 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Efficient Operator Search
Jun 03, 2026Efficient multimodal foundation models often rely on manually designed token-reduction operators, such as pruning, merging, pooling, and adaptive reweighting. Although these operators appear different, we show that they can be interpreted as distinct regimes of a shared operator space. Based on this view, we introduce Efficient Operator Search, a differentiable framework that jointly searches where to reduce tokens, how many tokens to retain, and how reduced token information should be processed. The proposed search space parameterizes layer activation, retention budget, and operator behavior, while the search policy optimizes task performance under one-sided budget and cost constraints. This formulation recovers representative hand-designed baselines as special cases and further discovers hybrid operators beyond isolated manual designs. Experiments on multimodal benchmarks show that the searched operators achieve competitive accuracy-efficiency trade-offs, especially under aggressive visual-token reduction. These results suggest that efficient multimodal inference can be reframed from manual operator design to differentiable operator search.
AnE: Pushing the Reasoning Frontier of Multimodal LLMs via Anchor Evolution
May 25, 2026Post-training via Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) is crucial for enhancing reasoning in Multimodal Large Language Models (MLLMs), yet existing paradigms often reach a performance bottleneck due to the limitations of static data. While current methods leverage self-reflection or self-evolution to push these boundaries, they still suffer from cognitive drift and hallucinated reasoning paths caused by low-quality synthetic data. To address these challenges, we propose Anchor Evolution (AnE), a new paradigm that integrates truth-anchored data curation and model evolution, achieving faithful and steady performance gains at the reasoning frontier. Specifically, we propose Truth Anchor Expansion, which pinpoints the model failing frontier via trajectory rollouts and leverages ground-truth databases to retrieve high-fidelity anchors for faithful data curation. Subsequently, we introduce the Scaffold-Stripping Mechanism to internalize reasoning capabilities. This mechanism first anchors reasoning paths via scaffold-augmented supervision to mitigate the learning complexity and distribution drift of direct SFT on raw data, then leverages RL to strip the scaffold template, thereby effectively transitioning the reasoning paths into intrinsic model capabilities. Experimental results on multimodal reasoning benchmarks show that our method substantially advances the model performance frontier, improving the base model by 10.3\% across eight multimodal benchmarks and achieving state-of-the-art results. The code will be made publicly available.
SlowFocus: Enhancing Fine-grained Temporal Understanding in Video LLM
Feb 03, 2026Large language models (LLMs) have demonstrated exceptional capabilities in text understanding, which has paved the way for their expansion into video LLMs (Vid-LLMs) to analyze video data. However, current Vid-LLMs struggle to simultaneously retain high-quality frame-level semantic information (i.e., a sufficient number of tokens per frame) and comprehensive video-level temporal information (i.e., an adequate number of sampled frames per video). This limitation hinders the advancement of Vid-LLMs towards fine-grained video understanding. To address this issue, we introduce the SlowFocus mechanism, which significantly enhances the equivalent sampling frequency without compromising the quality of frame-level visual tokens. SlowFocus begins by identifying the query-related temporal segment based on the posed question, then performs dense sampling on this segment to extract local high-frequency features. A multi-frequency mixing attention module is further leveraged to aggregate these local high-frequency details with global low-frequency contexts for enhanced temporal comprehension. Additionally, to tailor Vid-LLMs to this innovative mechanism, we introduce a set of training strategies aimed at bolstering both temporal grounding and detailed temporal reasoning capabilities. Furthermore, we establish FineAction-CGR, a benchmark specifically devised to assess the ability of Vid-LLMs to process fine-grained temporal understanding tasks. Comprehensive experiments demonstrate the superiority of our mechanism across both existing public video understanding benchmarks and our proposed FineAction-CGR.
TiKMiX: Take Data Influence into Dynamic Mixture for Language Model Pre-training
Aug 25, 2025The data mixture used in the pre-training of a language model is a cornerstone of its final performance. However, a static mixing strategy is suboptimal, as the model's learning preferences for various data domains shift dynamically throughout training. Crucially, observing these evolving preferences in a computationally efficient manner remains a significant challenge. To address this, we propose TiKMiX, a method that dynamically adjusts the data mixture according to the model's evolving preferences. TiKMiX introduces Group Influence, an efficient metric for evaluating the impact of data domains on the model. This metric enables the formulation of the data mixing problem as a search for an optimal, influence-maximizing distribution. We solve this via two approaches: TiKMiX-D for direct optimization, and TiKMiX-M, which uses a regression model to predict a superior mixture. We trained models with different numbers of parameters, on up to 1 trillion tokens. TiKMiX-D exceeds the performance of state-of-the-art methods like REGMIX while using just 20% of the computational resources. TiKMiX-M leads to an average performance gain of 2% across 9 downstream benchmarks. Our experiments reveal that a model's data preferences evolve with training progress and scale, and we demonstrate that dynamically adjusting the data mixture based on Group Influence, a direct measure of these preferences, significantly improves performance by mitigating the underdigestion of data seen with static ratios.
FreqPrior: Improving Video Diffusion Models with Frequency Filtering Gaussian Noise
Feb 05, 2025

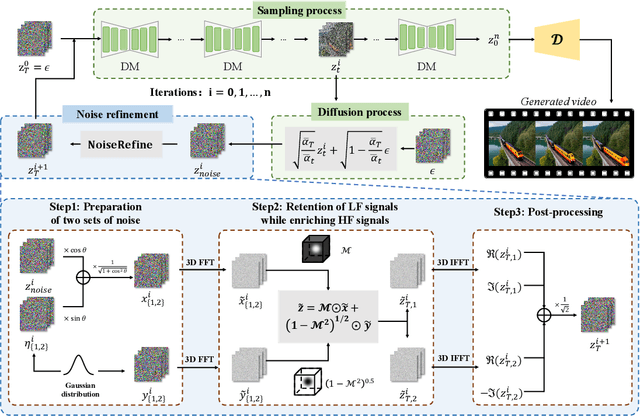

Text-driven video generation has advanced significantly due to developments in diffusion models. Beyond the training and sampling phases, recent studies have investigated noise priors of diffusion models, as improved noise priors yield better generation results. One recent approach employs the Fourier transform to manipulate noise, marking the initial exploration of frequency operations in this context. However, it often generates videos that lack motion dynamics and imaging details. In this work, we provide a comprehensive theoretical analysis of the variance decay issue present in existing methods, contributing to the loss of details and motion dynamics. Recognizing the critical impact of noise distribution on generation quality, we introduce FreqPrior, a novel noise initialization strategy that refines noise in the frequency domain. Our method features a novel filtering technique designed to address different frequency signals while maintaining the noise prior distribution that closely approximates a standard Gaussian distribution. Additionally, we propose a partial sampling process by perturbing the latent at an intermediate timestep during finding the noise prior, significantly reducing inference time without compromising quality. Extensive experiments on VBench demonstrate that our method achieves the highest scores in both quality and semantic assessments, resulting in the best overall total score. These results highlight the superiority of our proposed noise prior.
Brick-Diffusion: Generating Long Videos with Brick-to-Wall Denoising
Jan 06, 2025



Recent advances in diffusion models have greatly improved text-driven video generation. However, training models for long video generation demands significant computational power and extensive data, leading most video diffusion models to be limited to a small number of frames. Existing training-free methods that attempt to generate long videos using pre-trained short video diffusion models often struggle with issues such as insufficient motion dynamics and degraded video fidelity. In this paper, we present Brick-Diffusion, a novel, training-free approach capable of generating long videos of arbitrary length. Our method introduces a brick-to-wall denoising strategy, where the latent is denoised in segments, with a stride applied in subsequent iterations. This process mimics the construction of a staggered brick wall, where each brick represents a denoised segment, enabling communication between frames and improving overall video quality. Through quantitative and qualitative evaluations, we demonstrate that Brick-Diffusion outperforms existing baseline methods in generating high-fidelity videos.
EasyControl: Transfer ControlNet to Video Diffusion for Controllable Generation and Interpolation
Aug 23, 2024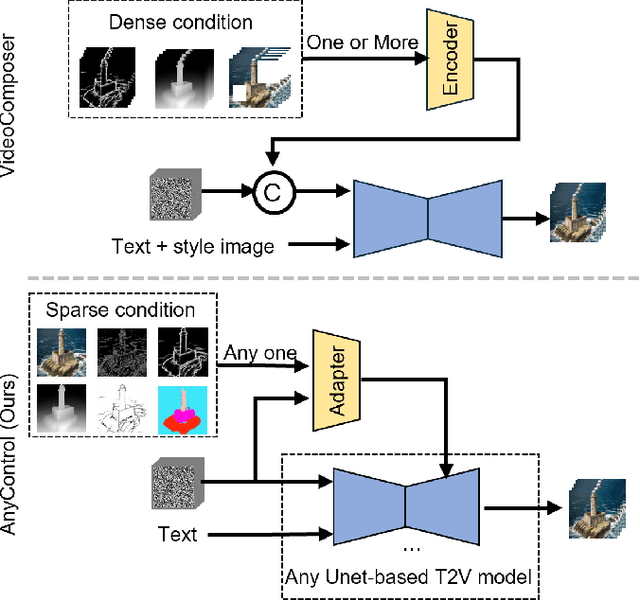

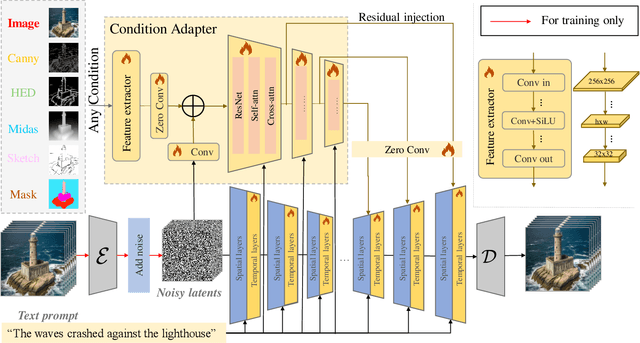

Following the advancements in text-guided image generation technology exemplified by Stable Diffusion, video generation is gaining increased attention in the academic community. However, relying solely on text guidance for video generation has serious limitations, as videos contain much richer content than images, especially in terms of motion. This information can hardly be adequately described with plain text. Fortunately, in computer vision, various visual representations can serve as additional control signals to guide generation. With the help of these signals, video generation can be controlled in finer detail, allowing for greater flexibility for different applications. Integrating various controls, however, is nontrivial. In this paper, we propose a universal framework called EasyControl. By propagating and injecting condition features through condition adapters, our method enables users to control video generation with a single condition map. With our framework, various conditions including raw pixels, depth, HED, etc., can be integrated into different Unet-based pre-trained video diffusion models at a low practical cost. We conduct comprehensive experiments on public datasets, and both quantitative and qualitative results indicate that our method outperforms state-of-the-art methods. EasyControl significantly improves various evaluation metrics across multiple validation datasets compared to previous works. Specifically, for the sketch-to-video generation task, EasyControl achieves an improvement of 152.0 on FVD and 19.9 on IS, respectively, in UCF101 compared with VideoComposer. For fidelity, our model demonstrates powerful image retention ability, resulting in high FVD and IS in UCF101 and MSR-VTT compared to other image-to-video models.
HumanRefiner: Benchmarking Abnormal Human Generation and Refining with Coarse-to-fine Pose-Reversible Guidance
Jul 09, 2024



Text-to-image diffusion models have significantly advanced in conditional image generation. However, these models usually struggle with accurately rendering images featuring humans, resulting in distorted limbs and other anomalies. This issue primarily stems from the insufficient recognition and evaluation of limb qualities in diffusion models. To address this issue, we introduce AbHuman, the first large-scale synthesized human benchmark focusing on anatomical anomalies. This benchmark consists of 56K synthesized human images, each annotated with detailed, bounding-box level labels identifying 147K human anomalies in 18 different categories. Based on this, the recognition of human anomalies can be established, which in turn enhances image generation through traditional techniques such as negative prompting and guidance. To further boost the improvement, we propose HumanRefiner, a novel plug-and-play approach for the coarse-to-fine refinement of human anomalies in text-to-image generation. Specifically, HumanRefiner utilizes a self-diagnostic procedure to detect and correct issues related to both coarse-grained abnormal human poses and fine-grained anomaly levels, facilitating pose-reversible diffusion generation. Experimental results on the AbHuman benchmark demonstrate that HumanRefiner significantly reduces generative discrepancies, achieving a 2.9x improvement in limb quality compared to the state-of-the-art open-source generator SDXL and a 1.4x improvement over DALL-E 3 in human evaluations. Our data and code are available at https://github.com/Enderfga/HumanRefiner.
Self-Adaptive Reality-Guided Diffusion for Artifact-Free Super-Resolution
Mar 25, 2024
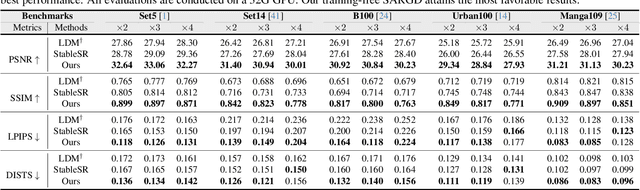
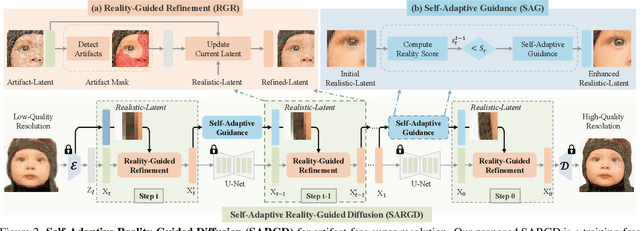
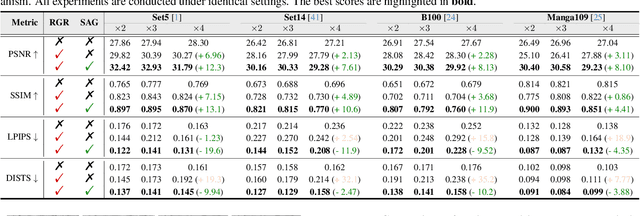
Artifact-free super-resolution (SR) aims to translate low-resolution images into their high-resolution counterparts with a strict integrity of the original content, eliminating any distortions or synthetic details. While traditional diffusion-based SR techniques have demonstrated remarkable abilities to enhance image detail, they are prone to artifact introduction during iterative procedures. Such artifacts, ranging from trivial noise to unauthentic textures, deviate from the true structure of the source image, thus challenging the integrity of the super-resolution process. In this work, we propose Self-Adaptive Reality-Guided Diffusion (SARGD), a training-free method that delves into the latent space to effectively identify and mitigate the propagation of artifacts. Our SARGD begins by using an artifact detector to identify implausible pixels, creating a binary mask that highlights artifacts. Following this, the Reality Guidance Refinement (RGR) process refines artifacts by integrating this mask with realistic latent representations, improving alignment with the original image. Nonetheless, initial realistic-latent representations from lower-quality images result in over-smoothing in the final output. To address this, we introduce a Self-Adaptive Guidance (SAG) mechanism. It dynamically computes a reality score, enhancing the sharpness of the realistic latent. These alternating mechanisms collectively achieve artifact-free super-resolution. Extensive experiments demonstrate the superiority of our method, delivering detailed artifact-free high-resolution images while reducing sampling steps by 2X. We release our code at https://github.com/ProAirVerse/Self-Adaptive-Guidance-Diffusion.git.
PanGu-Draw: Advancing Resource-Efficient Text-to-Image Synthesis with Time-Decoupled Training and Reusable Coop-Diffusion
Dec 29, 2023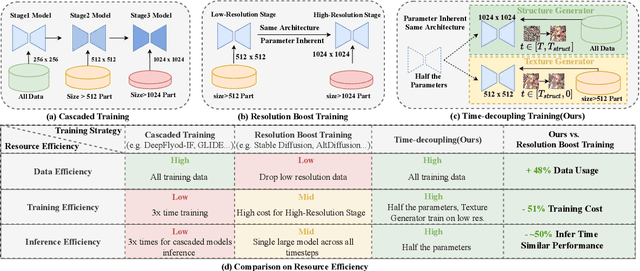

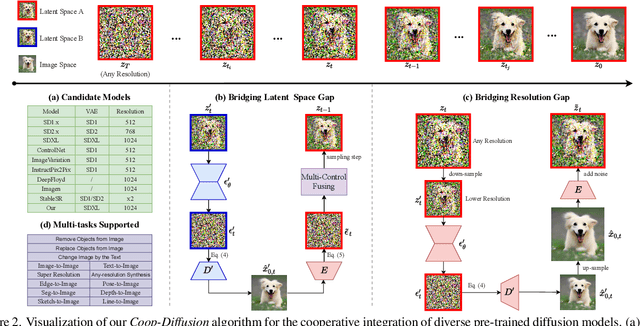

Current large-scale diffusion models represent a giant leap forward in conditional image synthesis, capable of interpreting diverse cues like text, human poses, and edges. However, their reliance on substantial computational resources and extensive data collection remains a bottleneck. On the other hand, the integration of existing diffusion models, each specialized for different controls and operating in unique latent spaces, poses a challenge due to incompatible image resolutions and latent space embedding structures, hindering their joint use. Addressing these constraints, we present "PanGu-Draw", a novel latent diffusion model designed for resource-efficient text-to-image synthesis that adeptly accommodates multiple control signals. We first propose a resource-efficient Time-Decoupling Training Strategy, which splits the monolithic text-to-image model into structure and texture generators. Each generator is trained using a regimen that maximizes data utilization and computational efficiency, cutting data preparation by 48% and reducing training resources by 51%. Secondly, we introduce "Coop-Diffusion", an algorithm that enables the cooperative use of various pre-trained diffusion models with different latent spaces and predefined resolutions within a unified denoising process. This allows for multi-control image synthesis at arbitrary resolutions without the necessity for additional data or retraining. Empirical validations of Pangu-Draw show its exceptional prowess in text-to-image and multi-control image generation, suggesting a promising direction for future model training efficiencies and generation versatility. The largest 5B T2I PanGu-Draw model is released on the Ascend platform. Project page: $\href{https://pangu-draw.github.io}{this~https~URL}$