the-art performance and validate its excellent robustness and generalization capacity.
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025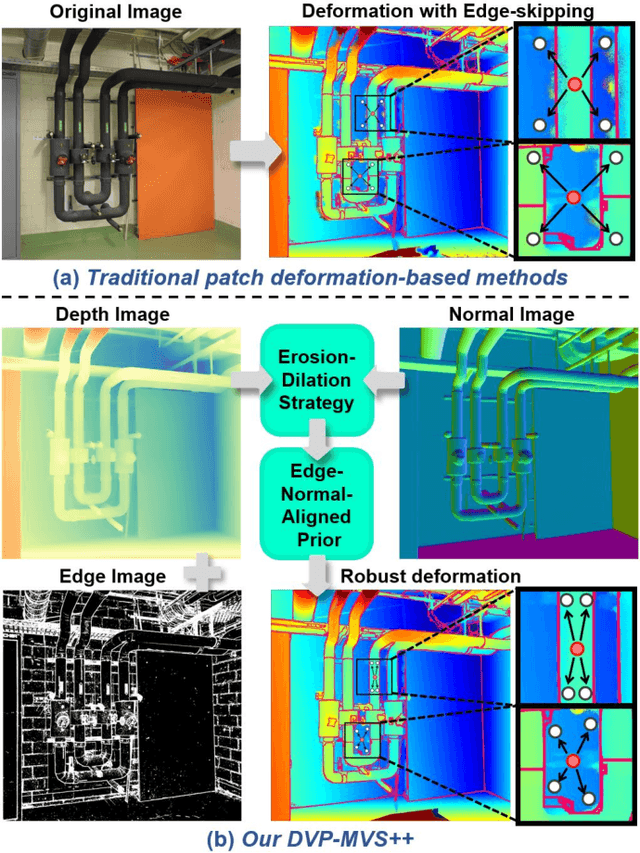
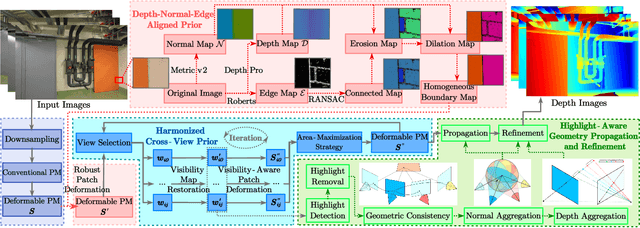
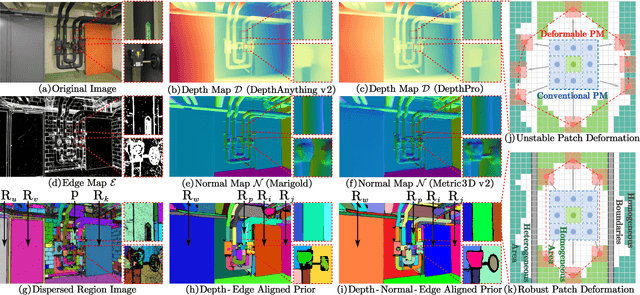
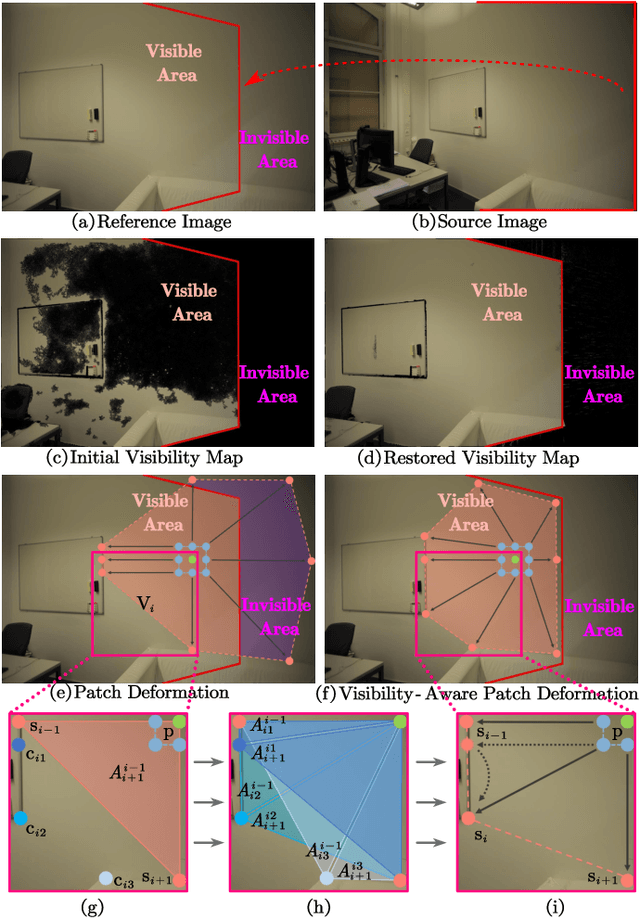
Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
STDR: Spatio-Temporal Decoupling for Real-Time Dynamic Scene Rendering
May 28, 2025Although dynamic scene reconstruction has long been a fundamental challenge in 3D vision, the recent emergence of 3D Gaussian Splatting (3DGS) offers a promising direction by enabling high-quality, real-time rendering through explicit Gaussian primitives. However, existing 3DGS-based methods for dynamic reconstruction often suffer from \textit{spatio-temporal incoherence} during initialization, where canonical Gaussians are constructed by aggregating observations from multiple frames without temporal distinction. This results in spatio-temporally entangled representations, making it difficult to model dynamic motion accurately. To overcome this limitation, we propose \textbf{STDR} (Spatio-Temporal Decoupling for Real-time rendering), a plug-and-play module that learns spatio-temporal probability distributions for each Gaussian. STDR introduces a spatio-temporal mask, a separated deformation field, and a consistency regularization to jointly disentangle spatial and temporal patterns. Extensive experiments demonstrate that incorporating our module into existing 3DGS-based dynamic scene reconstruction frameworks leads to notable improvements in both reconstruction quality and spatio-temporal consistency across synthetic and real-world benchmarks.
SED-MVS: Segmentation-Driven and Edge-Aligned Deformation Multi-View Stereo with Depth Restoration and Occlusion Constraint
Mar 17, 2025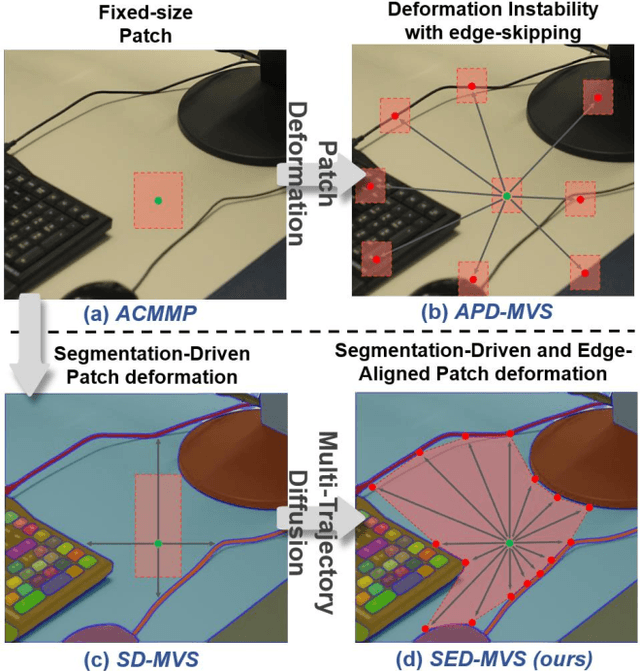
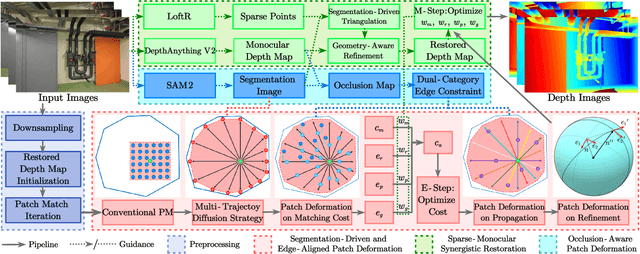
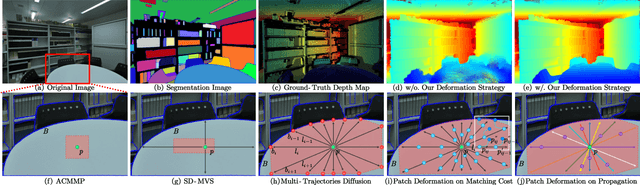

Recently, patch-deformation methods have exhibited significant effectiveness in multi-view stereo owing to the deformable and expandable patches in reconstructing textureless areas. However, such methods primarily emphasize broadening the receptive field in textureless areas, while neglecting deformation instability caused by easily overlooked edge-skipping, potentially leading to matching distortions. To address this, we propose SED-MVS, which adopts panoptic segmentation and multi-trajectory diffusion strategy for segmentation-driven and edge-aligned patch deformation. Specifically, to prevent unanticipated edge-skipping, we first employ SAM2 for panoptic segmentation as depth-edge guidance to guide patch deformation, followed by multi-trajectory diffusion strategy to ensure patches are comprehensively aligned with depth edges. Moreover, to avoid potential inaccuracy of random initialization, we combine both sparse points from LoFTR and monocular depth map from DepthAnything V2 to restore reliable and realistic depth map for initialization and supervised guidance. Finally, we integrate segmentation image with monocular depth map to exploit inter-instance occlusion relationship, then further regard them as occlusion map to implement two distinct edge constraint, thereby facilitating occlusion-aware patch deformation. Extensive results on ETH3D, Tanks & Temples, BlendedMVS and Strecha datasets validate the state-of-the-art performance and robust generalization capability of our proposed method.
Dual-Level Precision Edges Guided Multi-View Stereo with Accurate Planarization
Dec 29, 2024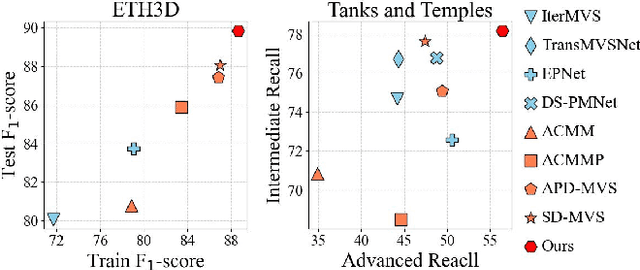
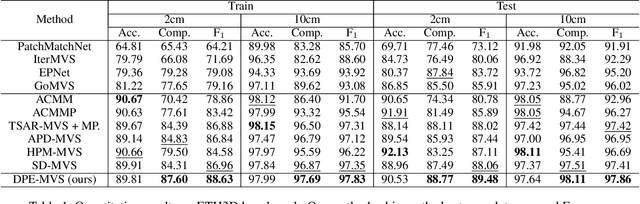

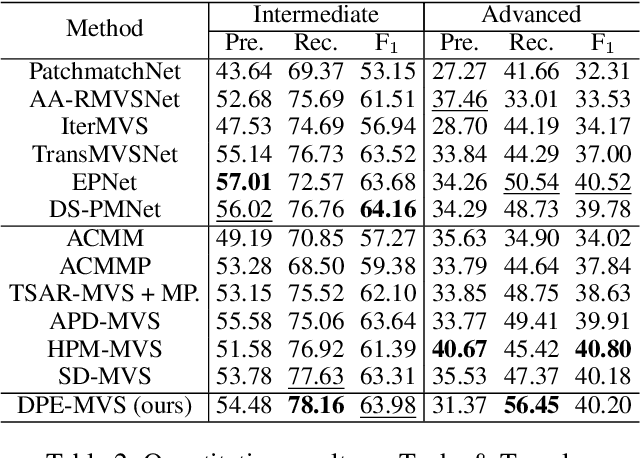
The reconstruction of low-textured areas is a prominent research focus in multi-view stereo (MVS). In recent years, traditional MVS methods have performed exceptionally well in reconstructing low-textured areas by constructing plane models. However, these methods often encounter issues such as crossing object boundaries and limited perception ranges, which undermine the robustness of plane model construction. Building on previous work (APD-MVS), we propose the DPE-MVS method. By introducing dual-level precision edge information, including fine and coarse edges, we enhance the robustness of plane model construction, thereby improving reconstruction accuracy in low-textured areas. Furthermore, by leveraging edge information, we refine the sampling strategy in conventional PatchMatch MVS and propose an adaptive patch size adjustment approach to optimize matching cost calculation in both stochastic and low-textured areas. This additional use of edge information allows for more precise and robust matching. Our method achieves state-of-the-art performance on the ETH3D and Tanks & Temples benchmarks. Notably, our method outperforms all published methods on the ETH3D benchmark.
DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo
Dec 16, 2024Patch deformation-based methods have recently exhibited substantial effectiveness in multi-view stereo, due to the incorporation of deformable and expandable perception to reconstruct textureless areas. However, such approaches typically focus on exploring correlative reliable pixels to alleviate match ambiguity during patch deformation, but ignore the deformation instability caused by mistaken edge-skipping and visibility occlusion, leading to potential estimation deviation. To remedy the above issues, we propose DVP-MVS, which innovatively synergizes depth-edge aligned and cross-view prior for robust and visibility-aware patch deformation. Specifically, to avoid unexpected edge-skipping, we first utilize Depth Anything V2 followed by the Roberts operator to initialize coarse depth and edge maps respectively, both of which are further aligned through an erosion-dilation strategy to generate fine-grained homogeneous boundaries for guiding patch deformation. In addition, we reform view selection weights as visibility maps and restore visible areas by cross-view depth reprojection, then regard them as cross-view prior to facilitate visibility-aware patch deformation. Finally, we improve propagation and refinement with multi-view geometry consistency by introducing aggregated visible hemispherical normals based on view selection and local projection depth differences based on epipolar lines, respectively. Extensive evaluations on ETH3D and Tanks & Temples benchmarks demonstrate that our method can achieve state-of-the-art performance with excellent robustness and generalization.
GradiSeg: Gradient-Guided Gaussian Segmentation with Enhanced 3D Boundary Precision
Nov 30, 2024While 3D Gaussian Splatting enables high-quality real-time rendering, existing Gaussian-based frameworks for 3D semantic segmentation still face significant challenges in boundary recognition accuracy. To address this, we propose a novel 3DGS-based framework named GradiSeg, incorporating Identity Encoding to construct a deeper semantic understanding of scenes. Our approach introduces two key modules: Identity Gradient Guided Densification (IGD) and Local Adaptive K-Nearest Neighbors (LA-KNN). The IGD module supervises gradients of Identity Encoding to refine Gaussian distributions along object boundaries, aligning them closely with boundary contours. Meanwhile, the LA-KNN module employs position gradients to adaptively establish locality-aware propagation of Identity Encodings, preventing irregular Gaussian spreads near boundaries. We validate the effectiveness of our method through comprehensive experiments. Results show that GradiSeg effectively addresses boundary-related issues, significantly improving segmentation accuracy without compromising scene reconstruction quality. Furthermore, our method's robust segmentation capability and decoupled Identity Encoding representation make it highly suitable for various downstream scene editing tasks, including 3D object removal, swapping and so on.
MSP-MVS: Multi-granularity Segmentation Prior Guided Multi-View Stereo
Jul 27, 2024Reconstructing textureless areas in MVS poses challenges due to the absence of reliable pixel correspondences within fixed patch. Although certain methods employ patch deformation to expand the receptive field, their patches mistakenly skip depth edges to calculate areas with depth discontinuity, thereby causing ambiguity. Consequently, we introduce Multi-granularity Segmentation Prior Multi-View Stereo (MSP-MVS). Specifically, we first propose multi-granularity segmentation prior by integrating multi-granularity depth edges to restrict patch deformation within homogeneous areas. Moreover, we present anchor equidistribution that bring deformed patches with more uniformly distributed anchors to ensure an adequate coverage of their own homogeneous areas. Furthermore, we introduce iterative local search optimization to represent larger patch with sparse representative candidates, significantly boosting the expressive capacity for each patch. The state-of-the-art results on ETH3D and Tanks & Temples benchmarks demonstrate the effectiveness and robust generalization ability of our proposed method.
Deep Learning-based Anomaly Detection and Log Analysis for Computer Networks
Jul 08, 2024Computer network anomaly detection and log analysis, as an important topic in the field of network security, has been a key task to ensure network security and system reliability. First, existing network anomaly detection and log analysis methods are often challenged by high-dimensional data and complex network topologies, resulting in unstable performance and high false-positive rates. In addition, traditional methods are usually difficult to handle time-series data, which is crucial for anomaly detection and log analysis. Therefore, we need a more efficient and accurate method to cope with these problems. To compensate for the shortcomings of current methods, we propose an innovative fusion model that integrates Isolation Forest, GAN (Generative Adversarial Network), and Transformer with each other, and each of them plays a unique role. Isolation Forest is used to quickly identify anomalous data points, and GAN is used to generate synthetic data with the real data distribution characteristics to augment the training dataset, while the Transformer is used for modeling and context extraction on time series data. The synergy of these three components makes our model more accurate and robust in anomaly detection and log analysis tasks. We validate the effectiveness of this fusion model in an extensive experimental evaluation. Experimental results show that our model significantly improves the accuracy of anomaly detection while reducing the false alarm rate, which helps to detect potential network problems in advance. The model also performs well in the log analysis task and is able to quickly identify anomalous behaviors, which helps to improve the stability of the system. The significance of this study is that it introduces advanced deep learning techniques, which work anomaly detection and log analysis.