 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Unit: A New Perspective on Materials Science Research Paradigms
Mar 11, 2025New materials have long marked the civilization level, serving as an impetus for technological progress and societal transformation. The classic structure-property correlations were key of materials science and engineering. However, the knowledge of materials faces significant challenges in adapting to exclusively data-driven approaches for new material discovery. This perspective introduces the concepts of functional units (FUs) to fill the gap in understanding of material structure-property correlations and knowledge inheritance as the "composition-microstructure" paradigm transitions to a data-driven AI paradigm transitions. Firstly, we provide a bird's-eye view of the research paradigm evolution from early "process-structure-properties-performance" to contemporary data-driven AI new trend. Next, we highlight recent advancements in the characterization of functional units across diverse material systems, emphasizing their critical role in multiscale material design. Finally, we discuss the integration of functional units into the new AI-driven paradigm of materials science, addressing both opportunities and challenges in computational materials innovation.
Global Universal Scaling and Ultra-Small Parameterization in Machine Learning Interatomic Potentials with Super-Linearity
Feb 11, 2025



Using machine learning (ML) to construct interatomic interactions and thus potential energy surface (PES) has become a common strategy for materials design and simulations. However, those current models of machine learning interatomic potential (MLIP) provide no relevant physical constrains, and thus may owe intrinsic out-of-domain difficulty which underlies the challenges of model generalizability and physical scalability. Here, by incorporating physics-informed Universal-Scaling law and nonlinearity-embedded interaction function, we develop a Super-linear MLIP with both Ultra-Small parameterization and greatly expanded expressive capability, named SUS2-MLIP. Due to the global scaling rooting in universal equation of state (UEOS), SUS2-MLIP not only has significantly-reduced parameters by decoupling the element space from coordinate space, but also naturally outcomes the out-of-domain difficulty and endows the potentials with inherent generalizability and scalability even with relatively small training dataset. The nonlinearity-enbeding transformation for interaction function expands the expressive capability and make the potentials super-linear. The SUS2-MLIP outperforms the state-of-the-art MLIP models with its exceptional computational efficiency especially for multiple-element materials and physical scalability in property prediction. This work not only presents a highly-efficient universal MLIP model but also sheds light on incorporating physical constraints into artificial-intelligence-aided materials simulation.
Advanced Object Detection and Pose Estimation with Hybrid Task Cascade and High-Resolution Networks
Feb 06, 2025In the field of computer vision, 6D object detection and pose estimation are critical for applications such as robotics, augmented reality, and autonomous driving. Traditional methods often struggle with achieving high accuracy in both object detection and precise pose estimation simultaneously. This study proposes an improved 6D object detection and pose estimation pipeline based on the existing 6D-VNet framework, enhanced by integrating a Hybrid Task Cascade (HTC) and a High-Resolution Network (HRNet) backbone. By leveraging the strengths of HTC's multi-stage refinement process and HRNet's ability to maintain high-resolution representations, our approach significantly improves detection accuracy and pose estimation precision. Furthermore, we introduce advanced post-processing techniques and a novel model integration strategy that collectively contribute to superior performance on public and private benchmarks. Our method demonstrates substantial improvements over state-of-the-art models, making it a valuable contribution to the domain of 6D object detection and pose estimation.
ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
CatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025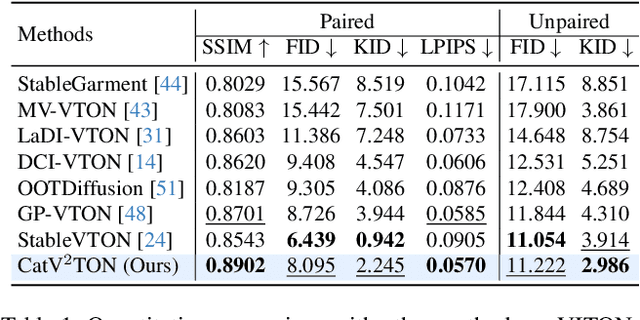
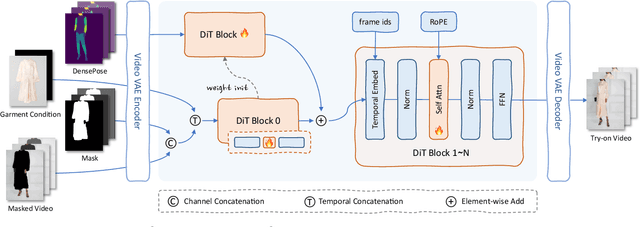
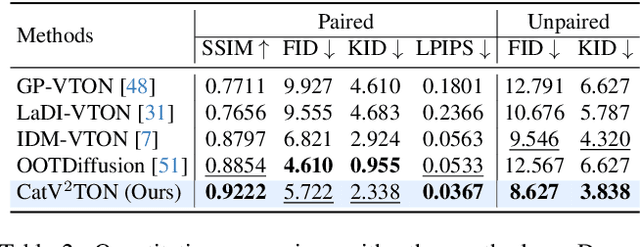
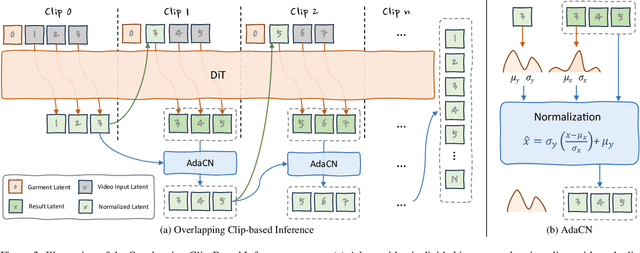
Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
Generating Multimodal Images with GAN: Integrating Text, Image, and Style
Jan 04, 2025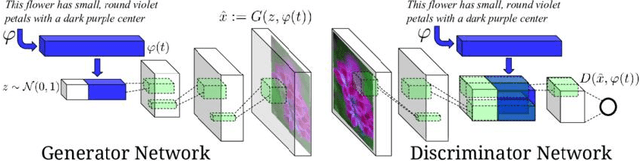
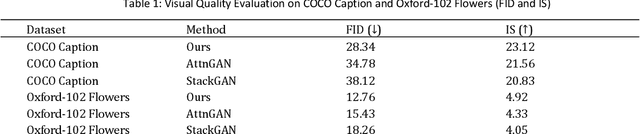

In the field of computer vision, multimodal image generation has become a research hotspot, especially the task of integrating text, image, and style. In this study, we propose a multimodal image generation method based on Generative Adversarial Networks (GAN), capable of effectively combining text descriptions, reference images, and style information to generate images that meet multimodal requirements. This method involves the design of a text encoder, an image feature extractor, and a style integration module, ensuring that the generated images maintain high quality in terms of visual content and style consistency. We also introduce multiple loss functions, including adversarial loss, text-image consistency loss, and style matching loss, to optimize the generation process. Experimental results show that our method produces images with high clarity and consistency across multiple public datasets, demonstrating significant performance improvements compared to existing methods. The outcomes of this study provide new insights into multimodal image generation and present broad application prospects.
Advanced Risk Prediction and Stability Assessment of Banks Using Time Series Transformer Models
Dec 04, 2024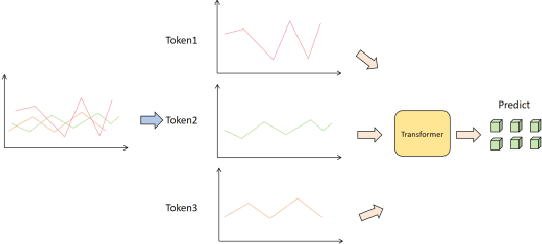
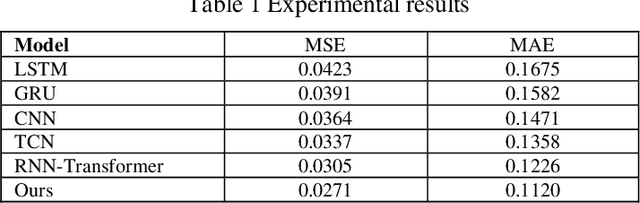
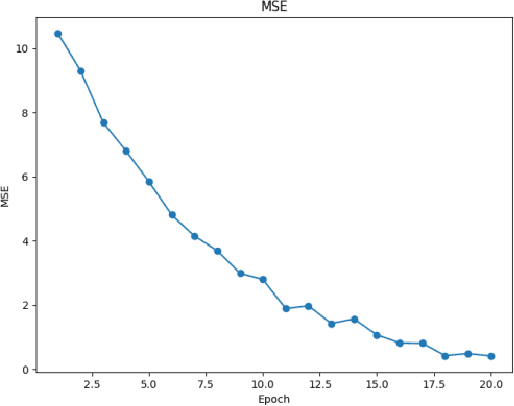
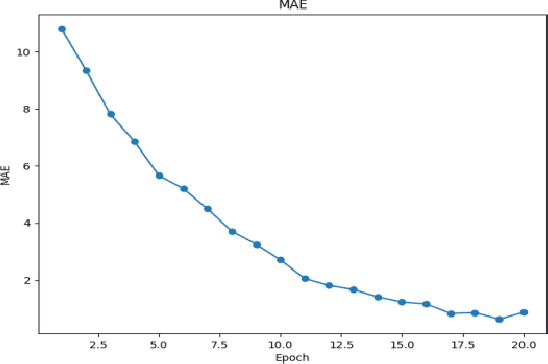
This paper aims to study the prediction of the bank stability index based on the Time Series Transformer model. The bank stability index is an important indicator to measure the health status and risk resistance of financial institutions. Traditional prediction methods are difficult to adapt to complex market changes because they rely on single-dimensional macroeconomic data. This paper proposes a prediction framework based on the Time Series Transformer, which uses the self-attention mechanism of the model to capture the complex temporal dependencies and nonlinear relationships in financial data. Through experiments, we compare the model with LSTM, GRU, CNN, TCN and RNN-Transformer models. The experimental results show that the Time Series Transformer model outperforms other models in both mean square error (MSE) and mean absolute error (MAE) evaluation indicators, showing strong prediction ability. This shows that the Time Series Transformer model can better handle multidimensional time series data in bank stability prediction, providing new technical approaches and solutions for financial risk management.
Mitigating Knowledge Conflicts in Language Model-Driven Question Answering
Nov 18, 2024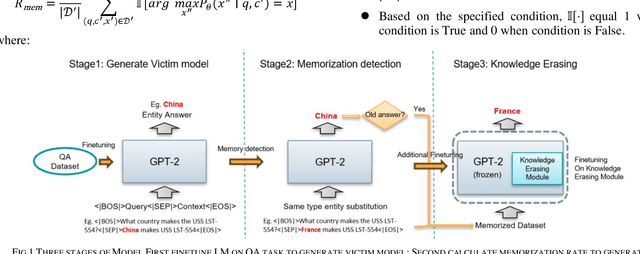


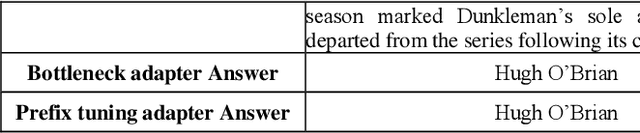
Knowledge-aware sequence to sequence generation tasks such as document question answering and abstract summarization typically requires two types of knowledge: encoded parametric knowledge and retrieved contextual information. Previous work show improper correlation between parametric knowledge and answers in the training set could cause the model ignore input information at test time, resulting in un-desirable model behaviour such as over-stability and hallucination. In this work, we argue that hallucination could be mitigated via explicit correlation between input source and generated content. We focus on a typical example of hallucination, entity-based knowledge conflicts in question answering, where correlation of entities and their description at training time hinders model behaviour during inference.
Pseudo-Probability Unlearning: Towards Efficient and Privacy-Preserving Machine Unlearning
Nov 04, 2024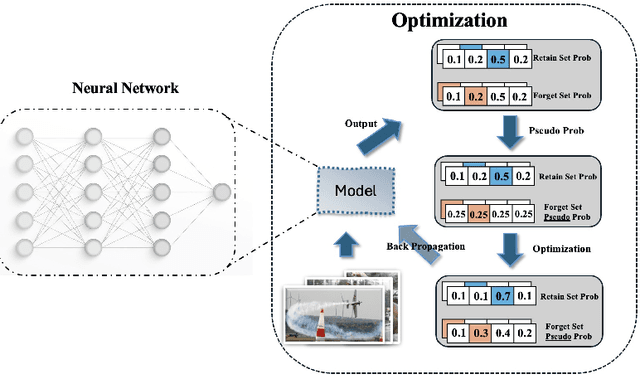
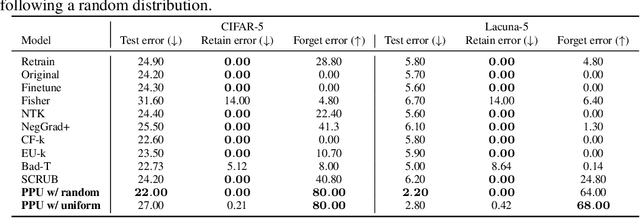
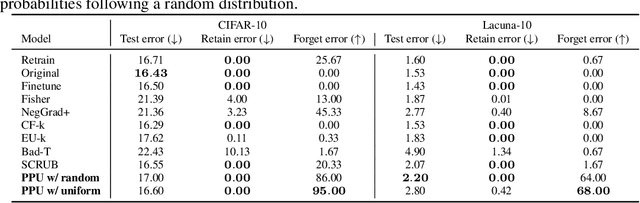
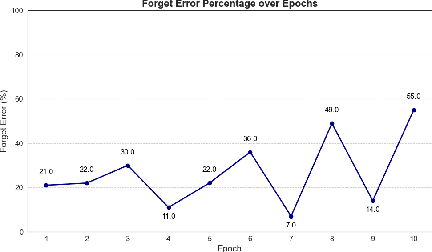
Machine unlearning--enabling a trained model to forget specific data--is crucial for addressing biased data and adhering to privacy regulations like the General Data Protection Regulation (GDPR)'s "right to be forgotten". Recent works have paid little attention to privacy concerns, leaving the data intended for forgetting vulnerable to membership inference attacks. Moreover, they often come with high computational overhead. In this work, we propose Pseudo-Probability Unlearning (PPU), a novel method that enables models to forget data efficiently and in a privacy-preserving manner. Our method replaces the final-layer output probabilities of the neural network with pseudo-probabilities for the data to be forgotten. These pseudo-probabilities follow either a uniform distribution or align with the model's overall distribution, enhancing privacy and reducing risk of membership inference attacks. Our optimization strategy further refines the predictive probability distributions and updates the model's weights accordingly, ensuring effective forgetting with minimal impact on the model's overall performance. Through comprehensive experiments on multiple benchmarks, our method achieves over 20% improvements in forgetting error compared to the state-of-the-art. Additionally, our method enhances privacy by preventing the forgotten set from being inferred to around random guesses.
Integration of Mamba and Transformer -- MAT for Long-Short Range Time Series Forecasting with Application to Weather Dynamics
Sep 13, 2024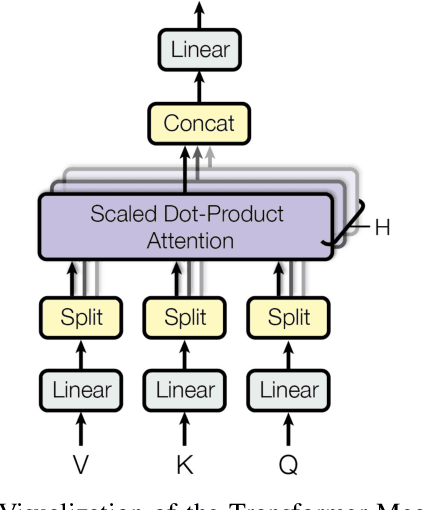
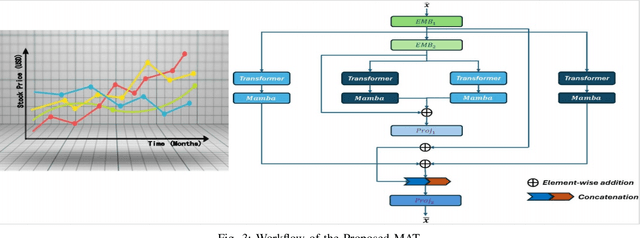
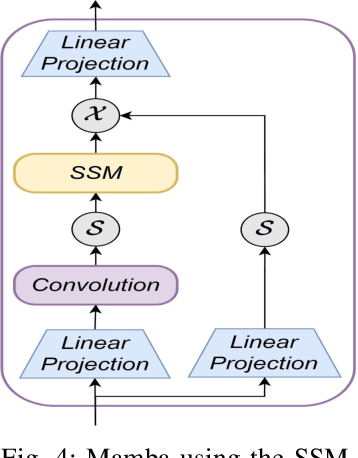
Long-short range time series forecasting is essential for predicting future trends and patterns over extended periods. While deep learning models such as Transformers have made significant strides in advancing time series forecasting, they often encounter difficulties in capturing long-term dependencies and effectively managing sparse semantic features. The state-space model, Mamba, addresses these issues through its adept handling of selective input and parallel computing, striking a balance between computational efficiency and prediction accuracy. This article examines the advantages and disadvantages of both Mamba and Transformer models, and introduces a combined approach, MAT, which leverages the strengths of each model to capture unique long-short range dependencies and inherent evolutionary patterns in multivariate time series. Specifically, MAT harnesses the long-range dependency capabilities of Mamba and the short-range characteristics of Transformers. Experimental results on benchmark weather datasets demonstrate that MAT outperforms existing comparable methods in terms of prediction accuracy, scalability, and memory efficiency.