 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI-MFM: Physics-informed multimodal foundation model for solving partial differential equations
Dec 28, 2025Partial differential equations (PDEs) govern a wide range of physical systems, and recent multimodal foundation models have shown promise for learning PDE solution operators across diverse equation families. However, existing multi-operator learning approaches are data-hungry and neglect physics during training. Here, we propose a physics-informed multimodal foundation model (PI-MFM) framework that directly enforces governing equations during pretraining and adaptation. PI-MFM takes symbolic representations of PDEs as the input, and automatically assembles PDE residual losses from the input expression via a vectorized derivative computation. These designs enable any PDE-encoding multimodal foundation model to be trained or adapted with unified physics-informed objectives across equation families. On a benchmark of 13 parametric one-dimensional time-dependent PDE families, PI-MFM consistently outperforms purely data-driven counterparts, especially with sparse labeled spatiotemporal points, partially observed time domains, or few labeled function pairs. Physics losses further improve robustness against noise, and simple strategies such as resampling collocation points substantially improve accuracy. We also analyze the accuracy, precision, and computational cost of automatic differentiation and finite differences for derivative computation within PI-MFM. Finally, we demonstrate zero-shot physics-informed fine-tuning to unseen PDE families: starting from a physics-informed pretrained model, adapting using only PDE residuals and initial/boundary conditions, without any labeled solution data, rapidly reduces test errors to around 1% and clearly outperforms physics-only training from scratch. These results show that PI-MFM provides a practical and scalable path toward data-efficient, transferable PDE solvers.
Deep Neural Operator Learning for Probabilistic Models
Nov 10, 2025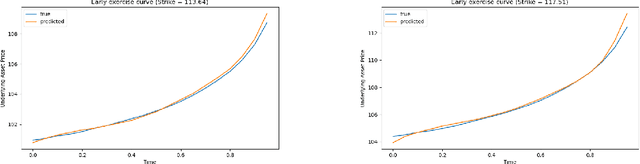
We propose a deep neural-operator framework for a general class of probability models. Under global Lipschitz conditions on the operator over the entire Euclidean space-and for a broad class of probabilistic models-we establish a universal approximation theorem with explicit network-size bounds for the proposed architecture. The underlying stochastic processes are required only to satisfy integrability and general tail-probability conditions. We verify these assumptions for both European and American option-pricing problems within the forward-backward SDE (FBSDE) framework, which in turn covers a broad class of operators arising from parabolic PDEs, with or without free boundaries. Finally, we present a numerical example for a basket of American options, demonstrating that the learned model produces optimal stopping boundaries for new strike prices without retraining.
PyG 2.0: Scalable Learning on Real World Graphs
Jul 22, 2025PyG (PyTorch Geometric) has evolved significantly since its initial release, establishing itself as a leading framework for Graph Neural Networks. In this paper, we present Pyg 2.0 (and its subsequent minor versions), a comprehensive update that introduces substantial improvements in scalability and real-world application capabilities. We detail the framework's enhanced architecture, including support for heterogeneous and temporal graphs, scalable feature/graph stores, and various optimizations, enabling researchers and practitioners to tackle large-scale graph learning problems efficiently. Over the recent years, PyG has been supporting graph learning in a large variety of application areas, which we will summarize, while providing a deep dive into the important areas of relational deep learning and large language modeling.
Coefficient-to-Basis Network: A Fine-Tunable Operator Learning Framework for Inverse Problems with Adaptive Discretizations and Theoretical Guarantees
Mar 11, 2025We propose a Coefficient-to-Basis Network (C2BNet), a novel framework for solving inverse problems within the operator learning paradigm. C2BNet efficiently adapts to different discretizations through fine-tuning, using a pre-trained model to significantly reduce computational cost while maintaining high accuracy. Unlike traditional approaches that require retraining from scratch for new discretizations, our method enables seamless adaptation without sacrificing predictive performance. Furthermore, we establish theoretical approximation and generalization error bounds for C2BNet by exploiting low-dimensional structures in the underlying datasets. Our analysis demonstrates that C2BNet adapts to low-dimensional structures without relying on explicit encoding mechanisms, highlighting its robustness and efficiency. To validate our theoretical findings, we conducted extensive numerical experiments that showcase the superior performance of C2BNet on several inverse problems. The results confirm that C2BNet effectively balances computational efficiency and accuracy, making it a promising tool to solve inverse problems in scientific computing and engineering applications.
VLMs Play StarCraft II: A Benchmark and Multimodal Decision Method
Mar 07, 2025We introduce VLM-Attention, a multimodal StarCraft II environment that aligns artificial agent perception with the human gameplay experience. Traditional frameworks such as SMAC rely on abstract state representations that diverge significantly from human perception, limiting the ecological validity of agent behavior. Our environment addresses this limitation by incorporating RGB visual inputs and natural language observations that more closely simulate human cognitive processes during gameplay. The VLM-Attention framework consists of three integrated components: (1) a vision-language model enhanced with specialized self-attention mechanisms for strategic unit targeting and battlefield assessment, (2) a retrieval-augmented generation system that leverages domain-specific StarCraft II knowledge to inform tactical decisions, and (3) a dynamic role-based task distribution system that enables coordinated multi-agent behavior. Our experimental evaluation across 21 custom scenarios demonstrates that VLM-based agents powered by foundation models (specifically Qwen-VL and GPT-4o) can execute complex tactical maneuvers without explicit training, achieving comparable performance to traditional MARL methods that require substantial training iterations. This work establishes a foundation for developing human-aligned StarCraft II agents and advances the broader research agenda of multimodal game AI. Our implementation is available at https://github.com/camel-ai/VLM-Play-StarCraft2.
CCS: Controllable and Constrained Sampling with Diffusion Models via Initial Noise Perturbation
Feb 07, 2025



Diffusion models have emerged as powerful tools for generative tasks, producing high-quality outputs across diverse domains. However, how the generated data responds to the initial noise perturbation in diffusion models remains under-explored, which hinders understanding the controllability of the sampling process. In this work, we first observe an interesting phenomenon: the relationship between the change of generation outputs and the scale of initial noise perturbation is highly linear through the diffusion ODE sampling. Then we provide both theoretical and empirical study to justify this linearity property of this input-output (noise-generation data) relationship. Inspired by these new insights, we propose a novel Controllable and Constrained Sampling method (CCS) together with a new controller algorithm for diffusion models to sample with desired statistical properties while preserving good sample quality. We perform extensive experiments to compare our proposed sampling approach with other methods on both sampling controllability and sampled data quality. Results show that our CCS method achieves more precisely controlled sampling while maintaining superior sample quality and diversity.
ContextGNN: Beyond Two-Tower Recommendation Systems
Nov 29, 2024



Recommendation systems predominantly utilize two-tower architectures, which evaluate user-item rankings through the inner product of their respective embeddings. However, one key limitation of two-tower models is that they learn a pair-agnostic representation of users and items. In contrast, pair-wise representations either scale poorly due to their quadratic complexity or are too restrictive on the candidate pairs to rank. To address these issues, we introduce Context-based Graph Neural Networks (ContextGNNs), a novel deep learning architecture for link prediction in recommendation systems. The method employs a pair-wise representation technique for familiar items situated within a user's local subgraph, while leveraging two-tower representations to facilitate the recommendation of exploratory items. A final network then predicts how to fuse both pair-wise and two-tower recommendations into a single ranking of items. We demonstrate that ContextGNN is able to adapt to different data characteristics and outperforms existing methods, both traditional and GNN-based, on a diverse set of practical recommendation tasks, improving performance by 20% on average.
DeepONet as a Multi-Operator Extrapolation Model: Distributed Pretraining with Physics-Informed Fine-Tuning
Nov 11, 2024We propose a novel fine-tuning method to achieve multi-operator learning through training a distributed neural operator with diverse function data and then zero-shot fine-tuning the neural network using physics-informed losses for downstream tasks. Operator learning effectively approximates solution operators for PDEs and various PDE-related problems, yet it often struggles to generalize to new tasks. To address this, we investigate fine-tuning a pretrained model, while carefully selecting an initialization that enables rapid adaptation to new tasks with minimal data. Our approach combines distributed learning to integrate data from various operators in pre-training, while physics-informed methods enable zero-shot fine-tuning, minimizing the reliance on downstream data. We investigate standard fine-tuning and Low-Rank Adaptation fine-tuning, applying both to train complex nonlinear target operators that are difficult to learn only using random initialization. Through comprehensive numerical examples, we demonstrate the advantages of our approach, showcasing significant improvements in accuracy. Our findings provide a robust framework for advancing multi-operator learning and highlight the potential of transfer learning techniques in this domain.
Time-Series Forecasting, Knowledge Distillation, and Refinement within a Multimodal PDE Foundation Model
Sep 17, 2024



Symbolic encoding has been used in multi-operator learning as a way to embed additional information for distinct time-series data. For spatiotemporal systems described by time-dependent partial differential equations, the equation itself provides an additional modality to identify the system. The utilization of symbolic expressions along side time-series samples allows for the development of multimodal predictive neural networks. A key challenge with current approaches is that the symbolic information, i.e. the equations, must be manually preprocessed (simplified, rearranged, etc.) to match and relate to the existing token library, which increases costs and reduces flexibility, especially when dealing with new differential equations. We propose a new token library based on SymPy to encode differential equations as an additional modality for time-series models. The proposed approach incurs minimal cost, is automated, and maintains high prediction accuracy for forecasting tasks. Additionally, we include a Bayesian filtering module that connects the different modalities to refine the learned equation. This improves the accuracy of the learned symbolic representation and the predicted time-series.
PROSE-FD: A Multimodal PDE Foundation Model for Learning Multiple Operators for Forecasting Fluid Dynamics
Sep 15, 2024We propose PROSE-FD, a zero-shot multimodal PDE foundational model for simultaneous prediction of heterogeneous two-dimensional physical systems related to distinct fluid dynamics settings. These systems include shallow water equations and the Navier-Stokes equations with incompressible and compressible flow, regular and complex geometries, and different buoyancy settings. This work presents a new transformer-based multi-operator learning approach that fuses symbolic information to perform operator-based data prediction, i.e. non-autoregressive. By incorporating multiple modalities in the inputs, the PDE foundation model builds in a pathway for including mathematical descriptions of the physical behavior. We pre-train our foundation model on 6 parametric families of equations collected from 13 datasets, including over 60K trajectories. Our model outperforms popular operator learning, computer vision, and multi-physics models, in benchmark forward prediction tasks. We test our architecture choices with ablation studies.