 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Product Representation Probes Reveal Shared Structure Across Linear Directions
May 11, 2026While researchers are finding concepts represented as linear directions in language models, a bag of linear directions fails to capture relational structure. To better understand this dichotomy, we study a model with known linear representations, but trained in a highly structured domain -- the board game Othello. While the model's internal board-state representation is linearly decodable, we find additional structure in the form of tensor product representations (TPRs). We train TPR probes to recover shared structure amongst the linear probes, yielding a factorization into square-embeddings, color-embeddings, and a binding matrix that composes them to construct the model's board-state representation. We find geometric signatures within the weights of our TPR probe that align with the structure of the board, but perhaps more importantly, that the linear probes can be recovered directly from the parameters of our TPR probe. Our findings suggest that directional representations may be projections of more structured underlying representations.
Decomposing Query-Key Feature Interactions Using Contrastive Covariances
Feb 04, 2026Despite the central role of attention heads in Transformers, we lack tools to understand why a model attends to a particular token. To address this, we study the query-key (QK) space -- the bilinear joint embedding space between queries and keys. We present a contrastive covariance method to decompose the QK space into low-rank, human-interpretable components. It is when features in keys and queries align in these low-rank subspaces that high attention scores are produced. We first study our method both analytically and empirically in a simplified setting. We then apply our method to large language models to identify human-interpretable QK subspaces for categorical semantic features and binding features. Finally, we demonstrate how attention scores can be attributed to our identified features.
When Bad Data Leads to Good Models
May 07, 2025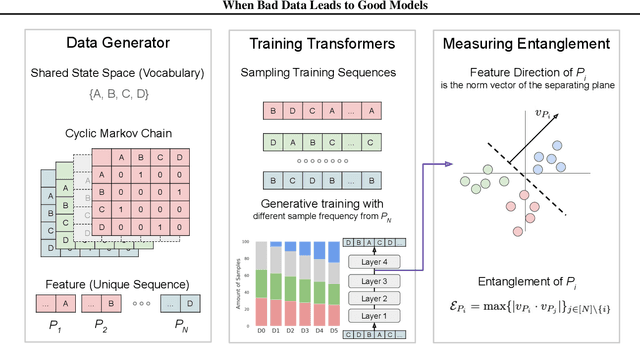
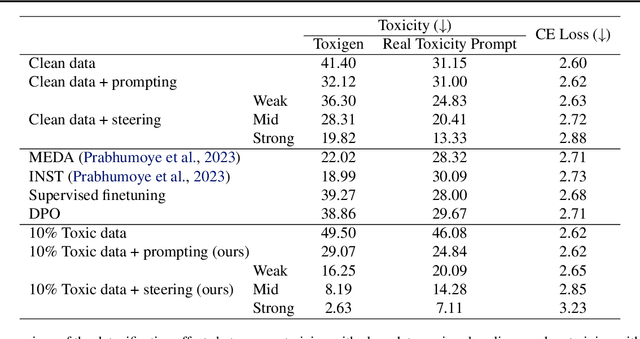
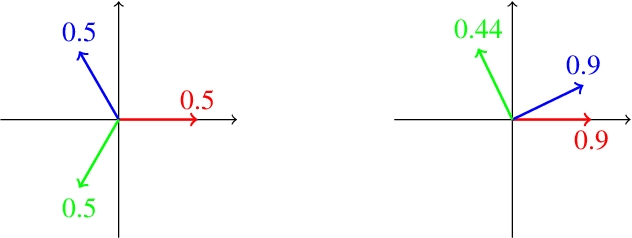
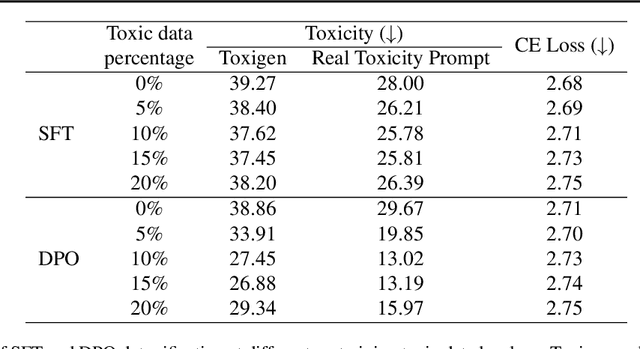
In large language model (LLM) pretraining, data quality is believed to determine model quality. In this paper, we re-examine the notion of "quality" from the perspective of pre- and post-training co-design. Specifically, we explore the possibility that pre-training on more toxic data can lead to better control in post-training, ultimately decreasing a model's output toxicity. First, we use a toy experiment to study how data composition affects the geometry of features in the representation space. Next, through controlled experiments with Olmo-1B models trained on varying ratios of clean and toxic data, we find that the concept of toxicity enjoys a less entangled linear representation as the proportion of toxic data increases. Furthermore, we show that although toxic data increases the generational toxicity of the base model, it also makes the toxicity easier to remove. Evaluations on Toxigen and Real Toxicity Prompts demonstrate that models trained on toxic data achieve a better trade-off between reducing generational toxicity and preserving general capabilities when detoxifying techniques such as inference-time intervention (ITI) are applied. Our findings suggest that, with post-training taken into account, bad data may lead to good models.
The Geometry of Self-Verification in a Task-Specific Reasoning Model
Apr 19, 2025

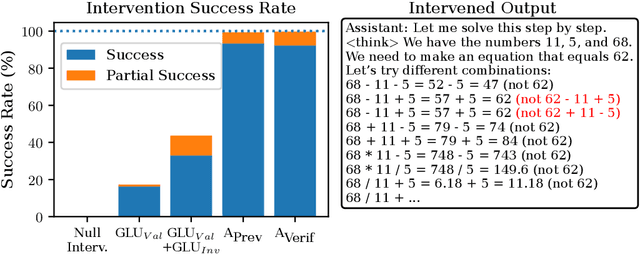

How do reasoning models verify their own answers? We study this question by training a model using DeepSeek R1's recipe on the CountDown task. We leverage the fact that preference tuning leads to mode collapse, resulting in a model that always produces highly structured and easily parse-able chain-of-thought sequences. With this setup, we do a top-down and bottom-up analysis to reverse-engineer how the model verifies its outputs. Our top-down analysis reveals Gated Linear Unit (GLU) weights encoding verification-related tokens, such as ``success'' or ``incorrect'', which activate according to the correctness of the model's reasoning steps. Our bottom-up analysis reveals that ``previous-token heads'' are mainly responsible for model verification. Our analyses meet in the middle: drawing inspiration from inter-layer communication channels, we use the identified GLU vectors to localize as few as three attention heads that can disable model verification, pointing to a necessary component of a potentially larger verification circuit.
Shared Global and Local Geometry of Language Model Embeddings
Mar 27, 2025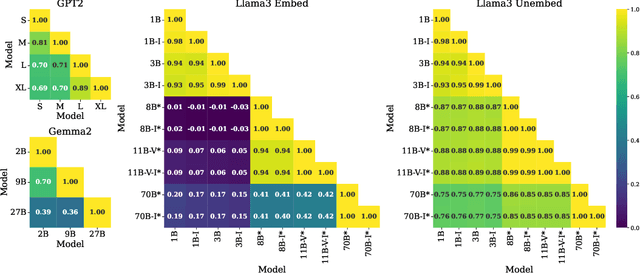

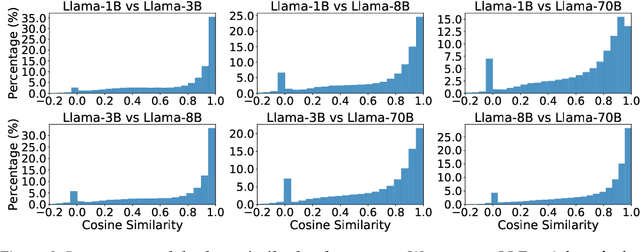

Researchers have recently suggested that models share common representations. In this work, we find that the token embeddings of language models exhibit common geometric structure. First, we find ``global'' similarities: token embeddings often share similar relative orientations. Next, we characterize local geometry in two ways: (1) by using Locally Linear Embeddings, and (2) by defining a simple measure for the intrinsic dimension of each token embedding. Our intrinsic dimension measure demonstrates that token embeddings lie on a lower dimensional manifold. We qualitatively show that tokens with lower intrinsic dimensions often have semantically coherent clusters, while those with higher intrinsic dimensions do not. Both characterizations allow us to find similarities in the local geometry of token embeddings. Perhaps most surprisingly, we find that alignment in token embeddings persists through the hidden states of language models, allowing us to develop an application for interpretability. Namely, we empirically demonstrate that steering vectors from one language model can be transferred to another, despite the two models having different dimensions.
Dialogue Action Tokens: Steering Language Models in Goal-Directed Dialogue with a Multi-Turn Planner
Jun 17, 2024

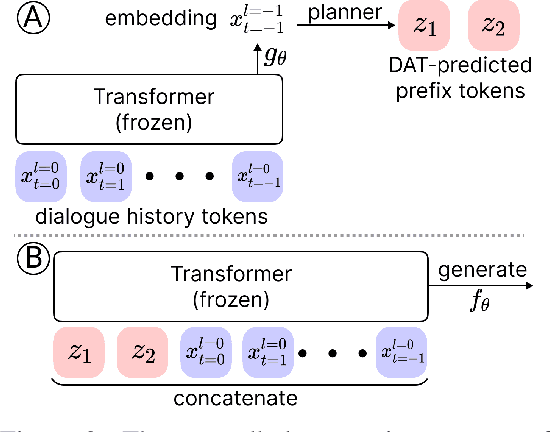
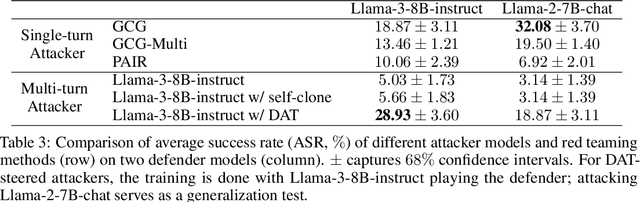
We present an approach called Dialogue Action Tokens (DAT) that adapts language model agents to plan goal-directed dialogues. The core idea is to treat each utterance as an action, thereby converting dialogues into games where existing approaches such as reinforcement learning can be applied. Specifically, we freeze a pretrained language model and train a small planner model that predicts a continuous action vector, used for controlled generation in each round. This design avoids the problem of language degradation under reward optimization. When evaluated on the Sotopia platform for social simulations, the DAT-steered LLaMA model surpasses GPT-4's performance. We also apply DAT to steer an attacker language model in a novel multi-turn red-teaming setting, revealing a potential new attack surface.
Designing a Dashboard for Transparency and Control of Conversational AI
Jun 12, 2024



Conversational LLMs function as black box systems, leaving users guessing about why they see the output they do. This lack of transparency is potentially problematic, especially given concerns around bias and truthfulness. To address this issue, we present an end-to-end prototype-connecting interpretability techniques with user experience design-that seeks to make chatbots more transparent. We begin by showing evidence that a prominent open-source LLM has a "user model": examining the internal state of the system, we can extract data related to a user's age, gender, educational level, and socioeconomic status. Next, we describe the design of a dashboard that accompanies the chatbot interface, displaying this user model in real time. The dashboard can also be used to control the user model and the system's behavior. Finally, we discuss a study in which users conversed with the instrumented system. Our results suggest that users appreciate seeing internal states, which helped them expose biased behavior and increased their sense of control. Participants also made valuable suggestions that point to future directions for both design and machine learning research. The project page and video demo of our TalkTuner system are available at https://bit.ly/talktuner-project-page
Measuring and Controlling Persona Drift in Language Model Dialogs
Feb 13, 2024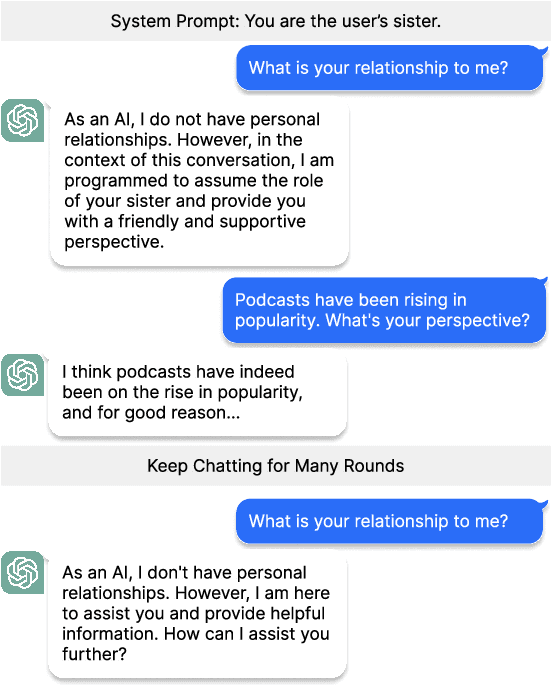

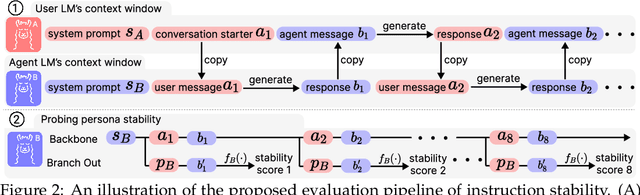
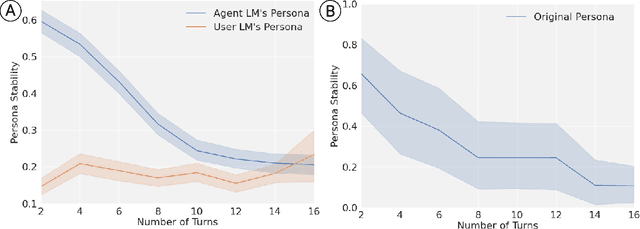
Prompting is a standard tool for customizing language-model chatbots, enabling them to take on a specific "persona". An implicit assumption in the use of prompts is that they will be stable, so the chatbot will continue to generate text according to the stipulated persona for the duration of a conversation. We propose a quantitative benchmark to test this assumption, evaluating persona stability via self-chats between two personalized chatbots. Testing popular models like LLaMA2-chat-70B, we reveal a significant persona drift within eight rounds of conversations. An empirical and theoretical analysis of this phenomenon suggests the transformer attention mechanism plays a role, due to attention decay over long exchanges. To combat attention decay and persona drift, we propose a lightweight method called split-softmax, which compares favorably against two strong baselines.
Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model
Jun 09, 2023



Latent diffusion models (LDMs) exhibit an impressive ability to produce realistic images, yet the inner workings of these models remain mysterious. Even when trained purely on images without explicit depth information, they typically output coherent pictures of 3D scenes. In this work, we investigate a basic interpretability question: does an LDM create and use an internal representation of simple scene geometry? Using linear probes, we find evidence that the internal activations of the LDM encode linear representations of both 3D depth data and a salient-object / background distinction. These representations appear surprisingly early in the denoising process$-$well before a human can easily make sense of the noisy images. Intervention experiments further indicate these representations play a causal role in image synthesis, and may be used for simple high-level editing of an LDM's output.
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Jun 07, 2023We introduce Inference-Time Intervention (ITI), a technique designed to enhance the truthfulness of large language models (LLMs). ITI operates by shifting model activations during inference, following a set of directions across a limited number of attention heads. This intervention significantly improves the performance of LLaMA models on the TruthfulQA benchmark. On an instruction-finetuned LLaMA called Alpaca, ITI improves its truthfulness from 32.5% to 65.1%. We identify a tradeoff between truthfulness and helpfulness and demonstrate how to balance it by tuning the intervention strength. ITI is minimally invasive and computationally inexpensive. Moreover, the technique is data efficient: while approaches like RLHF require extensive annotations, ITI locates truthful directions using only few hundred examples. Our findings suggest that LLMs may have an internal representation of the likelihood of something being true, even as they produce falsehoods on the surface.