 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyCrowd: Instance-Isolated Identity-Pose Binding for Arbitrary Multi-Character Animation
Mar 16, 2026Controllable character animation has advanced rapidly in recent years, yet multi-character animation remains underexplored. As the number of characters grows, multi-character reference encoding becomes more susceptible to latent identity entanglement, resulting in identity bleeding and reduced controllability. Moreover, learning precise and spatio-temporally consistent correspondences between reference identities and driving pose sequences becomes increasingly challenging, often leading to identity-pose mis-binding and inconsistency in generated videos. To address these challenges, we propose AnyCrowd, a Diffusion Transformer (DiT)-based video generation framework capable of scaling to an arbitrary number of characters. Specifically, we first introduce an Instance-Isolated Latent Representation (IILR), which encodes character instances independently prior to DiT processing to prevent latent identity entanglement. Building on this disentangled representation, we further propose Tri-Stage Decoupled Attention (TSDA) to bind identities to driving poses by decomposing self-attention into: (i) instance-aware foreground attention, (ii) background-centric interaction, and (iii) global foreground-background coordination. Furthermore, to mitigate token ambiguity in overlapping regions, an Adaptive Gated Fusion (AGF) module is integrated within TSDA to predict identity-aware weights, effectively fusing competing token groups into identity-consistent representations...
Training-Free Self-Correction for Multimodal Masked Diffusion Models
Feb 02, 2026Masked diffusion models have emerged as a powerful framework for text and multimodal generation. However, their sampling procedure updates multiple tokens simultaneously and treats generated tokens as immutable, which may lead to error accumulation when early mistakes cannot be revised. In this work, we revisit existing self-correction methods and identify limitations stemming from additional training requirements or reliance on misaligned likelihood estimates. We propose a training-free self-correction framework that exploits the inductive biases of pre-trained masked diffusion models. Without modifying model parameters or introducing auxiliary evaluators, our method significantly improves generation quality on text-to-image generation and multimodal understanding tasks with reduced sampling steps. Moreover, the proposed framework generalizes across different masked diffusion architectures, highlighting its robustness and practical applicability. Code can be found in https://github.com/huge123/FreeCorrection.
DirectSwap: Mask-Free Cross-Identity Training and Benchmarking for Expression-Consistent Video Head Swapping
Dec 10, 2025
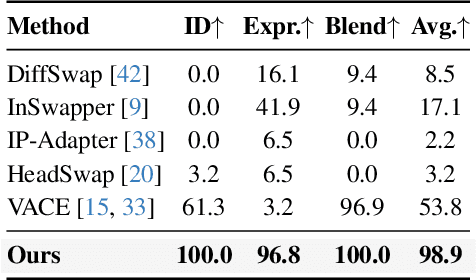
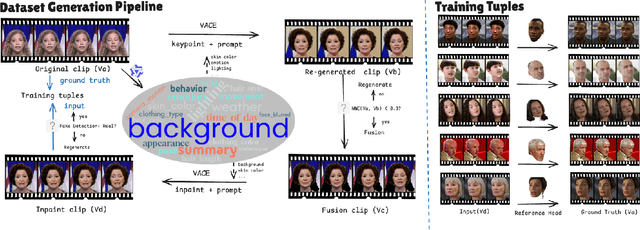
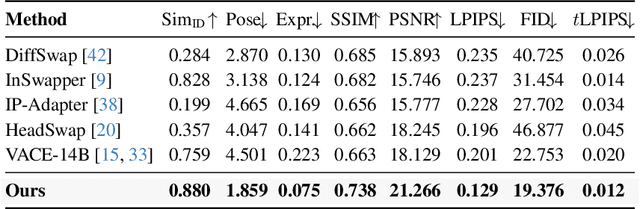
Video head swapping aims to replace the entire head of a video subject, including facial identity, head shape, and hairstyle, with that of a reference image, while preserving the target body, background, and motion dynamics. Due to the lack of ground-truth paired swapping data, prior methods typically train on cross-frame pairs of the same person within a video and rely on mask-based inpainting to mitigate identity leakage. Beyond potential boundary artifacts, this paradigm struggles to recover essential cues occluded by the mask, such as facial pose, expressions, and motion dynamics. To address these issues, we prompt a video editing model to synthesize new heads for existing videos as fake swapping inputs, while maintaining frame-synchronized facial poses and expressions. This yields HeadSwapBench, the first cross-identity paired dataset for video head swapping, which supports both training (\TrainNum{} videos) and benchmarking (\TestNum{} videos) with genuine outputs. Leveraging this paired supervision, we propose DirectSwap, a mask-free, direct video head-swapping framework that extends an image U-Net into a video diffusion model with a motion module and conditioning inputs. Furthermore, we introduce the Motion- and Expression-Aware Reconstruction (MEAR) loss, which reweights the diffusion loss per pixel using frame-difference magnitudes and facial-landmark proximity, thereby enhancing cross-frame coherence in motion and expressions. Extensive experiments demonstrate that DirectSwap achieves state-of-the-art visual quality, identity fidelity, and motion and expression consistency across diverse in-the-wild video scenes. We will release the source code and the HeadSwapBench dataset to facilitate future research.
LaVieID: Local Autoregressive Diffusion Transformers for Identity-Preserving Video Creation
Aug 11, 2025

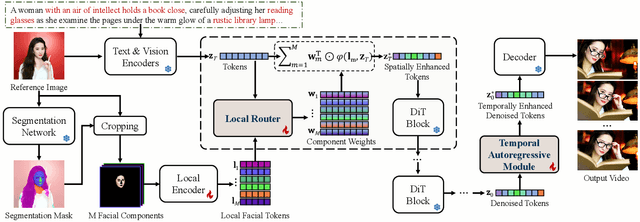

In this paper, we present LaVieID, a novel \underline{l}ocal \underline{a}utoregressive \underline{vi}d\underline{e}o diffusion framework designed to tackle the challenging \underline{id}entity-preserving text-to-video task. The key idea of LaVieID is to mitigate the loss of identity information inherent in the stochastic global generation process of diffusion transformers (DiTs) from both spatial and temporal perspectives. Specifically, unlike the global and unstructured modeling of facial latent states in existing DiTs, LaVieID introduces a local router to explicitly represent latent states by weighted combinations of fine-grained local facial structures. This alleviates undesirable feature interference and encourages DiTs to capture distinctive facial characteristics. Furthermore, a temporal autoregressive module is integrated into LaVieID to refine denoised latent tokens before video decoding. This module divides latent tokens temporally into chunks, exploiting their long-range temporal dependencies to predict biases for rectifying tokens, thereby significantly enhancing inter-frame identity consistency. Consequently, LaVieID can generate high-fidelity personalized videos and achieve state-of-the-art performance. Our code and models are available at https://github.com/ssugarwh/LaVieID.
BridgeIV: Bridging Customized Image and Video Generation through Test-Time Autoregressive Identity Propagation
May 11, 2025



Both zero-shot and tuning-based customized text-to-image (CT2I) generation have made significant progress for storytelling content creation. In contrast, research on customized text-to-video (CT2V) generation remains relatively limited. Existing zero-shot CT2V methods suffer from poor generalization, while another line of work directly combining tuning-based T2I models with temporal motion modules often leads to the loss of structural and texture information. To bridge this gap, we propose an autoregressive structure and texture propagation module (STPM), which extracts key structural and texture features from the reference subject and injects them autoregressively into each video frame to enhance consistency. Additionally, we introduce a test-time reward optimization (TTRO) method to further refine fine-grained details. Quantitative and qualitative experiments validate the effectiveness of STPM and TTRO, demonstrating improvements of 7.8 and 13.1 in CLIP-I and DINO consistency metrics over the baseline, respectively.
A multi-purpose automatic editing system based on lecture semantics for remote education
Nov 07, 2024



Remote teaching has become popular recently due to its convenience and safety, especially under extreme circumstances like a pandemic. However, online students usually have a poor experience since the information acquired from the views provided by the broadcast platforms is limited. One potential solution is to show more camera views simultaneously, but it is technically challenging and distracting for the viewers. Therefore, an automatic multi-camera directing/editing system, which aims at selecting the most concerned view at each time instance to guide the attention of online students, is in urgent demand. However, existing systems mostly make simple assumptions and focus on tracking the position of the speaker instead of the real lecture semantics, and therefore have limited capacities to deliver optimal information flow. To this end, this paper proposes an automatic multi-purpose editing system based on the lecture semantics, which can both direct the multiple video streams for real-time broadcasting and edit the optimal video offline for review purposes. Our system directs the views by semantically analyzing the class events while following the professional directing rules, mimicking a human director to capture the regions of interest from the viewpoint of the onsite students. We conduct both qualitative and quantitative analyses to verify the effectiveness of the proposed system and its components.
StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration
Nov 07, 2024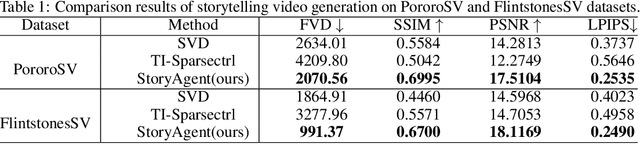
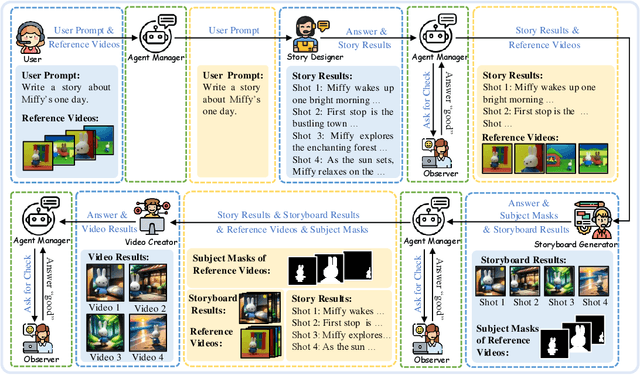


The advent of AI-Generated Content (AIGC) has spurred research into automated video generation to streamline conventional processes. However, automating storytelling video production, particularly for customized narratives, remains challenging due to the complexity of maintaining subject consistency across shots. While existing approaches like Mora and AesopAgent integrate multiple agents for Story-to-Video (S2V) generation, they fall short in preserving protagonist consistency and supporting Customized Storytelling Video Generation (CSVG). To address these limitations, we propose StoryAgent, a multi-agent framework designed for CSVG. StoryAgent decomposes CSVG into distinct subtasks assigned to specialized agents, mirroring the professional production process. Notably, our framework includes agents for story design, storyboard generation, video creation, agent coordination, and result evaluation. Leveraging the strengths of different models, StoryAgent enhances control over the generation process, significantly improving character consistency. Specifically, we introduce a customized Image-to-Video (I2V) method, LoRA-BE, to enhance intra-shot temporal consistency, while a novel storyboard generation pipeline is proposed to maintain subject consistency across shots. Extensive experiments demonstrate the effectiveness of our approach in synthesizing highly consistent storytelling videos, outperforming state-of-the-art methods. Our contributions include the introduction of StoryAgent, a versatile framework for video generation tasks, and novel techniques for preserving protagonist consistency.
A Reinforcement Learning-Based Automatic Video Editing Method Using Pre-trained Vision-Language Model
Nov 07, 2024



In this era of videos, automatic video editing techniques attract more and more attention from industry and academia since they can reduce workloads and lower the requirements for human editors. Existing automatic editing systems are mainly scene- or event-specific, e.g., soccer game broadcasting, yet the automatic systems for general editing, e.g., movie or vlog editing which covers various scenes and events, were rarely studied before, and converting the event-driven editing method to a general scene is nontrivial. In this paper, we propose a two-stage scheme for general editing. Firstly, unlike previous works that extract scene-specific features, we leverage the pre-trained Vision-Language Model (VLM) to extract the editing-relevant representations as editing context. Moreover, to close the gap between the professional-looking videos and the automatic productions generated with simple guidelines, we propose a Reinforcement Learning (RL)-based editing framework to formulate the editing problem and train the virtual editor to make better sequential editing decisions. Finally, we evaluate the proposed method on a more general editing task with a real movie dataset. Experimental results demonstrate the effectiveness and benefits of the proposed context representation and the learning ability of our RL-based editing framework.
Sitcom-Crafter: A Plot-Driven Human Motion Generation System in 3D Scenes
Oct 14, 2024
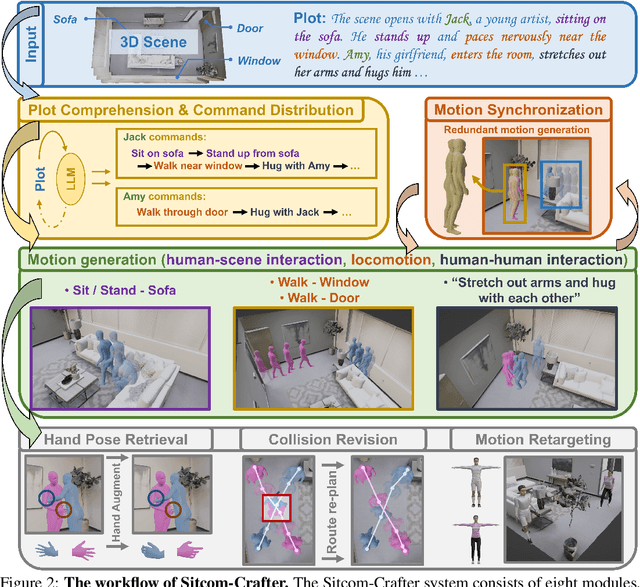
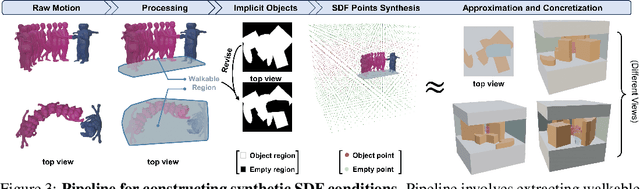
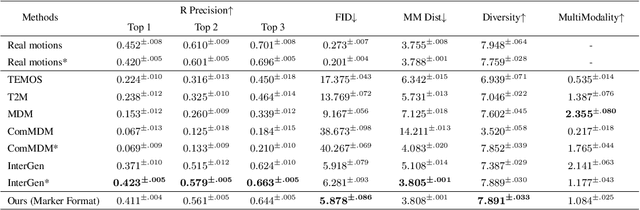
Recent advancements in human motion synthesis have focused on specific types of motions, such as human-scene interaction, locomotion or human-human interaction, however, there is a lack of a unified system capable of generating a diverse combination of motion types. In response, we introduce Sitcom-Crafter, a comprehensive and extendable system for human motion generation in 3D space, which can be guided by extensive plot contexts to enhance workflow efficiency for anime and game designers. The system is comprised of eight modules, three of which are dedicated to motion generation, while the remaining five are augmentation modules that ensure consistent fusion of motion sequences and system functionality. Central to the generation modules is our novel 3D scene-aware human-human interaction module, which addresses collision issues by synthesizing implicit 3D Signed Distance Function (SDF) points around motion spaces, thereby minimizing human-scene collisions without additional data collection costs. Complementing this, our locomotion and human-scene interaction modules leverage existing methods to enrich the system's motion generation capabilities. Augmentation modules encompass plot comprehension for command generation, motion synchronization for seamless integration of different motion types, hand pose retrieval to enhance motion realism, motion collision revision to prevent human collisions, and 3D retargeting to ensure visual fidelity. Experimental evaluations validate the system's ability to generate high-quality, diverse, and physically realistic motions, underscoring its potential for advancing creative workflows.
EasyControl: Transfer ControlNet to Video Diffusion for Controllable Generation and Interpolation
Aug 23, 2024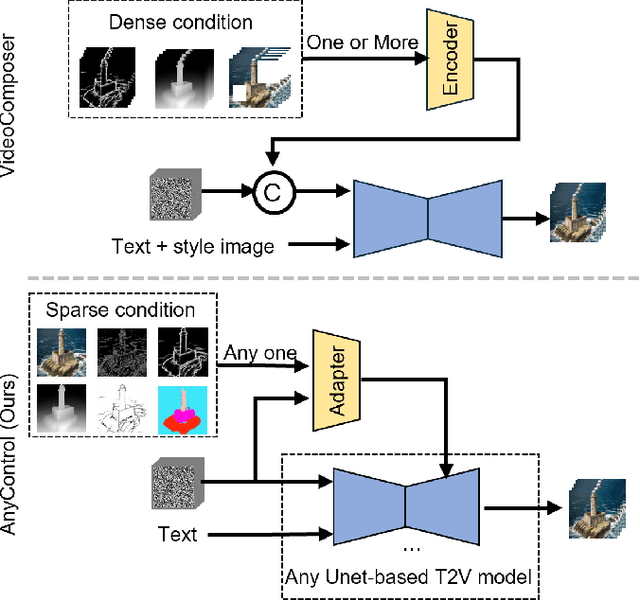

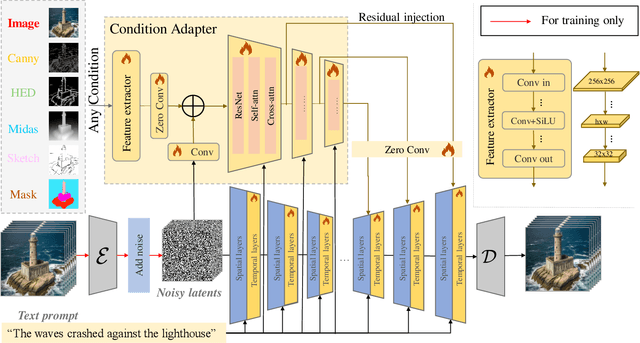

Following the advancements in text-guided image generation technology exemplified by Stable Diffusion, video generation is gaining increased attention in the academic community. However, relying solely on text guidance for video generation has serious limitations, as videos contain much richer content than images, especially in terms of motion. This information can hardly be adequately described with plain text. Fortunately, in computer vision, various visual representations can serve as additional control signals to guide generation. With the help of these signals, video generation can be controlled in finer detail, allowing for greater flexibility for different applications. Integrating various controls, however, is nontrivial. In this paper, we propose a universal framework called EasyControl. By propagating and injecting condition features through condition adapters, our method enables users to control video generation with a single condition map. With our framework, various conditions including raw pixels, depth, HED, etc., can be integrated into different Unet-based pre-trained video diffusion models at a low practical cost. We conduct comprehensive experiments on public datasets, and both quantitative and qualitative results indicate that our method outperforms state-of-the-art methods. EasyControl significantly improves various evaluation metrics across multiple validation datasets compared to previous works. Specifically, for the sketch-to-video generation task, EasyControl achieves an improvement of 152.0 on FVD and 19.9 on IS, respectively, in UCF101 compared with VideoComposer. For fidelity, our model demonstrates powerful image retention ability, resulting in high FVD and IS in UCF101 and MSR-VTT compared to other image-to-video models.