 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Learning by Focusing on the Biggest Losers
Oct 02, 2019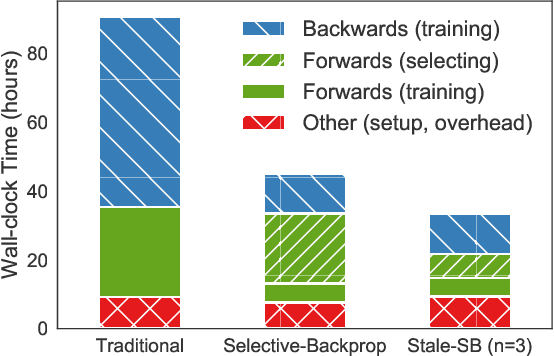
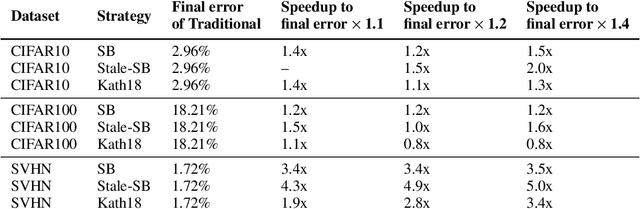

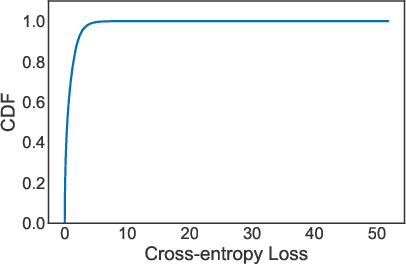
This paper introduces Selective-Backprop, a technique that accelerates the training of deep neural networks (DNNs) by prioritizing examples with high loss at each iteration. Selective-Backprop uses the output of a training example's forward pass to decide whether to use that example to compute gradients and update parameters, or to skip immediately to the next example. By reducing the number of computationally-expensive backpropagation steps performed, Selective-Backprop accelerates training. Evaluation on CIFAR10, CIFAR100, and SVHN, across a variety of modern image models, shows that Selective-Backprop converges to target error rates up to 3.5x faster than with standard SGD and between 1.02--1.8x faster than a state-of-the-art importance sampling approach. Further acceleration of 26% can be achieved by using stale forward pass results for selection, thus also skipping forward passes of low priority examples.
Scaling Video Analytics on Constrained Edge Nodes
May 24, 2019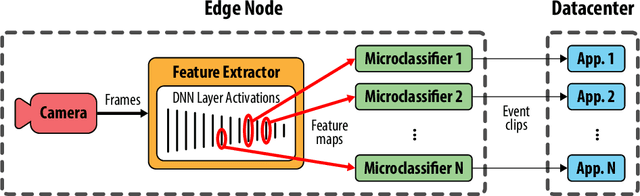
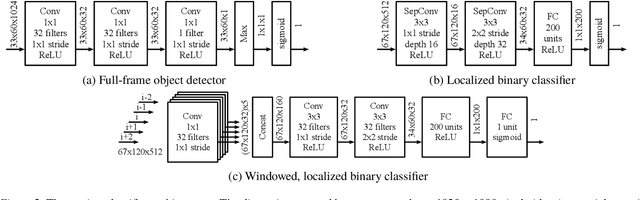


As video camera deployments continue to grow, the need to process large volumes of real-time data strains wide area network infrastructure. When per-camera bandwidth is limited, it is infeasible for applications such as traffic monitoring and pedestrian tracking to offload high-quality video streams to a datacenter. This paper presents FilterForward, a new edge-to-cloud system that enables datacenter-based applications to process content from thousands of cameras by installing lightweight edge filters that backhaul only relevant video frames. FilterForward introduces fast and expressive per-application microclassifiers that share computation to simultaneously detect dozens of events on computationally constrained edge nodes. Only matching events are transmitted to the cloud. Evaluation on two real-world camera feed datasets shows that FilterForward reduces bandwidth use by an order of magnitude while improving computational efficiency and event detection accuracy for challenging video content.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
EDF: Ensemble, Distill, and Fuse for Easy Video Labeling
Dec 10, 2018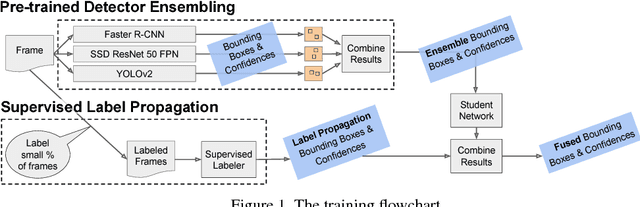
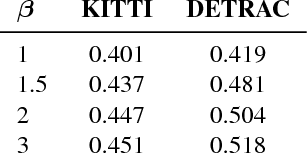

We present a way to rapidly bootstrap object detection on unseen videos using minimal human annotations. We accomplish this by combining two complementary sources of knowledge (one generic and the other specific) using bounding box merging and model distillation. The first (generic) knowledge source is obtained from ensembling pre-trained object detectors using a novel bounding box merging and confidence reweighting scheme. We make the observation that model distillation with data augmentation can train a specialized detector that outperforms the noisy labels it was trained on, and train a Student Network on the ensemble detections that obtains higher mAP than the ensemble itself. The second (specialized) knowledge source comes from training a detector (which we call the Supervised Labeler) on a labeled subset of the video to generate detections on the unlabeled portion. We demonstrate on two popular vehicular datasets that these techniques work to emit bounding boxes for all vehicles in the frame with higher mean average precision (mAP) than any of the reference networks used, and that the combination of ensembled and human-labeled data produces object detections that outperform either alone.
3LC: Lightweight and Effective Traffic Compression for Distributed Machine Learning
Feb 21, 2018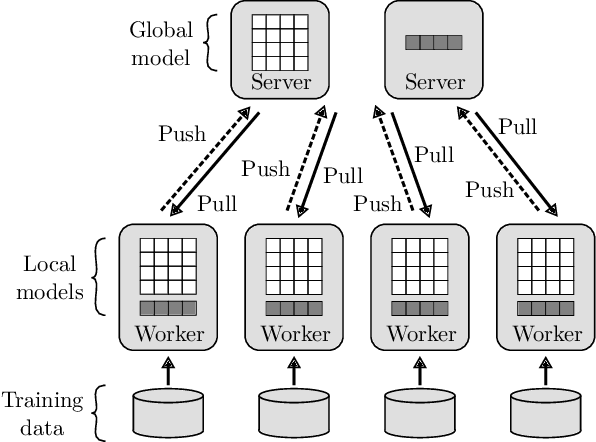
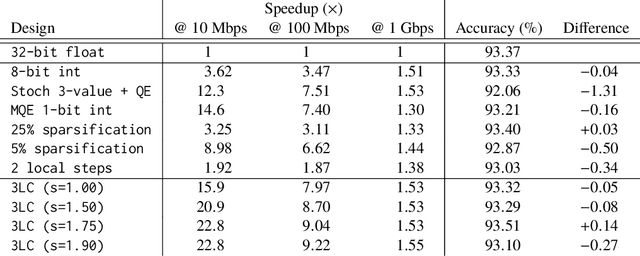
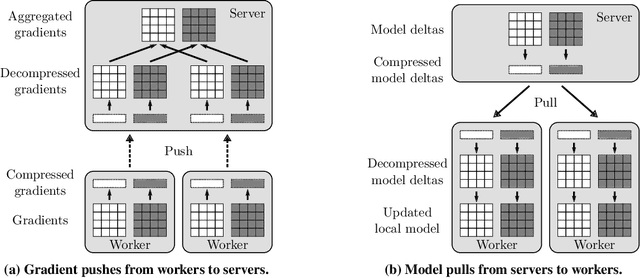

The performance and efficiency of distributed machine learning (ML) depends significantly on how long it takes for nodes to exchange state changes. Overly-aggressive attempts to reduce communication often sacrifice final model accuracy and necessitate additional ML techniques to compensate for this loss, limiting their generality. Some attempts to reduce communication incur high computation overhead, which makes their performance benefits visible only over slow networks. We present 3LC, a lossy compression scheme for state change traffic that strikes balance between multiple goals: traffic reduction, accuracy, computation overhead, and generality. It combines three new techniques---3-value quantization with sparsity multiplication, quartic encoding, and zero-run encoding---to leverage strengths of quantization and sparsification techniques and avoid their drawbacks. It achieves a data compression ratio of up to 39--107X, almost the same test accuracy of trained models, and high compression speed. Distributed ML frameworks can employ 3LC without modifications to existing ML algorithms. Our experiments show that 3LC reduces wall-clock training time of ResNet-110--based image classifiers for CIFAR-10 on a 10-GPU cluster by up to 16--23X compared to TensorFlow's baseline design.
Learning to Protect Communications with Adversarial Neural Cryptography
Oct 21, 2016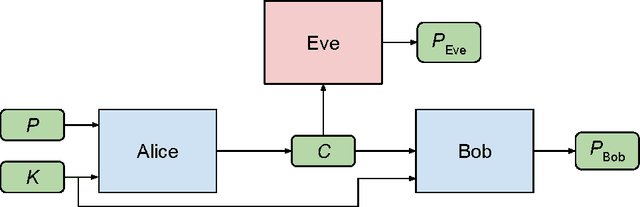
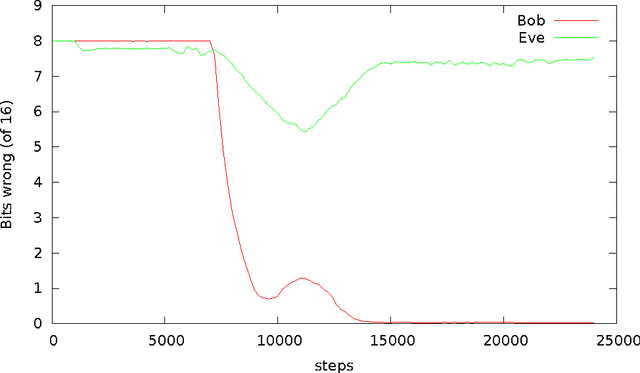
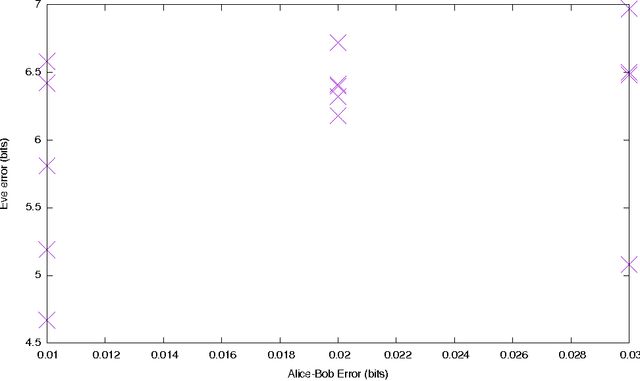
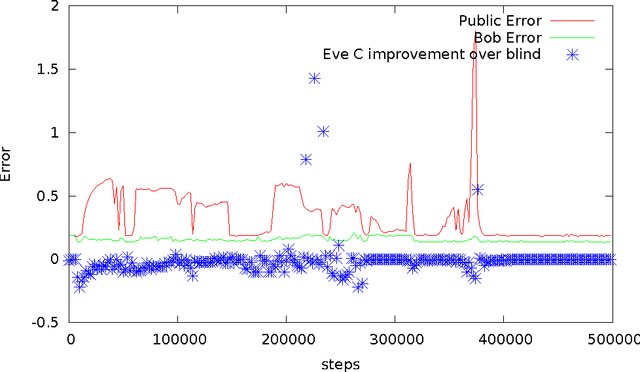
We ask whether neural networks can learn to use secret keys to protect information from other neural networks. Specifically, we focus on ensuring confidentiality properties in a multiagent system, and we specify those properties in terms of an adversary. Thus, a system may consist of neural networks named Alice and Bob, and we aim to limit what a third neural network named Eve learns from eavesdropping on the communication between Alice and Bob. We do not prescribe specific cryptographic algorithms to these neural networks; instead, we train end-to-end, adversarially. We demonstrate that the neural networks can learn how to perform forms of encryption and decryption, and also how to apply these operations selectively in order to meet confidentiality goals.