 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyControl: Transfer ControlNet to Video Diffusion for Controllable Generation and Interpolation
Paper and Code
Aug 23, 2024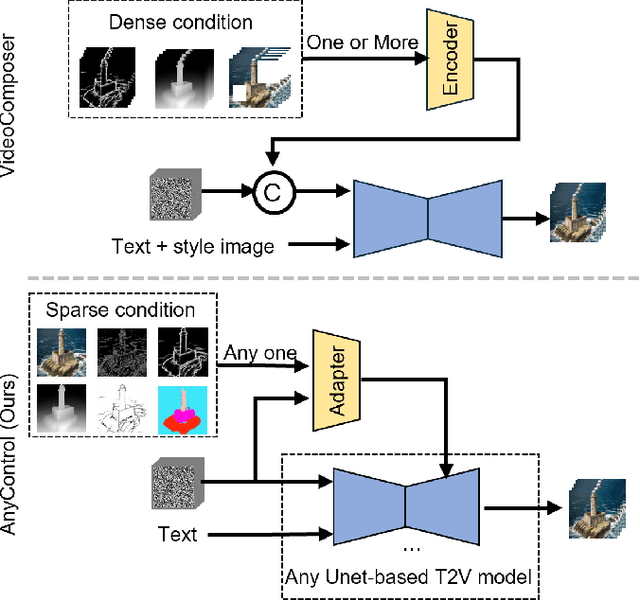

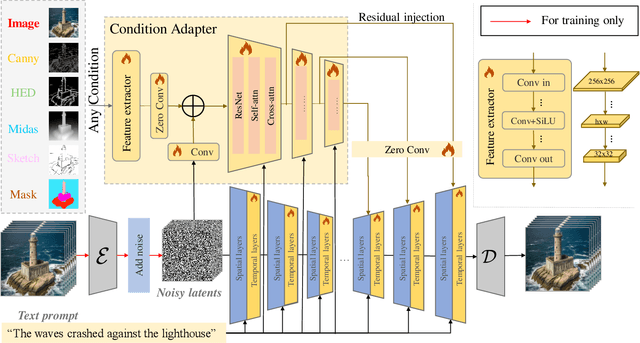

Following the advancements in text-guided image generation technology exemplified by Stable Diffusion, video generation is gaining increased attention in the academic community. However, relying solely on text guidance for video generation has serious limitations, as videos contain much richer content than images, especially in terms of motion. This information can hardly be adequately described with plain text. Fortunately, in computer vision, various visual representations can serve as additional control signals to guide generation. With the help of these signals, video generation can be controlled in finer detail, allowing for greater flexibility for different applications. Integrating various controls, however, is nontrivial. In this paper, we propose a universal framework called EasyControl. By propagating and injecting condition features through condition adapters, our method enables users to control video generation with a single condition map. With our framework, various conditions including raw pixels, depth, HED, etc., can be integrated into different Unet-based pre-trained video diffusion models at a low practical cost. We conduct comprehensive experiments on public datasets, and both quantitative and qualitative results indicate that our method outperforms state-of-the-art methods. EasyControl significantly improves various evaluation metrics across multiple validation datasets compared to previous works. Specifically, for the sketch-to-video generation task, EasyControl achieves an improvement of 152.0 on FVD and 19.9 on IS, respectively, in UCF101 compared with VideoComposer. For fidelity, our model demonstrates powerful image retention ability, resulting in high FVD and IS in UCF101 and MSR-VTT compared to other image-to-video models.