 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGamified crowd-sourcing of high-quality data for visual fine-tuning
Oct 08, 2024



This paper introduces Gamified Adversarial Prompting (GAP), a framework that crowd-sources high-quality data for visual instruction tuning of large multimodal models. GAP transforms the data collection process into an engaging game, incentivizing players to provide fine-grained, challenging questions and answers that target gaps in the model's knowledge. Our contributions include (1) an approach to capture question-answer pairs from humans that directly address weaknesses in a model's knowledge, (2) a method for evaluating and rewarding players that successfully incentivizes them to provide high-quality submissions, and (3) a scalable, gamified platform that succeeds in collecting this data from over 50,000 participants in just a few weeks. Our implementation of GAP has significantly improved the accuracy of a small multimodal model, namely MiniCPM-Llama3-V-2.5-8B, increasing its GPT score from 0.147 to 0.477 on our dataset, approaching the benchmark set by the much larger GPT-4V. Moreover, we demonstrate that the data generated using MiniCPM-Llama3-V-2.5-8B also enhances its performance across other benchmarks, and exhibits cross-model benefits. Specifically, the same data improves the performance of QWEN2-VL-2B and QWEN2-VL-7B on the same multiple benchmarks.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Achieving Fluency and Coherency in Task-oriented Dialog
Apr 11, 2018
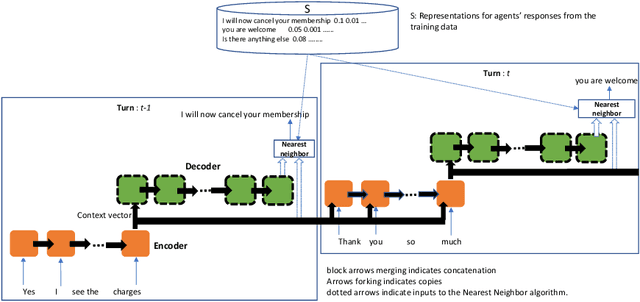


We consider real world task-oriented dialog settings, where agents need to generate both fluent natural language responses and correct external actions like database queries and updates. We demonstrate that, when applied to customer support chat transcripts, Sequence to Sequence (Seq2Seq) models often generate short, incoherent and ungrammatical natural language responses that are dominated by words that occur with high frequency in the training data. These phenomena do not arise in synthetic datasets such as bAbI, where we show Seq2Seq models are nearly perfect. We develop techniques to learn embeddings that succinctly capture relevant information from the dialog history, and demonstrate that nearest neighbor based approaches in this learned neural embedding space generate more fluent responses. However, we see that these methods are not able to accurately predict when to execute an external action. We show how to combine nearest neighbor and Seq2Seq methods in a hybrid model, where nearest neighbor is used to generate fluent responses and Seq2Seq type models ensure dialog coherency and generate accurate external actions. We show that this approach is well suited for customer support scenarios, where agents' responses are typically script-driven, and correct external actions are critically important. The hybrid model on the customer support data achieves a 78% relative improvement in fluency scores, and a 130% improvement in accuracy of external calls.
End-to-End Offline Goal-Oriented Dialog Policy Learning via Policy Gradient
Dec 07, 2017
Learning a goal-oriented dialog policy is generally performed offline with supervised learning algorithms or online with reinforcement learning (RL). Additionally, as companies accumulate massive quantities of dialog transcripts between customers and trained human agents, encoder-decoder methods have gained popularity as agent utterances can be directly treated as supervision without the need for utterance-level annotations. However, one potential drawback of such approaches is that they myopically generate the next agent utterance without regard for dialog-level considerations. To resolve this concern, this paper describes an offline RL method for learning from unannotated corpora that can optimize a goal-oriented policy at both the utterance and dialog level. We introduce a novel reward function and use both on-policy and off-policy policy gradient to learn a policy offline without requiring online user interaction or an explicit state space definition.
Predicting Surgery Duration with Neural Heteroscedastic Regression
Jul 13, 2017
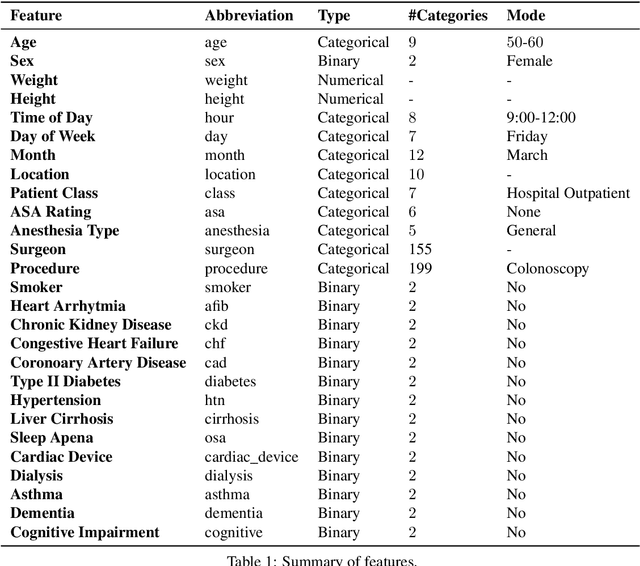
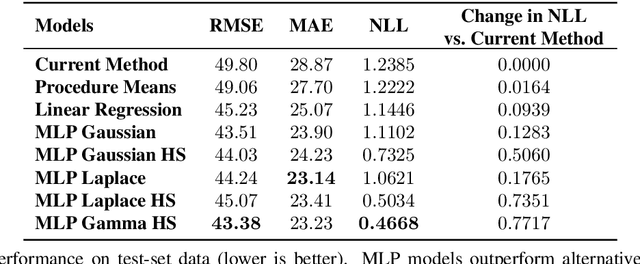
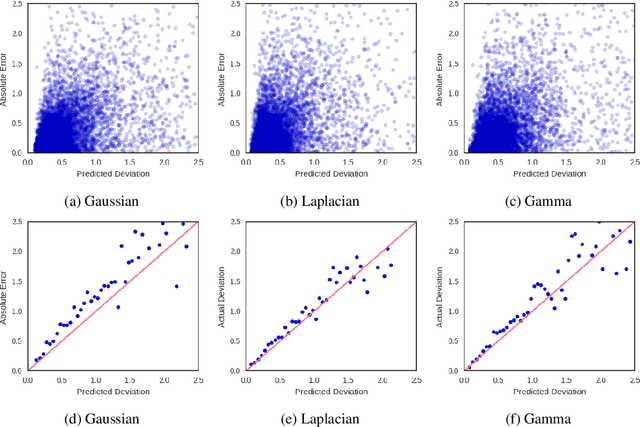
Scheduling surgeries is a challenging task due to the fundamental uncertainty of the clinical environment, as well as the risks and costs associated with under- and over-booking. We investigate neural regression algorithms to estimate the parameters of surgery case durations, focusing on the issue of heteroscedasticity. We seek to simultaneously estimate the duration of each surgery, as well as a surgery-specific notion of our uncertainty about its duration. Estimating this uncertainty can lead to more nuanced and effective scheduling strategies, as we are able to schedule surgeries more efficiently while allowing an informed and case-specific margin of error. Using surgery records %from the UC San Diego Health System, from a large United States health system we demonstrate potential improvements on the order of 20% (in terms of minutes overbooked) compared to current scheduling techniques. Moreover, we demonstrate that surgery durations are indeed heteroscedastic. We show that models that estimate case-specific uncertainty better fit the data (log likelihood). Additionally, we show that the heteroscedastic predictions can more optimally trade off between over and under-booking minutes, especially when idle minutes and scheduling collisions confer disparate costs.
Visualizing the Consequences of Evidence in Bayesian Networks
Jul 04, 2017

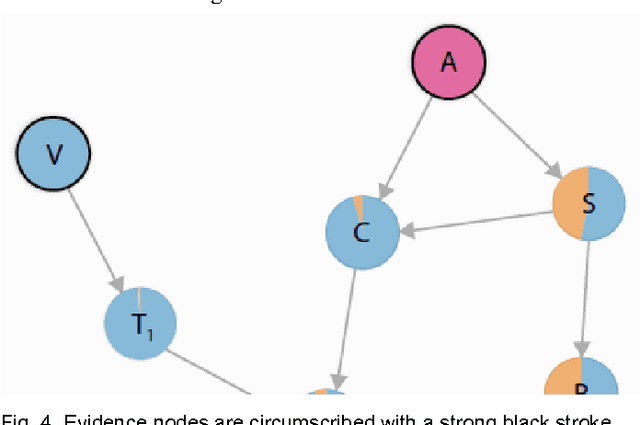
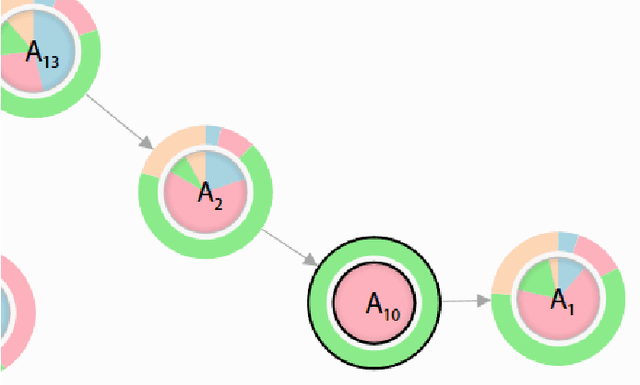
This paper addresses the challenge of viewing and navigating Bayesian networks as their structural size and complexity grow. Starting with a review of the state of the art of visualizing Bayesian networks, an area which has largely been passed over, we improve upon existing visualizations in three ways. First, we apply a disciplined approach to the graphic design of the basic elements of the Bayesian network. Second, we propose a technique for direct, visual comparison of posterior distributions resulting from alternative evidence sets. Third, we leverage a central mathematical tool in information theory, to assist the user in finding variables of interest in the network, and to reduce visual complexity where unimportant. We present our methods applied to two modestly large Bayesian networks constructed from real-world data sets. Results suggest the new techniques can be a useful tool for discovering information flow phenomena, and also for qualitative comparisons of different evidence configurations, especially in large probabilistic networks.
Learning to Diagnose with LSTM Recurrent Neural Networks
Mar 21, 2017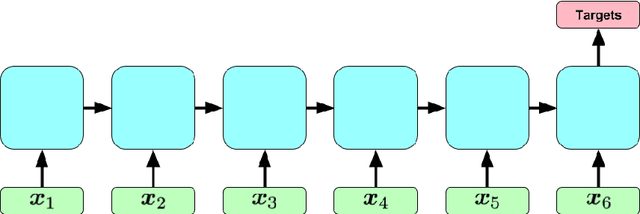
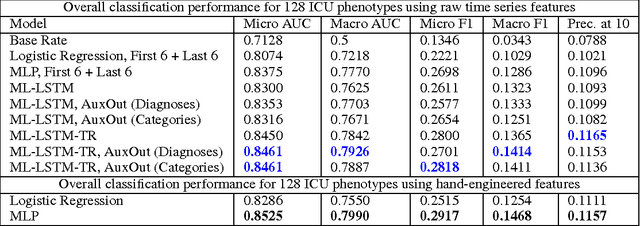
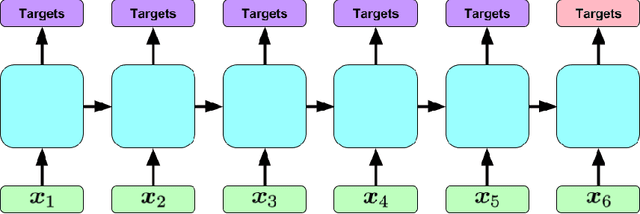
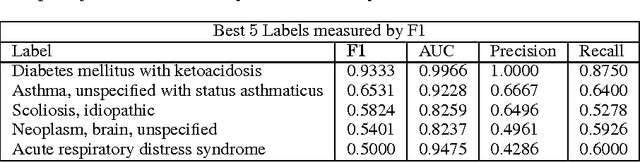
Clinical medical data, especially in the intensive care unit (ICU), consist of multivariate time series of observations. For each patient visit (or episode), sensor data and lab test results are recorded in the patient's Electronic Health Record (EHR). While potentially containing a wealth of insights, the data is difficult to mine effectively, owing to varying length, irregular sampling and missing data. Recurrent Neural Networks (RNNs), particularly those using Long Short-Term Memory (LSTM) hidden units, are powerful and increasingly popular models for learning from sequence data. They effectively model varying length sequences and capture long range dependencies. We present the first study to empirically evaluate the ability of LSTMs to recognize patterns in multivariate time series of clinical measurements. Specifically, we consider multilabel classification of diagnoses, training a model to classify 128 diagnoses given 13 frequently but irregularly sampled clinical measurements. First, we establish the effectiveness of a simple LSTM network for modeling clinical data. Then we demonstrate a straightforward and effective training strategy in which we replicate targets at each sequence step. Trained only on raw time series, our models outperform several strong baselines, including a multilayer perceptron trained on hand-engineered features.
A Critical Review of Recurrent Neural Networks for Sequence Learning
Oct 17, 2015
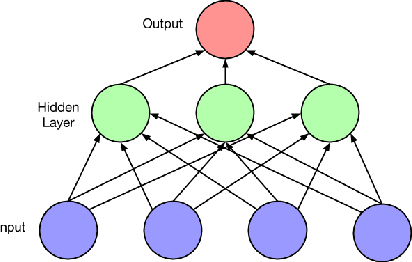
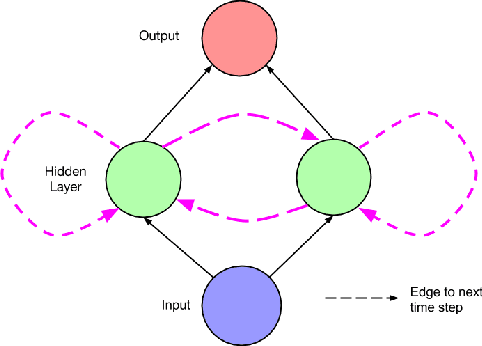
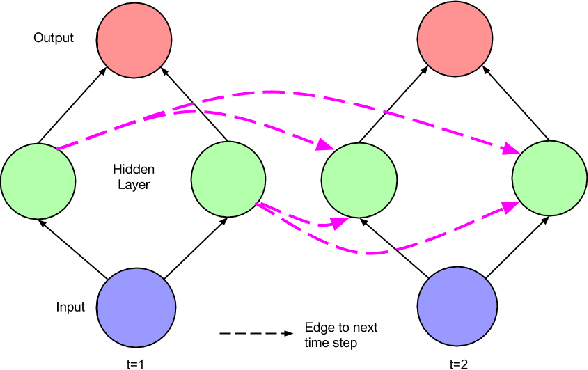
Countless learning tasks require dealing with sequential data. Image captioning, speech synthesis, and music generation all require that a model produce outputs that are sequences. In other domains, such as time series prediction, video analysis, and musical information retrieval, a model must learn from inputs that are sequences. Interactive tasks, such as translating natural language, engaging in dialogue, and controlling a robot, often demand both capabilities. Recurrent neural networks (RNNs) are connectionist models that capture the dynamics of sequences via cycles in the network of nodes. Unlike standard feedforward neural networks, recurrent networks retain a state that can represent information from an arbitrarily long context window. Although recurrent neural networks have traditionally been difficult to train, and often contain millions of parameters, recent advances in network architectures, optimization techniques, and parallel computation have enabled successful large-scale learning with them. In recent years, systems based on long short-term memory (LSTM) and bidirectional (BRNN) architectures have demonstrated ground-breaking performance on tasks as varied as image captioning, language translation, and handwriting recognition. In this survey, we review and synthesize the research that over the past three decades first yielded and then made practical these powerful learning models. When appropriate, we reconcile conflicting notation and nomenclature. Our goal is to provide a self-contained explication of the state of the art together with a historical perspective and references to primary research.
Efficient Elastic Net Regularization for Sparse Linear Models
Jul 02, 2015
This paper presents an algorithm for efficient training of sparse linear models with elastic net regularization. Extending previous work on delayed updates, the new algorithm applies stochastic gradient updates to non-zero features only, bringing weights current as needed with closed-form updates. Closed-form delayed updates for the $\ell_1$, $\ell_{\infty}$, and rarely used $\ell_2$ regularizers have been described previously. This paper provides closed-form updates for the popular squared norm $\ell^2_2$ and elastic net regularizers. We provide dynamic programming algorithms that perform each delayed update in constant time. The new $\ell^2_2$ and elastic net methods handle both fixed and varying learning rates, and both standard {stochastic gradient descent} (SGD) and {forward backward splitting (FoBoS)}. Experimental results show that on a bag-of-words dataset with $260,941$ features, but only $88$ nonzero features on average per training example, the dynamic programming method trains a logistic regression classifier with elastic net regularization over $2000$ times faster than otherwise.
Differential Privacy and Machine Learning: a Survey and Review
Dec 24, 2014The objective of machine learning is to extract useful information from data, while privacy is preserved by concealing information. Thus it seems hard to reconcile these competing interests. However, they frequently must be balanced when mining sensitive data. For example, medical research represents an important application where it is necessary both to extract useful information and protect patient privacy. One way to resolve the conflict is to extract general characteristics of whole populations without disclosing the private information of individuals. In this paper, we consider differential privacy, one of the most popular and powerful definitions of privacy. We explore the interplay between machine learning and differential privacy, namely privacy-preserving machine learning algorithms and learning-based data release mechanisms. We also describe some theoretical results that address what can be learned differentially privately and upper bounds of loss functions for differentially private algorithms. Finally, we present some open questions, including how to incorporate public data, how to deal with missing data in private datasets, and whether, as the number of observed samples grows arbitrarily large, differentially private machine learning algorithms can be achieved at no cost to utility as compared to corresponding non-differentially private algorithms.