 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Inpainting to Editing: A Self-Bootstrapping Framework for Context-Rich Visual Dubbing
Dec 31, 2025Audio-driven visual dubbing aims to synchronize a video's lip movements with new speech, but is fundamentally challenged by the lack of ideal training data: paired videos where only a subject's lip movements differ while all other visual conditions are identical. Existing methods circumvent this with a mask-based inpainting paradigm, where an incomplete visual conditioning forces models to simultaneously hallucinate missing content and sync lips, leading to visual artifacts, identity drift, and poor synchronization. In this work, we propose a novel self-bootstrapping framework that reframes visual dubbing from an ill-posed inpainting task into a well-conditioned video-to-video editing problem. Our approach employs a Diffusion Transformer, first as a data generator, to synthesize ideal training data: a lip-altered companion video for each real sample, forming visually aligned video pairs. A DiT-based audio-driven editor is then trained on these pairs end-to-end, leveraging the complete and aligned input video frames to focus solely on precise, audio-driven lip modifications. This complete, frame-aligned input conditioning forms a rich visual context for the editor, providing it with complete identity cues, scene interactions, and continuous spatiotemporal dynamics. Leveraging this rich context fundamentally enables our method to achieve highly accurate lip sync, faithful identity preservation, and exceptional robustness against challenging in-the-wild scenarios. We further introduce a timestep-adaptive multi-phase learning strategy as a necessary component to disentangle conflicting editing objectives across diffusion timesteps, thereby facilitating stable training and yielding enhanced lip synchronization and visual fidelity. Additionally, we propose ContextDubBench, a comprehensive benchmark dataset for robust evaluation in diverse and challenging practical application scenarios.
UnityVideo: Unified Multi-Modal Multi-Task Learning for Enhancing World-Aware Video Generation
Dec 08, 2025Recent video generation models demonstrate impressive synthesis capabilities but remain limited by single-modality conditioning, constraining their holistic world understanding. This stems from insufficient cross-modal interaction and limited modal diversity for comprehensive world knowledge representation. To address these limitations, we introduce UnityVideo, a unified framework for world-aware video generation that jointly learns across multiple modalities (segmentation masks, human skeletons, DensePose, optical flow, and depth maps) and training paradigms. Our approach features two core components: (1) dynamic noising to unify heterogeneous training paradigms, and (2) a modality switcher with an in-context learner that enables unified processing via modular parameters and contextual learning. We contribute a large-scale unified dataset with 1.3M samples. Through joint optimization, UnityVideo accelerates convergence and significantly enhances zero-shot generalization to unseen data. We demonstrate that UnityVideo achieves superior video quality, consistency, and improved alignment with physical world constraints. Code and data can be found at: https://github.com/dvlab-research/UnityVideo
LaVieID: Local Autoregressive Diffusion Transformers for Identity-Preserving Video Creation
Aug 11, 2025

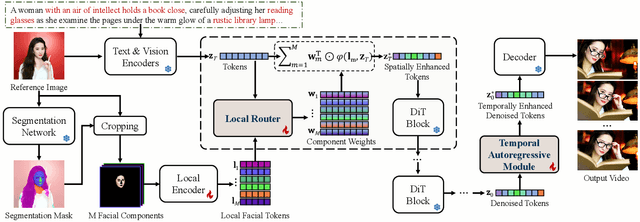

In this paper, we present LaVieID, a novel \underline{l}ocal \underline{a}utoregressive \underline{vi}d\underline{e}o diffusion framework designed to tackle the challenging \underline{id}entity-preserving text-to-video task. The key idea of LaVieID is to mitigate the loss of identity information inherent in the stochastic global generation process of diffusion transformers (DiTs) from both spatial and temporal perspectives. Specifically, unlike the global and unstructured modeling of facial latent states in existing DiTs, LaVieID introduces a local router to explicitly represent latent states by weighted combinations of fine-grained local facial structures. This alleviates undesirable feature interference and encourages DiTs to capture distinctive facial characteristics. Furthermore, a temporal autoregressive module is integrated into LaVieID to refine denoised latent tokens before video decoding. This module divides latent tokens temporally into chunks, exploiting their long-range temporal dependencies to predict biases for rectifying tokens, thereby significantly enhancing inter-frame identity consistency. Consequently, LaVieID can generate high-fidelity personalized videos and achieve state-of-the-art performance. Our code and models are available at https://github.com/ssugarwh/LaVieID.
BridgeIV: Bridging Customized Image and Video Generation through Test-Time Autoregressive Identity Propagation
May 11, 2025



Both zero-shot and tuning-based customized text-to-image (CT2I) generation have made significant progress for storytelling content creation. In contrast, research on customized text-to-video (CT2V) generation remains relatively limited. Existing zero-shot CT2V methods suffer from poor generalization, while another line of work directly combining tuning-based T2I models with temporal motion modules often leads to the loss of structural and texture information. To bridge this gap, we propose an autoregressive structure and texture propagation module (STPM), which extracts key structural and texture features from the reference subject and injects them autoregressively into each video frame to enhance consistency. Additionally, we introduce a test-time reward optimization (TTRO) method to further refine fine-grained details. Quantitative and qualitative experiments validate the effectiveness of STPM and TTRO, demonstrating improvements of 7.8 and 13.1 in CLIP-I and DINO consistency metrics over the baseline, respectively.
ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving
Apr 25, 2024



Diffusion-based technologies have made significant strides, particularly in personalized and customized facialgeneration. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face. To address these limitations, we introduce ConsistentID, an innovative method crafted for diverseidentity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image. ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consistency in facial regions. Together, these components significantly enhance the accuracy of ID preservation by introducing fine-grained multimodal ID information from facial regions. To facilitate training of ConsistentID, we present a fine-grained portrait dataset, FGID, with over 500,000 facial images, offering greater diversity and comprehensiveness than existing public facial datasets. % such as LAION-Face, CelebA, FFHQ, and SFHQ. Experimental results substantiate that our ConsistentID achieves exceptional precision and diversity in personalized facial generation, surpassing existing methods in the MyStyle dataset. Furthermore, while ConsistentID introduces more multimodal ID information, it maintains a fast inference speed during generation.