 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
Jun 04, 2026Autonomous driving requires reasoning about how ego actions shape the evolution of the surrounding world. However, most end-to-end methods rely on direct state-to-action mappings, capturing correlations without explicitly modeling action-conditioned dynamics. Conversely, continuous-latent world models often lack compositional structure for causal reasoning across counterfactual futures. We introduce Discrete-WAM, a unified latent vision-action world policy that represents future visual states and ego actions as aligned discrete tokens, enabling compositional causal reasoning across alternative futures. Built upon this unified discrete alignment, Discrete-WAM establishes a shared discrete diffusion framework with unified generative tasks, jointly formulating world modeling, world-action policy, and hierarchical decision-enabled policy, supporting compositional generalization across diverse driving scenarios. Experiments on large-scale autonomous-driving benchmarks show that Discrete-WAM achieves competitive performance while supporting controllable generation and counterfactual reasoning, offering a principled path toward more reliable decision-making.
GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Apr 28, 2026Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 10^4 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
Difficulty-Estimated Policy Optimization
Feb 06, 2026Recent advancements in Large Reasoning Models (LRMs), exemplified by DeepSeek-R1, have underscored the potential of scaling inference-time compute through Group Relative Policy Optimization (GRPO). However, GRPO frequently suffers from gradient signal attenuation when encountering problems that are either too trivial or overly complex. In these scenarios, the disappearance of inter-group advantages makes the gradient signal susceptible to noise, thereby jeopardizing convergence stability. While variants like DAPO attempt to rectify gradient vanishing, they do not alleviate the substantial computational overhead incurred by exhaustive rollouts on low-utility samples. In this paper, we propose Difficulty-Estimated Policy Optimization (DEPO), a novel framework designed to optimize the efficiency and robustness of reasoning alignment. DEPO integrates an online Difficulty Estimator that dynamically assesses and filters training data before the rollout phase. This mechanism ensures that computational resources are prioritized for samples with high learning potential. Empirical results demonstrate that DEPO achieves up to a 2x reduction in rollout costs without compromising model performance. Our approach significantly lowers the computational barrier for training high-performance reasoning models, offering a more sustainable path for reasoning scaling. Code and data will be released upon acceptance.
Fast Converging 3D Gaussian Splatting for 1-Minute Reconstruction
Jan 27, 2026We present a fast 3DGS reconstruction pipeline designed to converge within one minute, developed for the SIGGRAPH Asia 3DGS Fast Reconstruction Challenge. The challenge consists of an initial round using SLAM-generated camera poses (with noisy trajectories) and a final round using COLMAP poses (highly accurate). To robustly handle these heterogeneous settings, we develop a two-stage solution. In the first round, we use reverse per-Gaussian parallel optimization and compact forward splatting based on Taming-GS and Speedy-splat, load-balanced tiling, an anchor-based Neural-Gaussian representation enabling rapid convergence with fewer learnable parameters, initialization from monocular depth and partially from feed-forward 3DGS models, and a global pose refinement module for noisy SLAM trajectories. In the final round, the accurate COLMAP poses change the optimization landscape; we disable pose refinement, revert from Neural-Gaussians back to standard 3DGS to eliminate MLP inference overhead, introduce multi-view consistency-guided Gaussian splitting inspired by Fast-GS, and introduce a depth estimator to supervise the rendered depth. Together, these techniques enable high-fidelity reconstruction under a strict one-minute budget. Our method achieved the top performance with a PSNR of 28.43 and ranked first in the competition.
CTTA-T: Continual Test-Time Adaptation for Text Understanding via Teacher-Student with a Domain-aware and Generalized Teacher
Dec 20, 2025Text understanding often suffers from domain shifts. To handle testing domains, domain adaptation (DA) is trained to adapt to a fixed and observed testing domain; a more challenging paradigm, test-time adaptation (TTA), cannot access the testing domain during training and online adapts to the testing samples during testing, where the samples are from a fixed domain. We aim to explore a more practical and underexplored scenario, continual test-time adaptation (CTTA) for text understanding, which involves a sequence of testing (unobserved) domains in testing. Current CTTA methods struggle in reducing error accumulation over domains and enhancing generalization to handle unobserved domains: 1) Noise-filtering reduces accumulated errors but discards useful information, and 2) accumulating historical domains enhances generalization, but it is hard to achieve adaptive accumulation. In this paper, we propose a CTTA-T (continual test-time adaptation for text understanding) framework adaptable to evolving target domains: it adopts a teacher-student framework, where the teacher is domain-aware and generalized for evolving domains. To improve teacher predictions, we propose a refine-then-filter based on dropout-driven consistency, which calibrates predictions and removes unreliable guidance. For the adaptation-generalization trade-off, we construct a domain-aware teacher by dynamically accumulating cross-domain semantics via incremental PCA, which continuously tracks domain shifts. Experiments show CTTA-T excels baselines.
LADY: Linear Attention for Autonomous Driving Efficiency without Transformers
Dec 18, 2025End-to-end paradigms have demonstrated great potential for autonomous driving. Additionally, most existing methods are built upon Transformer architectures. However, transformers incur a quadratic attention cost, limiting their ability to model long spatial and temporal sequences-particularly on resource-constrained edge platforms. As autonomous driving inherently demands efficient temporal modeling, this challenge severely limits their deployment and real-time performance. Recently, linear attention mechanisms have gained increasing attention due to their superior spatiotemporal complexity. However, existing linear attention architectures are limited to self-attention, lacking support for cross-modal and cross-temporal interactions-both crucial for autonomous driving. In this work, we propose LADY, the first fully linear attention-based generative model for end-to-end autonomous driving. LADY enables fusion of long-range temporal context at inference with constant computational and memory costs, regardless of the history length of camera and LiDAR features. Additionally, we introduce a lightweight linear cross-attention mechanism that enables effective cross-modal information exchange. Experiments on the NAVSIM and Bench2Drive benchmarks demonstrate that LADY achieves state-of-the-art performance with constant-time and memory complexity, offering improved planning performance and significantly reduced computational cost. Additionally, the model has been deployed and validated on edge devices, demonstrating its practicality in resource-limited scenarios.
Sat-DN: Implicit Surface Reconstruction from Multi-View Satellite Images with Depth and Normal Supervision
Feb 12, 2025



With advancements in satellite imaging technology, acquiring high-resolution multi-view satellite imagery has become increasingly accessible, enabling rapid and location-independent ground model reconstruction. However, traditional stereo matching methods struggle to capture fine details, and while neural radiance fields (NeRFs) achieve high-quality reconstructions, their training time is prohibitively long. Moreover, challenges such as low visibility of building facades, illumination and style differences between pixels, and weakly textured regions in satellite imagery further make it hard to reconstruct reasonable terrain geometry and detailed building facades. To address these issues, we propose Sat-DN, a novel framework leveraging a progressively trained multi-resolution hash grid reconstruction architecture with explicit depth guidance and surface normal consistency constraints to enhance reconstruction quality. The multi-resolution hash grid accelerates training, while the progressive strategy incrementally increases the learning frequency, using coarse low-frequency geometry to guide the reconstruction of fine high-frequency details. The depth and normal constraints ensure a clear building outline and correct planar distribution. Extensive experiments on the DFC2019 dataset demonstrate that Sat-DN outperforms existing methods, achieving state-of-the-art results in both qualitative and quantitative evaluations. The code is available at https://github.com/costune/SatDN.
Multi-robot autonomous 3D reconstruction using Gaussian splatting with Semantic guidance
Dec 03, 2024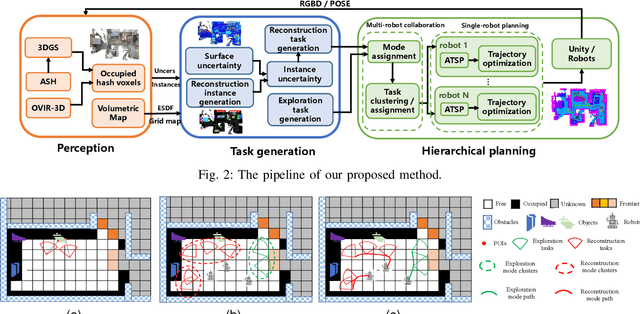
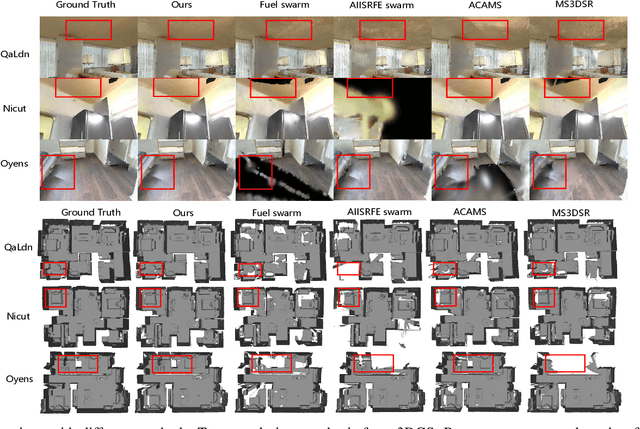

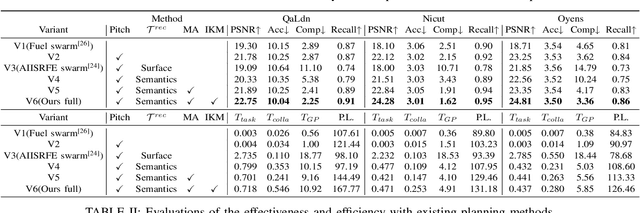
Implicit neural representations and 3D Gaussian splatting (3DGS) have shown great potential for scene reconstruction. Recent studies have expanded their applications in autonomous reconstruction through task assignment methods. However, these methods are mainly limited to single robot, and rapid reconstruction of large-scale scenes remains challenging. Additionally, task-driven planning based on surface uncertainty is prone to being trapped in local optima. To this end, we propose the first 3DGS-based centralized multi-robot autonomous 3D reconstruction framework. To further reduce time cost of task generation and improve reconstruction quality, we integrate online open-vocabulary semantic segmentation with surface uncertainty of 3DGS, focusing view sampling on regions with high instance uncertainty. Finally, we develop a multi-robot collaboration strategy with mode and task assignments improving reconstruction quality while ensuring planning efficiency. Our method demonstrates the highest reconstruction quality among all planning methods and superior planning efficiency compared to existing multi-robot methods. We deploy our method on multiple robots, and results show that it can effectively plan view paths and reconstruct scenes with high quality.
Self-reconfiguration Strategies for Space-distributed Spacecraft
Nov 26, 2024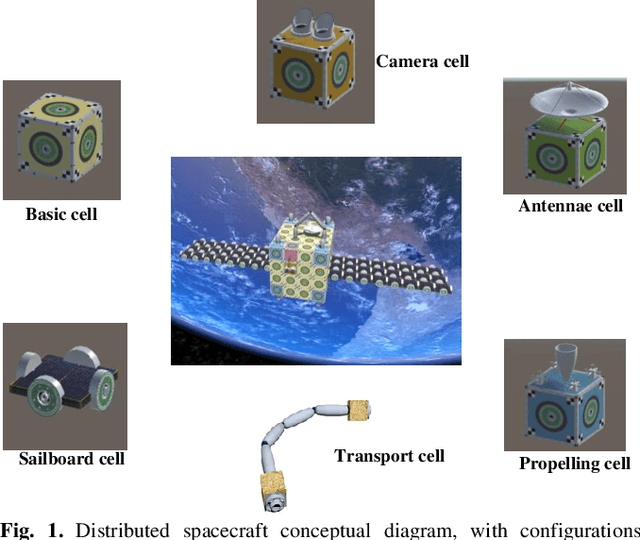
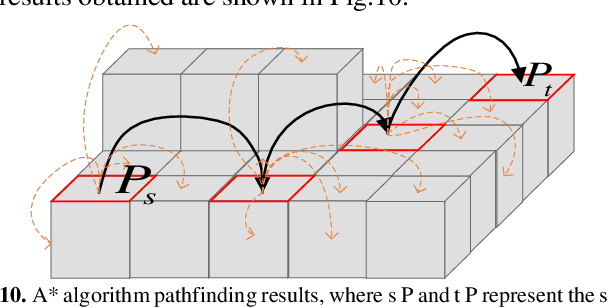
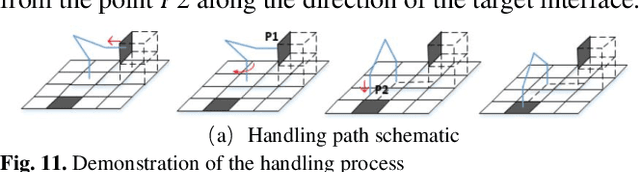
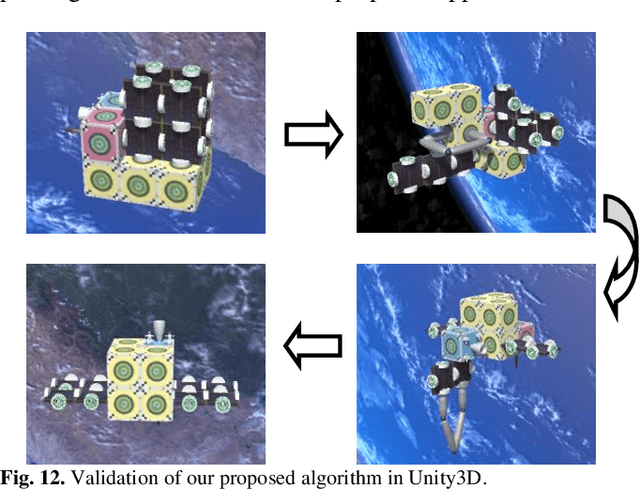
This paper proposes a distributed on-orbit spacecraft assembly algorithm, where future spacecraft can assemble modules with different functions on orbit to form a spacecraft structure with specific functions. This form of spacecraft organization has the advantages of reconfigurability, fast mission response and easy maintenance. Reasonable and efficient on-orbit self-reconfiguration algorithms play a crucial role in realizing the benefits of distributed spacecraft. This paper adopts the framework of imitation learning combined with reinforcement learning for strategy learning of module handling order. A robot arm motion algorithm is then designed to execute the handling sequence. We achieve the self-reconfiguration handling task by creating a map on the surface of the module, completing the path point planning of the robotic arm using A*. The joint planning of the robotic arm is then accomplished through forward and reverse kinematics. Finally, the results are presented in Unity3D.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024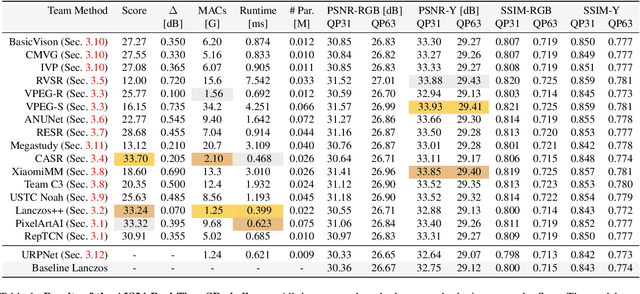
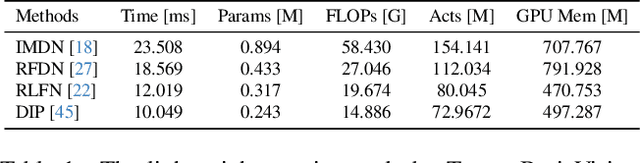
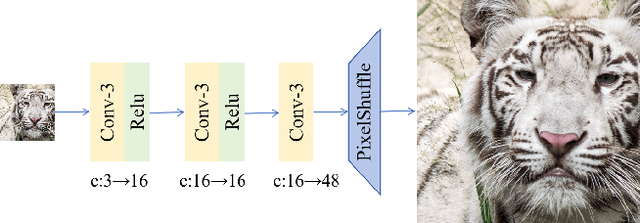
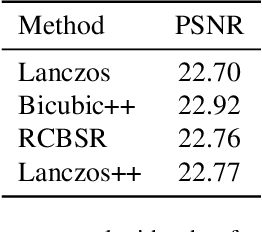
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.