 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataRater: Meta-Learned Dataset Curation
May 23, 2025The quality of foundation models depends heavily on their training data. Consequently, great efforts have been put into dataset curation. Yet most approaches rely on manual tuning of coarse-grained mixtures of large buckets of data, or filtering by hand-crafted heuristics. An approach that is ultimately more scalable (let alone more satisfying) is to \emph{learn} which data is actually valuable for training. This type of meta-learning could allow more sophisticated, fine-grained, and effective curation. Our proposed \emph{DataRater} is an instance of this idea. It estimates the value of training on any particular data point. This is done by meta-learning using `meta-gradients', with the objective of improving training efficiency on held out data. In extensive experiments across a range of model scales and datasets, we find that using our DataRater to filter data is highly effective, resulting in significantly improved compute efficiency.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
Nov 13, 2019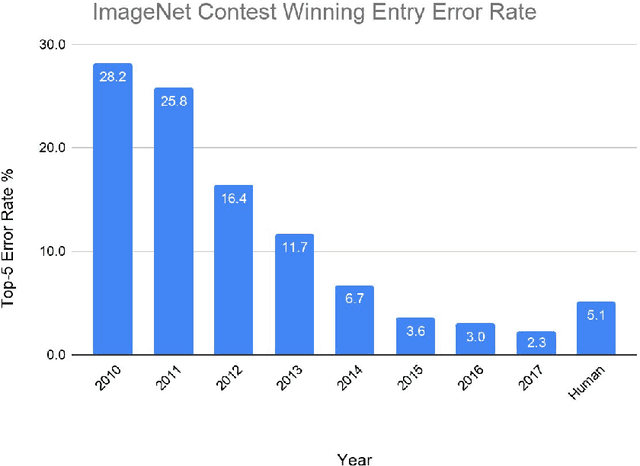
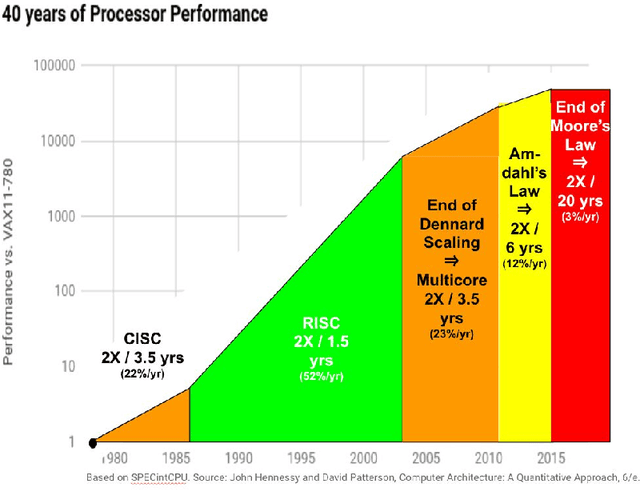
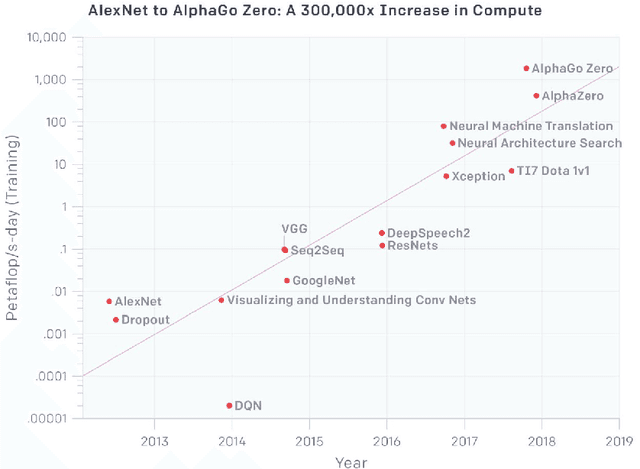
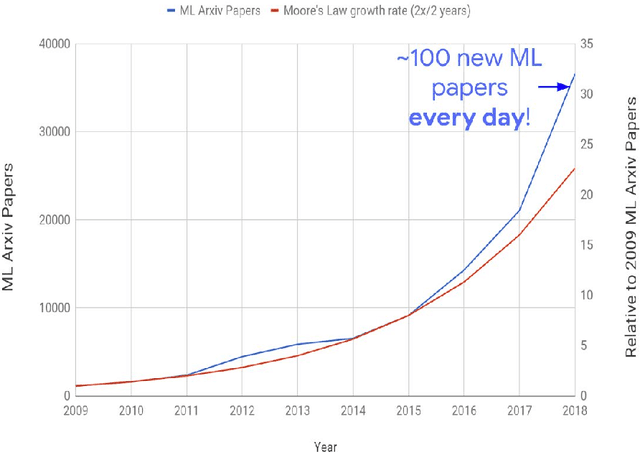
The past decade has seen a remarkable series of advances in machine learning, and in particular deep learning approaches based on artificial neural networks, to improve our abilities to build more accurate systems across a broad range of areas, including computer vision, speech recognition, language translation, and natural language understanding tasks. This paper is a companion paper to a keynote talk at the 2020 International Solid-State Circuits Conference (ISSCC) discussing some of the advances in machine learning, and their implications on the kinds of computational devices we need to build, especially in the post-Moore's Law-era. It also discusses some of the ways that machine learning may also be able to help with some aspects of the circuit design process. Finally, it provides a sketch of at least one interesting direction towards much larger-scale multi-task models that are sparsely activated and employ much more dynamic, example- and task-based routing than the machine learning models of today.
Accelerating Deep Learning by Focusing on the Biggest Losers
Oct 02, 2019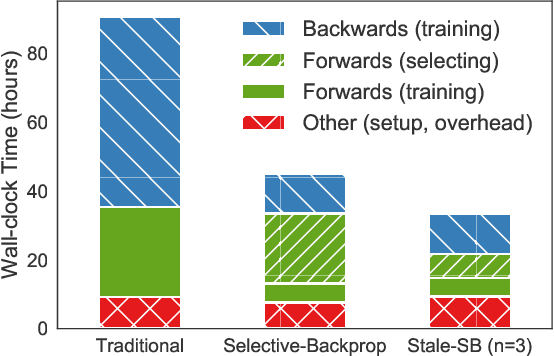
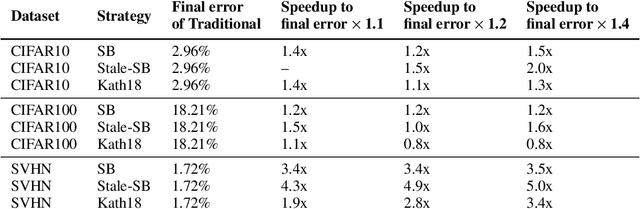

This paper introduces Selective-Backprop, a technique that accelerates the training of deep neural networks (DNNs) by prioritizing examples with high loss at each iteration. Selective-Backprop uses the output of a training example's forward pass to decide whether to use that example to compute gradients and update parameters, or to skip immediately to the next example. By reducing the number of computationally-expensive backpropagation steps performed, Selective-Backprop accelerates training. Evaluation on CIFAR10, CIFAR100, and SVHN, across a variety of modern image models, shows that Selective-Backprop converges to target error rates up to 3.5x faster than with standard SGD and between 1.02--1.8x faster than a state-of-the-art importance sampling approach. Further acceleration of 26% can be achieved by using stale forward pass results for selection, thus also skipping forward passes of low priority examples.
Microscope 2.0: An Augmented Reality Microscope with Real-time Artificial Intelligence Integration
Dec 04, 2018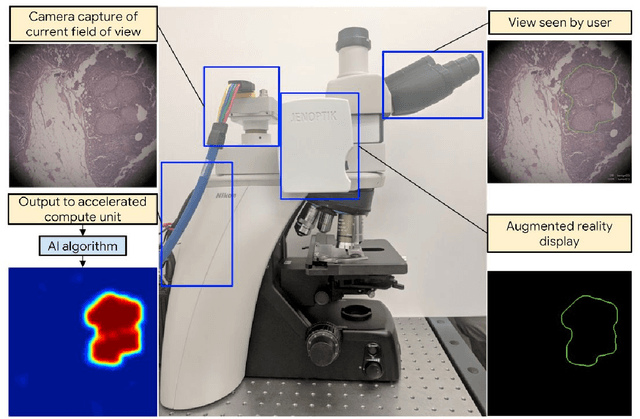
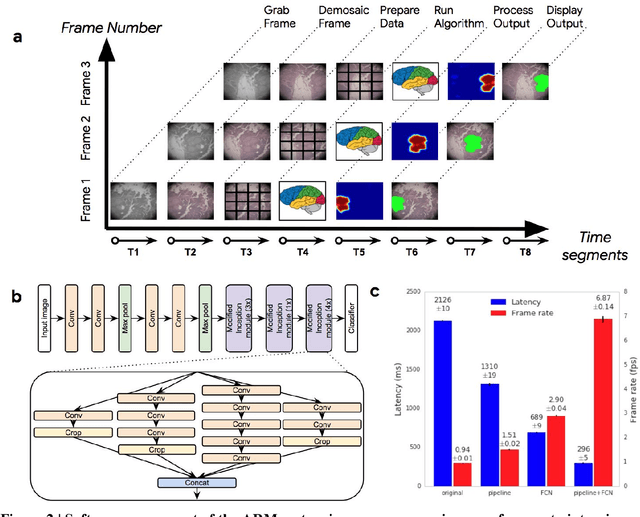
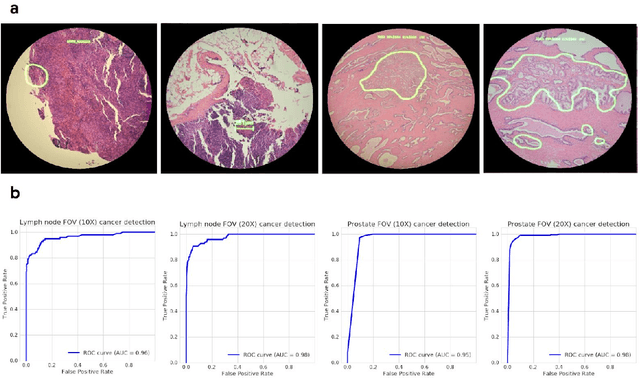
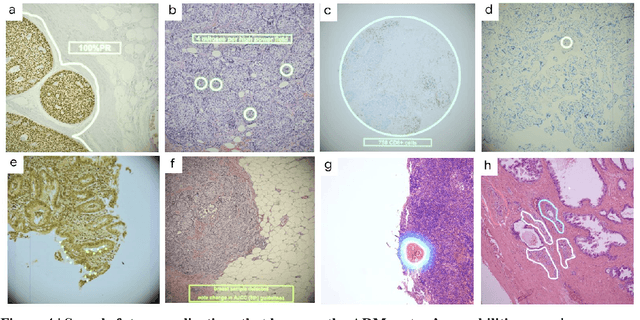
The brightfield microscope is instrumental in the visual examination of both biological and physical samples at sub-millimeter scales. One key clinical application has been in cancer histopathology, where the microscopic assessment of the tissue samples is used for the diagnosis and staging of cancer and thus guides clinical therapy. However, the interpretation of these samples is inherently subjective, resulting in significant diagnostic variability. Moreover, in many regions of the world, access to pathologists is severely limited due to lack of trained personnel. In this regard, Artificial Intelligence (AI) based tools promise to improve the access and quality of healthcare. However, despite significant advances in AI research, integration of these tools into real-world cancer diagnosis workflows remains challenging because of the costs of image digitization and difficulties in deploying AI solutions. Here we propose a cost-effective solution to the integration of AI: the Augmented Reality Microscope (ARM). The ARM overlays AI-based information onto the current view of the sample through the optical pathway in real-time, enabling seamless integration of AI into the regular microscopy workflow. We demonstrate the utility of ARM in the detection of lymph node metastases in breast cancer and the identification of prostate cancer with a latency that supports real-time workflows. We anticipate that ARM will remove barriers towards the use of AI in microscopic analysis and thus improve the accuracy and efficiency of cancer diagnosis. This approach is applicable to other microscopy tasks and AI algorithms in the life sciences and beyond.
The Case for Learned Index Structures
Apr 30, 2018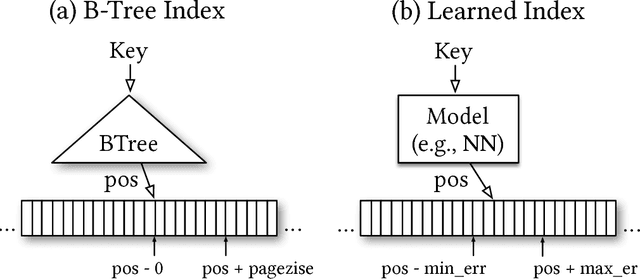

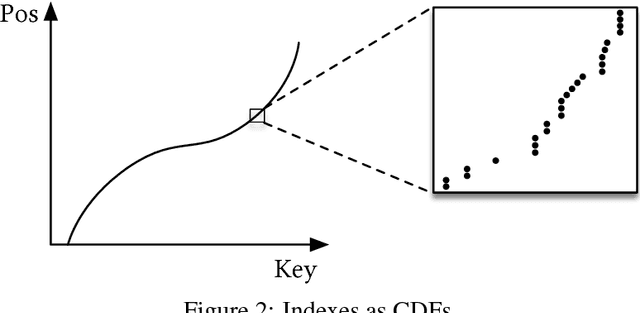
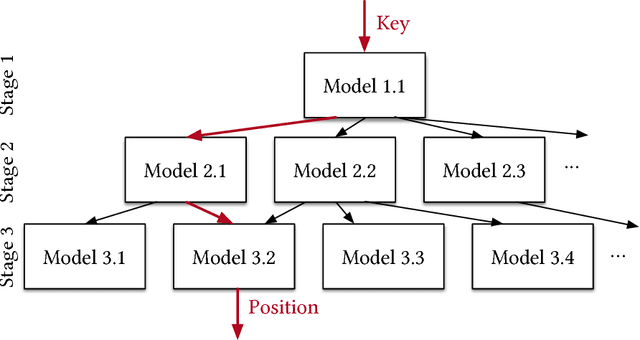
Indexes are models: a B-Tree-Index can be seen as a model to map a key to the position of a record within a sorted array, a Hash-Index as a model to map a key to a position of a record within an unsorted array, and a BitMap-Index as a model to indicate if a data record exists or not. In this exploratory research paper, we start from this premise and posit that all existing index structures can be replaced with other types of models, including deep-learning models, which we term learned indexes. The key idea is that a model can learn the sort order or structure of lookup keys and use this signal to effectively predict the position or existence of records. We theoretically analyze under which conditions learned indexes outperform traditional index structures and describe the main challenges in designing learned index structures. Our initial results show, that by using neural nets we are able to outperform cache-optimized B-Trees by up to 70% in speed while saving an order-of-magnitude in memory over several real-world data sets. More importantly though, we believe that the idea of replacing core components of a data management system through learned models has far reaching implications for future systems designs and that this work just provides a glimpse of what might be possible.
Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation
Aug 21, 2017We propose a simple solution to use a single Neural Machine Translation (NMT) model to translate between multiple languages. Our solution requires no change in the model architecture from our base system but instead introduces an artificial token at the beginning of the input sentence to specify the required target language. The rest of the model, which includes encoder, decoder and attention, remains unchanged and is shared across all languages. Using a shared wordpiece vocabulary, our approach enables Multilingual NMT using a single model without any increase in parameters, which is significantly simpler than previous proposals for Multilingual NMT. Our method often improves the translation quality of all involved language pairs, even while keeping the total number of model parameters constant. On the WMT'14 benchmarks, a single multilingual model achieves comparable performance for English$\rightarrow$French and surpasses state-of-the-art results for English$\rightarrow$German. Similarly, a single multilingual model surpasses state-of-the-art results for French$\rightarrow$English and German$\rightarrow$English on WMT'14 and WMT'15 benchmarks respectively. On production corpora, multilingual models of up to twelve language pairs allow for better translation of many individual pairs. In addition to improving the translation quality of language pairs that the model was trained with, our models can also learn to perform implicit bridging between language pairs never seen explicitly during training, showing that transfer learning and zero-shot translation is possible for neural translation. Finally, we show analyses that hints at a universal interlingua representation in our models and show some interesting examples when mixing languages.
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016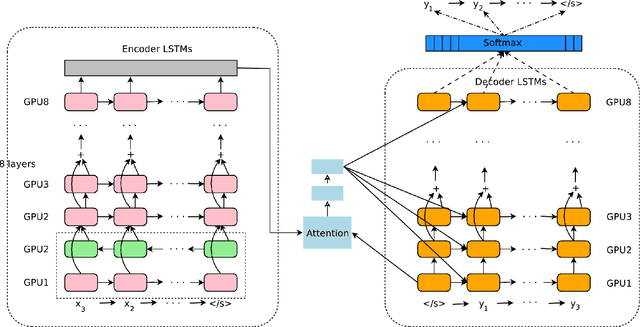

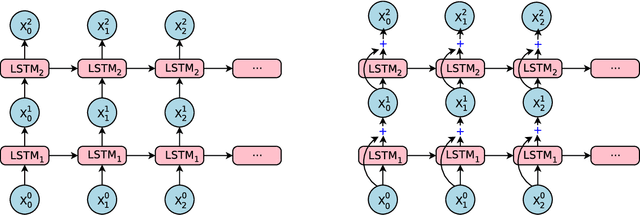
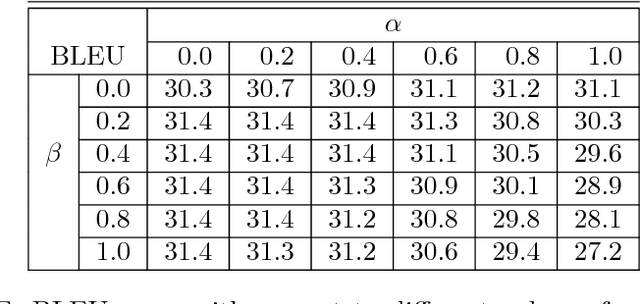
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.
TensorFlow: A system for large-scale machine learning
May 31, 2016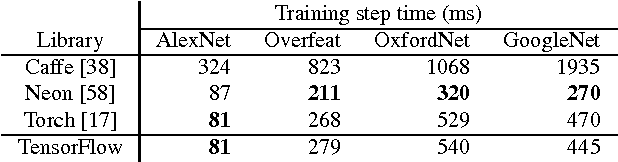

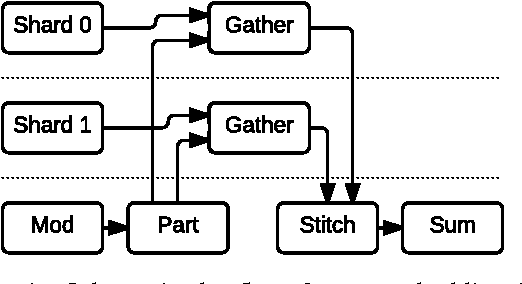
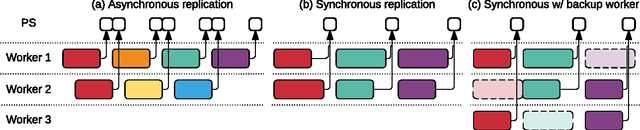
TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general-purpose GPUs, and custom designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous "parameter server" designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with particularly strong support for training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model in contrast to existing systems, and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.