 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards characterizing the value of edge embeddings in Graph Neural Networks
Oct 13, 2024Graph neural networks (GNNs) are the dominant approach to solving machine learning problems defined over graphs. Despite much theoretical and empirical work in recent years, our understanding of finer-grained aspects of architectural design for GNNs remains impoverished. In this paper, we consider the benefits of architectures that maintain and update edge embeddings. On the theoretical front, under a suitable computational abstraction for a layer in the model, as well as memory constraints on the embeddings, we show that there are natural tasks on graphical models for which architectures leveraging edge embeddings can be much shallower. Our techniques are inspired by results on time-space tradeoffs in theoretical computer science. Empirically, we show architectures that maintain edge embeddings almost always improve on their node-based counterparts -- frequently significantly so in topologies that have ``hub'' nodes.
Post-Hoc Reversal: Are We Selecting Models Prematurely?
Apr 11, 2024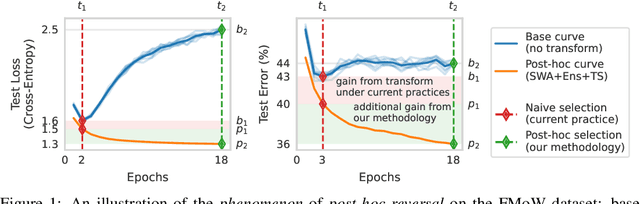
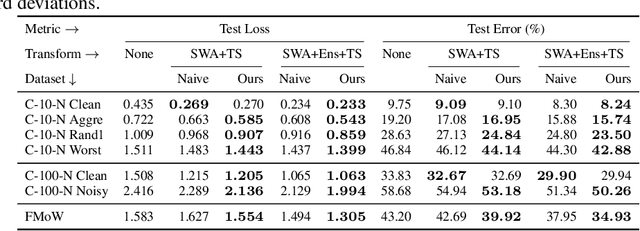
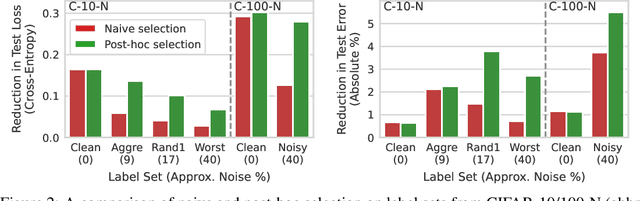

Trained models are often composed with post-hoc transforms such as temperature scaling (TS), ensembling and stochastic weight averaging (SWA) to improve performance, robustness, uncertainty estimation, etc. However, such transforms are typically applied only after the base models have already been finalized by standard means. In this paper, we challenge this practice with an extensive empirical study. In particular, we demonstrate a phenomenon that we call post-hoc reversal, where performance trends are reversed after applying these post-hoc transforms. This phenomenon is especially prominent in high-noise settings. For example, while base models overfit badly early in training, both conventional ensembling and SWA favor base models trained for more epochs. Post-hoc reversal can also suppress the appearance of double descent and mitigate mismatches between test loss and test error seen in base models. Based on our findings, we propose post-hoc selection, a simple technique whereby post-hoc metrics inform model development decisions such as early stopping, checkpointing, and broader hyperparameter choices. Our experimental analyses span real-world vision, language, tabular and graph datasets from domains like satellite imaging, language modeling, census prediction and social network analysis. On an LLM instruction tuning dataset, post-hoc selection results in > 1.5x MMLU improvement compared to naive selection. Code is available at https://github.com/rishabh-ranjan/post-hoc-reversal.
Complementary Benefits of Contrastive Learning and Self-Training Under Distribution Shift
Dec 06, 2023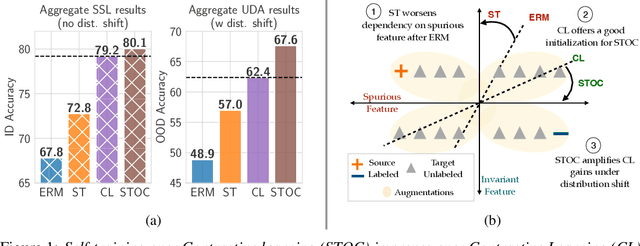
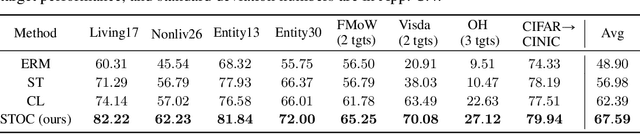

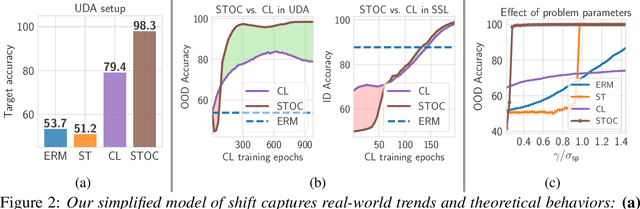
Self-training and contrastive learning have emerged as leading techniques for incorporating unlabeled data, both under distribution shift (unsupervised domain adaptation) and when it is absent (semi-supervised learning). However, despite the popularity and compatibility of these techniques, their efficacy in combination remains unexplored. In this paper, we undertake a systematic empirical investigation of this combination, finding that (i) in domain adaptation settings, self-training and contrastive learning offer significant complementary gains; and (ii) in semi-supervised learning settings, surprisingly, the benefits are not synergistic. Across eight distribution shift datasets (e.g., BREEDs, WILDS), we demonstrate that the combined method obtains 3--8% higher accuracy than either approach independently. We then theoretically analyze these techniques in a simplified model of distribution shift, demonstrating scenarios under which the features produced by contrastive learning can yield a good initialization for self-training to further amplify gains and achieve optimal performance, even when either method alone would fail.
Online Label Shift: Optimal Dynamic Regret meets Practical Algorithms
May 31, 2023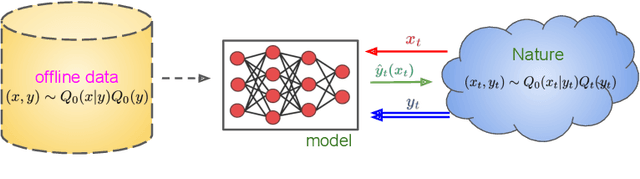
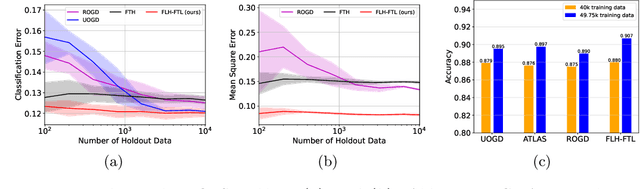
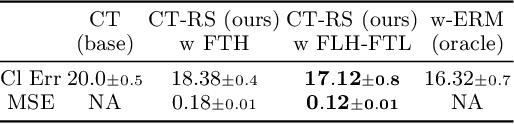
This paper focuses on supervised and unsupervised online label shift, where the class marginals $Q(y)$ varies but the class-conditionals $Q(x|y)$ remain invariant. In the unsupervised setting, our goal is to adapt a learner, trained on some offline labeled data, to changing label distributions given unlabeled online data. In the supervised setting, we must both learn a classifier and adapt to the dynamically evolving class marginals given only labeled online data. We develop novel algorithms that reduce the adaptation problem to online regression and guarantee optimal dynamic regret without any prior knowledge of the extent of drift in the label distribution. Our solution is based on bootstrapping the estimates of \emph{online regression oracles} that track the drifting proportions. Experiments across numerous simulated and real-world online label shift scenarios demonstrate the superior performance of our proposed approaches, often achieving 1-3\% improvement in accuracy while being sample and computationally efficient. Code is publicly available at https://github.com/acmi-lab/OnlineLabelShift.
Off-Policy Risk Assessment in Markov Decision Processes
Sep 21, 2022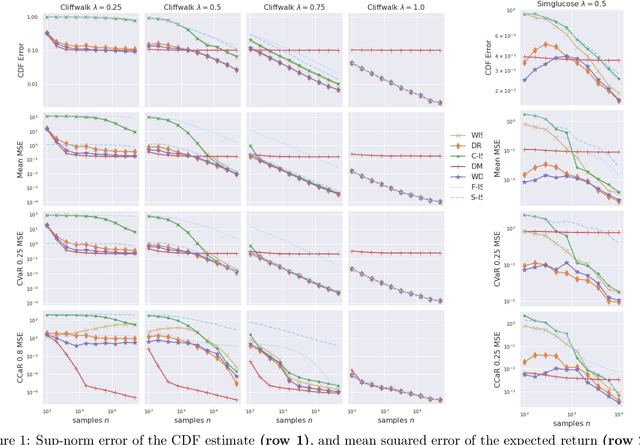
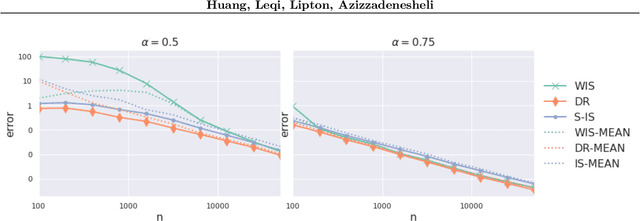
Addressing such diverse ends as safety alignment with human preferences, and the efficiency of learning, a growing line of reinforcement learning research focuses on risk functionals that depend on the entire distribution of returns. Recent work on \emph{off-policy risk assessment} (OPRA) for contextual bandits introduced consistent estimators for the target policy's CDF of returns along with finite sample guarantees that extend to (and hold simultaneously over) all risk. In this paper, we lift OPRA to Markov decision processes (MDPs), where importance sampling (IS) CDF estimators suffer high variance on longer trajectories due to small effective sample size. To mitigate these problems, we incorporate model-based estimation to develop the first doubly robust (DR) estimator for the CDF of returns in MDPs. This estimator enjoys significantly less variance and, when the model is well specified, achieves the Cramer-Rao variance lower bound. Moreover, for many risk functionals, the downstream estimates enjoy both lower bias and lower variance. Additionally, we derive the first minimax lower bounds for off-policy CDF and risk estimation, which match our error bounds up to a constant factor. Finally, we demonstrate the precision of our DR CDF estimates experimentally on several different environments.
Temporal-Clustering Invariance in Irregular Healthcare Time Series
Apr 27, 2019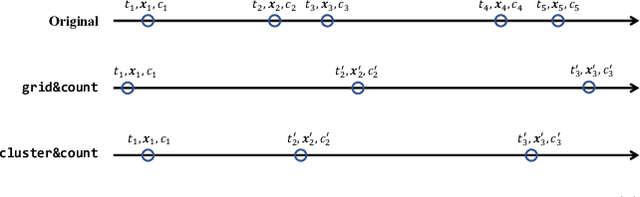

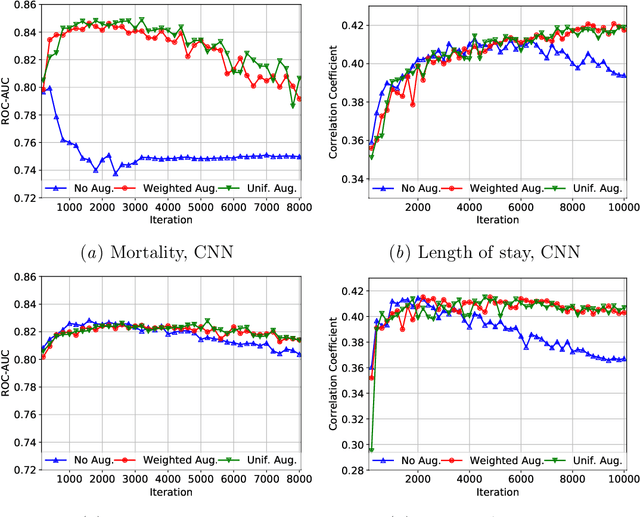
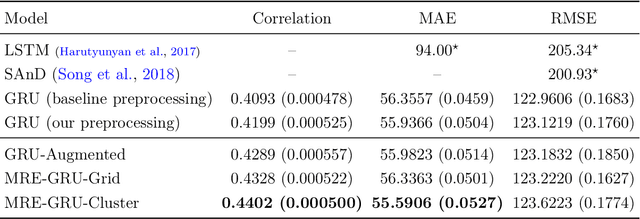
Electronic records contain sequences of events, some of which take place all at once in a single visit, and others that are dispersed over multiple visits, each with a different timestamp. We postulate that fine temporal detail, e.g., whether a series of blood tests are completed at once or in rapid succession should not alter predictions based on this data. Motivated by this intuition, we propose models for analyzing sequences of multivariate clinical time series data that are invariant to this temporal clustering. We propose an efficient data augmentation technique that exploits the postulated temporal-clustering invariance to regularize deep neural networks optimized for several clinical prediction tasks. We introduce two techniques to temporally coarsen (downsample) irregular time series: (i) grouping the data points based on regularly-spaced timestamps; and (ii) clustering them, yielding irregularly-paced timestamps. Moreover, we propose a MultiResolution Ensemble (MRE) model, improving predictive accuracy by ensembling predictions based on inputs sequences transformed by different coarsening operators. Our experiments show that MRE improves the mAP on the benchmark mortality prediction task from 51.53% to 53.92%.
Thresholding Classifiers to Maximize F1 Score
May 14, 2014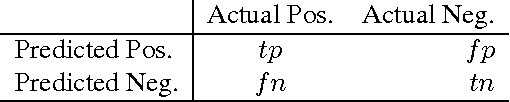
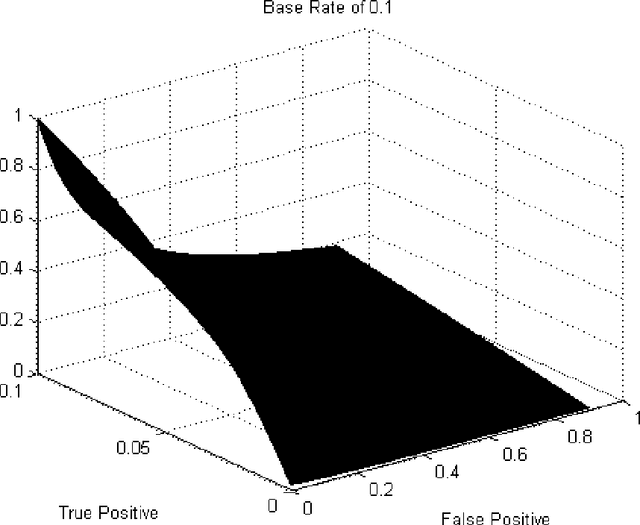
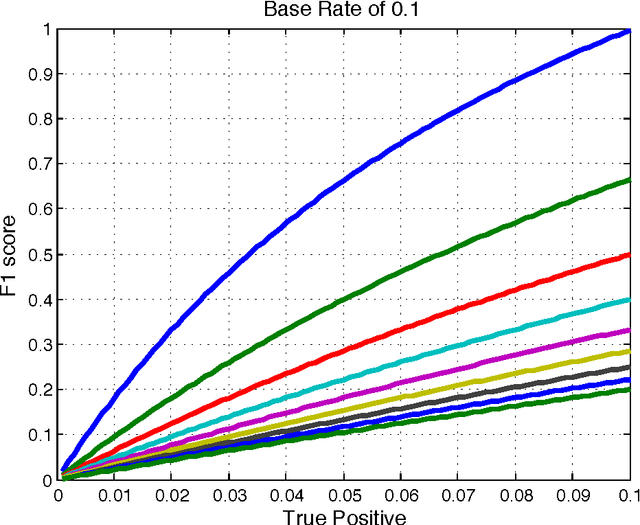
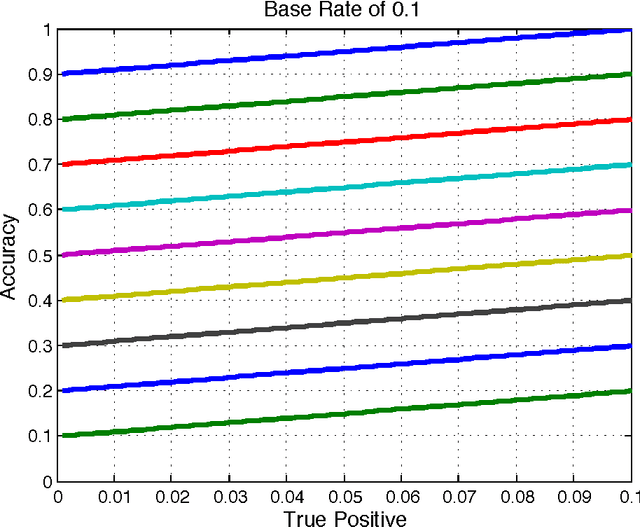
This paper provides new insight into maximizing F1 scores in the context of binary classification and also in the context of multilabel classification. The harmonic mean of precision and recall, F1 score is widely used to measure the success of a binary classifier when one class is rare. Micro average, macro average, and per instance average F1 scores are used in multilabel classification. For any classifier that produces a real-valued output, we derive the relationship between the best achievable F1 score and the decision-making threshold that achieves this optimum. As a special case, if the classifier outputs are well-calibrated conditional probabilities, then the optimal threshold is half the optimal F1 score. As another special case, if the classifier is completely uninformative, then the optimal behavior is to classify all examples as positive. Since the actual prevalence of positive examples typically is low, this behavior can be considered undesirable. As a case study, we discuss the results, which can be surprising, of applying this procedure when predicting 26,853 labels for Medline documents.