 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelBench v2: A Large-Scale Benchmark and Repository for Relational Data
Feb 13, 2026Relational deep learning (RDL) has emerged as a powerful paradigm for learning directly on relational databases by modeling entities and their relationships across multiple interconnected tables. As this paradigm evolves toward larger models and relational foundation models, scalable and realistic benchmarks are essential for enabling systematic evaluation and progress. In this paper, we introduce RelBench v2, a major expansion of the RelBench benchmark for RDL. RelBench v2 adds four large-scale relational datasets spanning scholarly publications, enterprise resource planning, consumer platforms, and clinical records, increasing the benchmark to 11 datasets comprising over 22 million rows across 29 tables. We further introduce autocomplete tasks, a new class of predictive objectives that require models to infer missing attribute values directly within relational tables while respecting temporal constraints, expanding beyond traditional forecasting tasks constructed via SQL queries. In addition, RelBench v2 expands beyond its native datasets by integrating external benchmarks and evaluation frameworks: we translate event streams from the Temporal Graph Benchmark into relational schemas for unified relational-temporal evaluation, interface with ReDeLEx to provide uniform access to 70+ real-world databases suitable for pretraining, and incorporate 4DBInfer datasets and tasks to broaden multi-table prediction coverage. Experimental results demonstrate that RDL models consistently outperform single-table baselines across autocomplete, forecasting, and recommendation tasks, highlighting the importance of modeling relational structure explicitly.
PluRel: Synthetic Data unlocks Scaling Laws for Relational Foundation Models
Feb 03, 2026Relational Foundation Models (RFMs) facilitate data-driven decision-making by learning from complex multi-table databases. However, the diverse relational databases needed to train such models are rarely public due to privacy constraints. While there are methods to generate synthetic tabular data of arbitrary size, incorporating schema structure and primary--foreign key connectivity for multi-table generation remains challenging. Here we introduce PluRel, a framework to synthesize multi-tabular relational databases from scratch. In a step-by-step fashion, PluRel models (1) schemas with directed graphs, (2) inter-table primary-foreign key connectivity with bipartite graphs, and, (3) feature distributions in tables via conditional causal mechanisms. The design space across these stages supports the synthesis of a wide range of diverse databases, while being computationally lightweight. Using PluRel, we observe for the first time that (1) RFM pretraining loss exhibits power-law scaling with the number of synthetic databases and total pretraining tokens, (2) scaling the number of synthetic databases improves generalization to real databases, and (3) synthetic pretraining yields strong base models for continued pretraining on real databases. Overall, our framework and results position synthetic data scaling as a promising paradigm for RFMs.
Multimodal Zero-Shot Framework for Deepfake Hate Speech Detection in Low-Resource Languages
Jun 10, 2025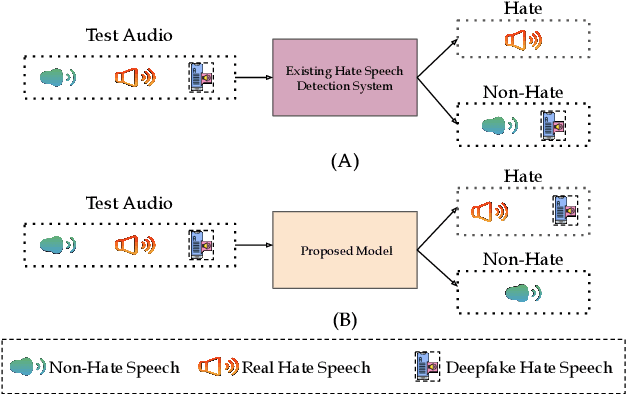
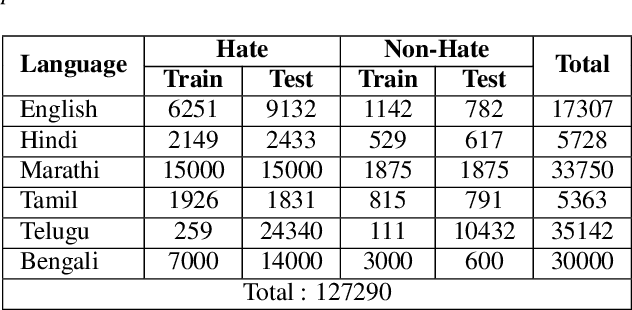
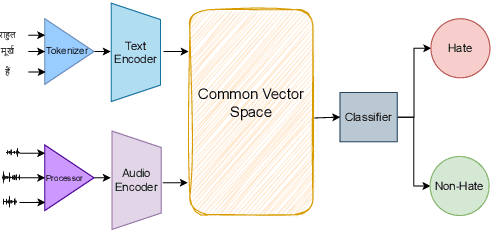
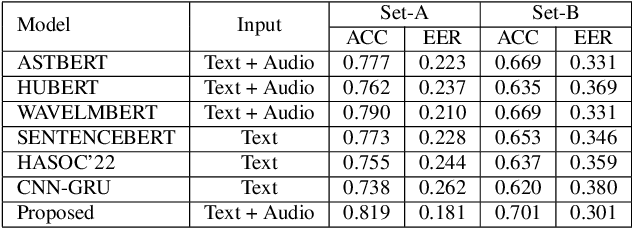
This paper introduces a novel multimodal framework for hate speech detection in deepfake audio, excelling even in zero-shot scenarios. Unlike previous approaches, our method uses contrastive learning to jointly align audio and text representations across languages. We present the first benchmark dataset with 127,290 paired text and synthesized speech samples in six languages: English and five low-resource Indian languages (Hindi, Bengali, Marathi, Tamil, Telugu). Our model learns a shared semantic embedding space, enabling robust cross-lingual and cross-modal classification. Experiments on two multilingual test sets show our approach outperforms baselines, achieving accuracies of 0.819 and 0.701, and generalizes well to unseen languages. This demonstrates the advantage of combining modalities for hate speech detection in synthetic media, especially in low-resource settings where unimodal models falter. The Dataset is available at https://www.iab-rubric.org/resources.
SynHate: Detecting Hate Speech in Synthetic Deepfake Audio
Jun 07, 2025The rise of deepfake audio and hate speech, powered by advanced text-to-speech, threatens online safety. We present SynHate, the first multilingual dataset for detecting hate speech in synthetic audio, spanning 37 languages. SynHate uses a novel four-class scheme: Real-normal, Real-hate, Fake-normal, and Fake-hate. Built from MuTox and ADIMA datasets, it captures diverse hate speech patterns globally and in India. We evaluate five leading self-supervised models (Whisper-small/medium, XLS-R, AST, mHuBERT), finding notable performance differences by language, with Whisper-small performing best overall. Cross-dataset generalization remains a challenge. By releasing SynHate and baseline code, we aim to advance robust, culturally sensitive, and multilingual solutions against synthetic hate speech. The dataset is available at https://www.iab-rubric.org/resources.
Can Quantized Audio Language Models Perform Zero-Shot Spoofing Detection?
Jun 07, 2025Quantization is essential for deploying large audio language models (LALMs) efficiently in resource-constrained environments. However, its impact on complex tasks, such as zero-shot audio spoofing detection, remains underexplored. This study evaluates the zero-shot capabilities of five LALMs, GAMA, LTU-AS, MERaLiON, Qwen-Audio, and SALMONN, across three distinct datasets: ASVspoof2019, In-the-Wild, and WaveFake, and investigates their robustness to quantization (FP32, FP16, INT8). Despite high initial spoof detection accuracy, our analysis demonstrates severe predictive biases toward spoof classification across all models, rendering their practical performance equivalent to random classification. Interestingly, quantization to FP16 precision resulted in negligible performance degradation compared to FP32, effectively halving memory and computational requirements without materially impacting accuracy. However, INT8 quantization intensified model biases, significantly degrading balanced accuracy. These findings highlight critical architectural limitations and emphasize FP16 quantization as an optimal trade-off, providing guidelines for practical deployment and future model refinement.
LitMAS: A Lightweight and Generalized Multi-Modal Anti-Spoofing Framework for Biometric Security
Jun 07, 2025Biometric authentication systems are increasingly being deployed in critical applications, but they remain susceptible to spoofing. Since most of the research efforts focus on modality-specific anti-spoofing techniques, building a unified, resource-efficient solution across multiple biometric modalities remains a challenge. To address this, we propose LitMAS, a $\textbf{Li}$gh$\textbf{t}$ weight and generalizable $\textbf{M}$ulti-modal $\textbf{A}$nti-$\textbf{S}$poofing framework designed to detect spoofing attacks in speech, face, iris, and fingerprint-based biometric systems. At the core of LitMAS is a Modality-Aligned Concentration Loss, which enhances inter-class separability while preserving cross-modal consistency and enabling robust spoof detection across diverse biometric traits. With just 6M parameters, LitMAS surpasses state-of-the-art methods by $1.36\%$ in average EER across seven datasets, demonstrating high efficiency, strong generalizability, and suitability for edge deployment. Code and trained models are available at https://github.com/IAB-IITJ/LitMAS.
RelBench: A Benchmark for Deep Learning on Relational Databases
Jul 29, 2024
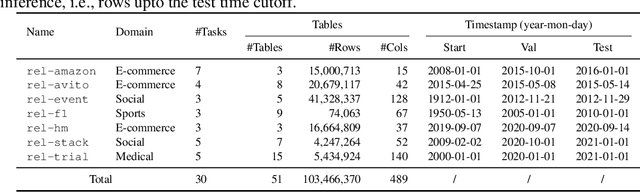


We present RelBench, a public benchmark for solving predictive tasks over relational databases with graph neural networks. RelBench provides databases and tasks spanning diverse domains and scales, and is intended to be a foundational infrastructure for future research. We use RelBench to conduct the first comprehensive study of Relational Deep Learning (RDL) (Fey et al., 2024), which combines graph neural network predictive models with (deep) tabular models that extract initial entity-level representations from raw tables. End-to-end learned RDL models fully exploit the predictive signal encoded in primary-foreign key links, marking a significant shift away from the dominant paradigm of manual feature engineering combined with tabular models. To thoroughly evaluate RDL against this prior gold-standard, we conduct an in-depth user study where an experienced data scientist manually engineers features for each task. In this study, RDL learns better models whilst reducing human work needed by more than an order of magnitude. This demonstrates the power of deep learning for solving predictive tasks over relational databases, opening up many new research opportunities enabled by RelBench.
Low-Resolution Chest X-ray Classification via Knowledge Distillation and Multi-task Learning
May 22, 2024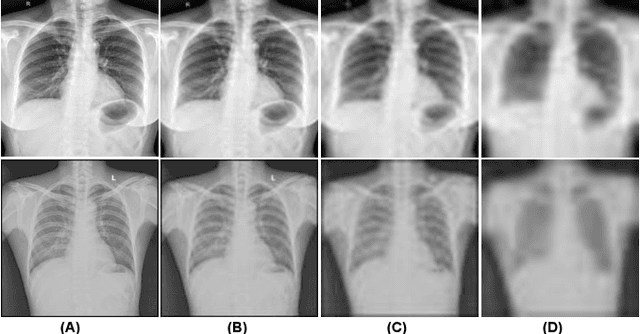


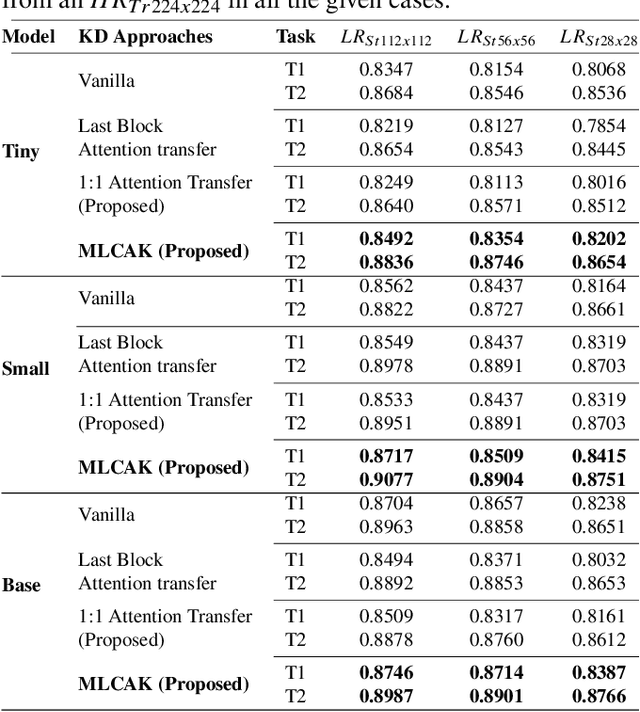
This research addresses the challenges of diagnosing chest X-rays (CXRs) at low resolutions, a common limitation in resource-constrained healthcare settings. High-resolution CXR imaging is crucial for identifying small but critical anomalies, such as nodules or opacities. However, when images are downsized for processing in Computer-Aided Diagnosis (CAD) systems, vital spatial details and receptive fields are lost, hampering diagnosis accuracy. To address this, this paper presents the Multilevel Collaborative Attention Knowledge (MLCAK) method. This approach leverages the self-attention mechanism of Vision Transformers (ViT) to transfer critical diagnostic knowledge from high-resolution images to enhance the diagnostic efficacy of low-resolution CXRs. MLCAK incorporates local pathological findings to boost model explainability, enabling more accurate global predictions in a multi-task framework tailored for low-resolution CXR analysis. Our research, utilizing the Vindr CXR dataset, shows a considerable enhancement in the ability to diagnose diseases from low-resolution images (e.g. 28 x 28), suggesting a critical transition from the traditional reliance on high-resolution imaging (e.g. 224 x 224).
Post-Hoc Reversal: Are We Selecting Models Prematurely?
Apr 11, 2024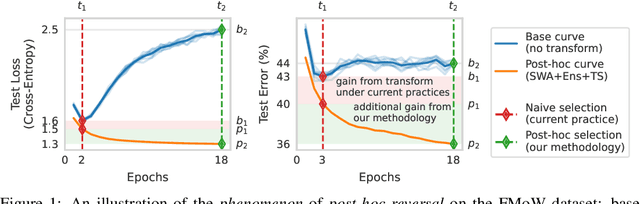
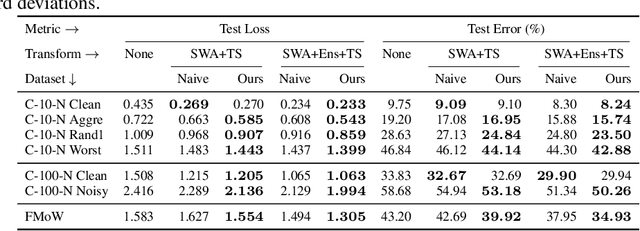
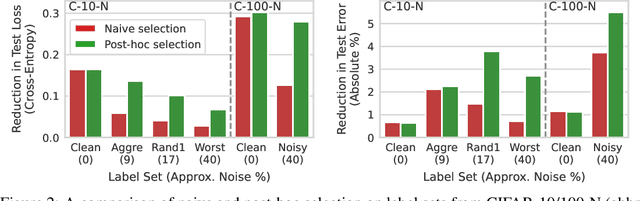

Trained models are often composed with post-hoc transforms such as temperature scaling (TS), ensembling and stochastic weight averaging (SWA) to improve performance, robustness, uncertainty estimation, etc. However, such transforms are typically applied only after the base models have already been finalized by standard means. In this paper, we challenge this practice with an extensive empirical study. In particular, we demonstrate a phenomenon that we call post-hoc reversal, where performance trends are reversed after applying these post-hoc transforms. This phenomenon is especially prominent in high-noise settings. For example, while base models overfit badly early in training, both conventional ensembling and SWA favor base models trained for more epochs. Post-hoc reversal can also suppress the appearance of double descent and mitigate mismatches between test loss and test error seen in base models. Based on our findings, we propose post-hoc selection, a simple technique whereby post-hoc metrics inform model development decisions such as early stopping, checkpointing, and broader hyperparameter choices. Our experimental analyses span real-world vision, language, tabular and graph datasets from domains like satellite imaging, language modeling, census prediction and social network analysis. On an LLM instruction tuning dataset, post-hoc selection results in > 1.5x MMLU improvement compared to naive selection. Code is available at https://github.com/rishabh-ranjan/post-hoc-reversal.
Relational Deep Learning: Graph Representation Learning on Relational Databases
Dec 07, 2023
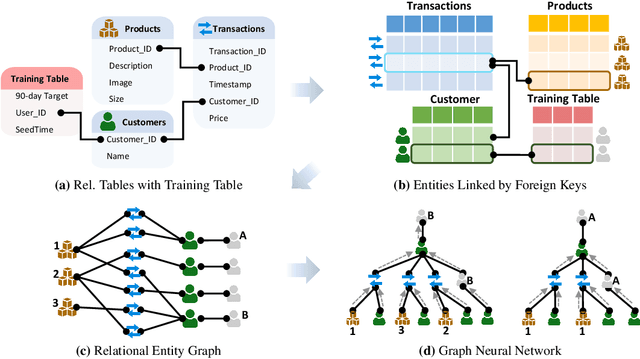


Much of the world's most valued data is stored in relational databases and data warehouses, where the data is organized into many tables connected by primary-foreign key relations. However, building machine learning models using this data is both challenging and time consuming. The core problem is that no machine learning method is capable of learning on multiple tables interconnected by primary-foreign key relations. Current methods can only learn from a single table, so the data must first be manually joined and aggregated into a single training table, the process known as feature engineering. Feature engineering is slow, error prone and leads to suboptimal models. Here we introduce an end-to-end deep representation learning approach to directly learn on data laid out across multiple tables. We name our approach Relational Deep Learning (RDL). The core idea is to view relational databases as a temporal, heterogeneous graph, with a node for each row in each table, and edges specified by primary-foreign key links. Message Passing Graph Neural Networks can then automatically learn across the graph to extract representations that leverage all input data, without any manual feature engineering. Relational Deep Learning leads to more accurate models that can be built much faster. To facilitate research in this area, we develop RelBench, a set of benchmark datasets and an implementation of Relational Deep Learning. The data covers a wide spectrum, from discussions on Stack Exchange to book reviews on the Amazon Product Catalog. Overall, we define a new research area that generalizes graph machine learning and broadens its applicability to a wide set of AI use cases.