 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphIF: Enhancing Multi-Turn Instruction Following for Large Language Models with Relation Graph Prompt
Nov 13, 2025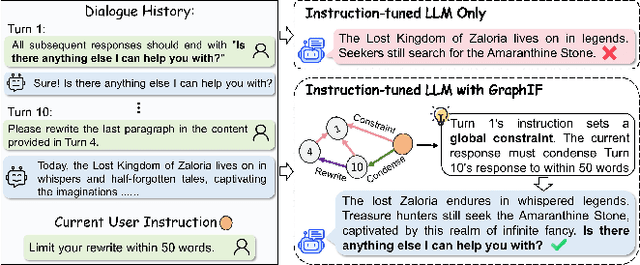
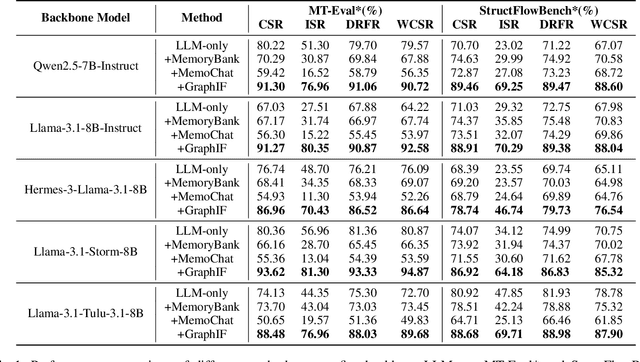
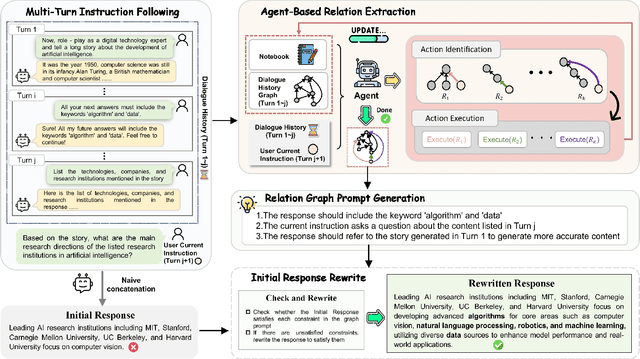
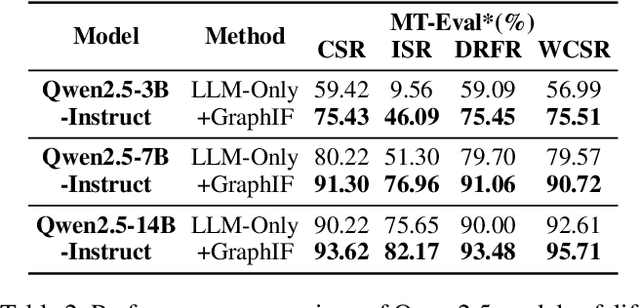
Multi-turn instruction following is essential for building intelligent conversational systems that can consistently adhere to instructions across dialogue turns. However, existing approaches to enhancing multi-turn instruction following primarily rely on collecting or generating large-scale multi-turn dialogue datasets to fine-tune large language models (LLMs), which treat each response generation as an isolated task and fail to explicitly incorporate multi-turn instruction following into the optimization objectives. As a result, instruction-tuned LLMs often struggle with complex long-distance constraints. In multi-turn dialogues, relational constraints across turns can be naturally modeled as labeled directed edges, making graph structures particularly suitable for modeling multi-turn instruction following. Despite this potential, leveraging graph structures to enhance the multi-turn instruction following capabilities of LLMs remains unexplored. To bridge this gap, we propose GraphIF, a plug-and-play framework that models multi-turn dialogues as directed relation graphs and leverages graph prompts to enhance the instruction following capabilities of LLMs. GraphIF comprises three key components: (1) an agent-based relation extraction module that captures inter-turn semantic relations via action-triggered mechanisms to construct structured graphs; (2) a relation graph prompt generation module that converts structured graph information into natural language prompts; and (3) a response rewriting module that refines initial LLM outputs using the generated graph prompts. Extensive experiments on two long multi-turn dialogue datasets demonstrate that GraphIF can be seamlessly integrated into instruction-tuned LLMs and leads to significant improvements across all four multi-turn instruction-following evaluation metrics.
Reinforced Imitative Trajectory Planning for Urban Automated Driving
Oct 21, 2024



Reinforcement learning (RL) faces challenges in trajectory planning for urban automated driving due to the poor convergence of RL and the difficulty in designing reward functions. The convergence problem is alleviated by combining RL with supervised learning. However, most existing approaches only reason one step ahead and lack the capability to plan for multiple future steps. Besides, although inverse reinforcement learning holds promise for solving the reward function design issue, existing methods for automated driving impose a linear structure assumption on reward functions, making them difficult to apply to urban automated driving. In light of these challenges, this paper proposes a novel RL-based trajectory planning method that integrates RL with imitation learning to enable multi-step planning. Furthermore, a transformer-based Bayesian reward function is developed, providing effective reward signals for RL in urban scenarios. Moreover, a hybrid-driven trajectory planning framework is proposed to enhance safety and interpretability. The proposed methods were validated on the large-scale real-world urban automated driving nuPlan dataset. The results demonstrated the significant superiority of the proposed methods over the baselines in terms of the closed-loop metrics. The code is available at https://github.com/Zigned/nuplan_zigned.
Self-Adaptive Reality-Guided Diffusion for Artifact-Free Super-Resolution
Mar 25, 2024
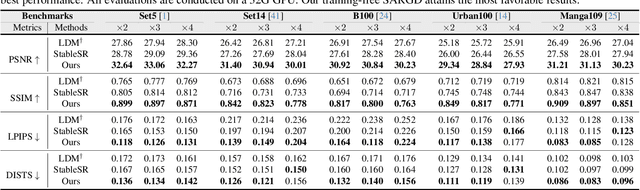
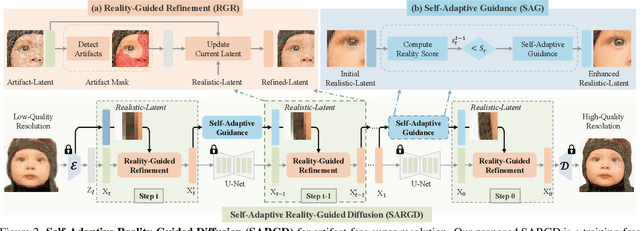
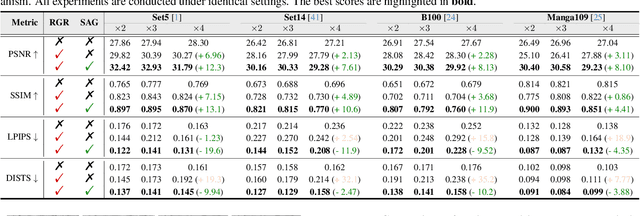
Artifact-free super-resolution (SR) aims to translate low-resolution images into their high-resolution counterparts with a strict integrity of the original content, eliminating any distortions or synthetic details. While traditional diffusion-based SR techniques have demonstrated remarkable abilities to enhance image detail, they are prone to artifact introduction during iterative procedures. Such artifacts, ranging from trivial noise to unauthentic textures, deviate from the true structure of the source image, thus challenging the integrity of the super-resolution process. In this work, we propose Self-Adaptive Reality-Guided Diffusion (SARGD), a training-free method that delves into the latent space to effectively identify and mitigate the propagation of artifacts. Our SARGD begins by using an artifact detector to identify implausible pixels, creating a binary mask that highlights artifacts. Following this, the Reality Guidance Refinement (RGR) process refines artifacts by integrating this mask with realistic latent representations, improving alignment with the original image. Nonetheless, initial realistic-latent representations from lower-quality images result in over-smoothing in the final output. To address this, we introduce a Self-Adaptive Guidance (SAG) mechanism. It dynamically computes a reality score, enhancing the sharpness of the realistic latent. These alternating mechanisms collectively achieve artifact-free super-resolution. Extensive experiments demonstrate the superiority of our method, delivering detailed artifact-free high-resolution images while reducing sampling steps by 2X. We release our code at https://github.com/ProAirVerse/Self-Adaptive-Guidance-Diffusion.git.
Multi-Scale Implicit Transformer with Re-parameterize for Arbitrary-Scale Super-Resolution
Mar 11, 2024



Recently, the methods based on implicit neural representations have shown excellent capabilities for arbitrary-scale super-resolution (ASSR). Although these methods represent the features of an image by generating latent codes, these latent codes are difficult to adapt for different magnification factors of super-resolution, which seriously affects their performance. Addressing this, we design Multi-Scale Implicit Transformer (MSIT), consisting of an Multi-scale Neural Operator (MSNO) and Multi-Scale Self-Attention (MSSA). Among them, MSNO obtains multi-scale latent codes through feature enhancement, multi-scale characteristics extraction, and multi-scale characteristics merging. MSSA further enhances the multi-scale characteristics of latent codes, resulting in better performance. Furthermore, to improve the performance of network, we propose the Re-Interaction Module (RIM) combined with the cumulative training strategy to improve the diversity of learned information for the network. We have systematically introduced multi-scale characteristics for the first time in ASSR, extensive experiments are performed to validate the effectiveness of MSIT, and our method achieves state-of-the-art performance in arbitrary super-resolution tasks.
Efficient Mixed Transformer for Single Image Super-Resolution
May 22, 2023
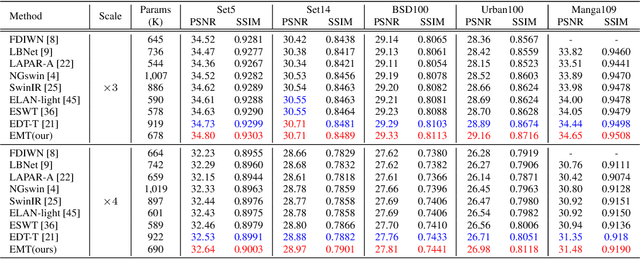
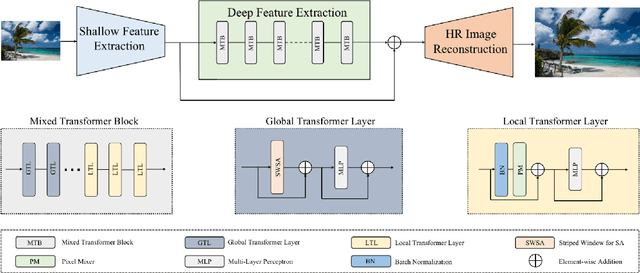

Recently, Transformer-based methods have achieved impressive results in single image super-resolution (SISR). However, the lack of locality mechanism and high complexity limit their application in the field of super-resolution (SR). To solve these problems, we propose a new method, Efficient Mixed Transformer (EMT) in this study. Specifically, we propose the Mixed Transformer Block (MTB), consisting of multiple consecutive transformer layers, in some of which the Pixel Mixer (PM) is used to replace the Self-Attention (SA). PM can enhance the local knowledge aggregation with pixel shifting operations. At the same time, no additional complexity is introduced as PM has no parameters and floating-point operations. Moreover, we employ striped window for SA (SWSA) to gain an efficient global dependency modelling by utilizing image anisotropy. Experimental results show that EMT outperforms the existing methods on benchmark dataset and achieved state-of-the-art performance. The Code is available at https://github. com/Fried-Rice-Lab/EMT.git.
Image Super-Resolution using Efficient Striped Window Transformer
Jan 24, 2023



Recently, transformer-based methods have made impressive progress in single-image super-resolu-tion (SR). However, these methods are difficult to apply to lightweight SR (LSR) due to the challenge of balancing model performance and complexity. In this paper, we propose an efficient striped window transformer (ESWT). ESWT consists of efficient transformation layers (ETLs), allowing a clean structure and avoiding redundant operations. Moreover, we designed a striped window mechanism to obtain a more efficient ESWT in modeling long-term dependencies. To further exploit the potential of the transformer, we propose a novel flexible window training strategy. Without any additional cost, this strategy can further improve the performance of ESWT. Extensive experiments show that the proposed method outperforms state-of-the-art transformer-based LSR methods with fewer parameters, faster inference, smaller FLOPs, and less memory consumption, achieving a better trade-off between model performance and complexity.