 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Blood Draw: Explainable Machine Learning for Non-Invasive Dysglycemia Risk Screening
Jun 14, 2026Dysglycemia, encompassing both prediabetes and diabetes, affects huge numbers of adults worldwide, yet many of them remain undiagnosed. We developed and validated machine-learning (ML) models for non-invasive screening of dysglycemia risk that require no laboratory tests. Pooling data from the National Health and Nutrition Examination Survey (NHANES) 2017--2023 (n=14,352), we trained six ML models with stratified 5-fold cross-validation and compared them with two established clinical risk scores. LightGBM achieved the highest area under the receiver operating characteristic curve (AUC=0.820, 95% CI: 0.806--0.835), outperforming the Finnish Diabetes Risk Score (0.745) and American Diabetes Association Risk Test (0.783). SHAP analysis identified age, race/ethnicity, and waist-to-height ratio as the most influential predictors. Subgroup analyses confirmed consistent performance across demographic strata (AUC: 0.735--0.832). These results demonstrate the feasibility of explainable, laboratory-free dysglycemia screening for deployment in community settings and self-tracking health applications.
Flow-based Gaussian Splatting for Continuous-Scale Remote Sensing Image Super-Resolution
May 21, 2026High-resolution remote sensing images (RSIs) are crucial for Earth observation applications, yet acquiring them is often limited by sensor constraints and costs. In recent years, generative super-resolution (SR) methods, particularly diffusion models, have made significant progress. However, they typically require slow iterative inference with 40--1000 steps and exhibit limited flexibility in continuous-scale SR settings. To address these issues, we propose FlowGS, a generative reconstruction framework for arbitrary-scale SR of RSIs. FlowGS models the high-frequency detail representations between high- and low-resolution images and learns a continuous probability flow from noise to detail priors via flow matching (FM) constrained by shortcut consistency, thereby reducing generative complexity and improving inference efficiency. Additionally, we employ 2D Gaussian splatting to construct a continuous feature field, thereby enabling flexible reconstruction at arbitrary query locations. Experimental results show that FlowGS delivers competitive perceptual quality compared with existing methods in both continuous-scale and fixed-scale SR settings, with substantially improved inference efficiency.
BD-Diff: Generative Diffusion Model for Image Deblurring on Unknown Domains with Blur-Decoupled Learning
Feb 03, 2025



Generative diffusion models trained on large-scale datasets have achieved remarkable progress in image synthesis. In favor of their ability to supplement missing details and generate aesthetically pleasing contents, recent works have applied them to image deblurring tasks via training an adapter on blurry-sharp image pairs to provide structural conditions for restoration. However, acquiring substantial amounts of realistic paired data is challenging and costly in real-world scenarios. On the other hand, relying solely on synthetic data often results in overfitting, leading to unsatisfactory performance when confronted with unseen blur patterns. To tackle this issue, we propose BD-Diff, a generative-diffusion-based model designed to enhance deblurring performance on unknown domains by decoupling structural features and blur patterns through joint training on three specially designed tasks. We employ two Q-Formers as structural representations and blur patterns extractors separately. The features extracted by them will be used for the supervised deblurring task on synthetic data and the unsupervised blur-transfer task by leveraging unpaired blurred images from the target domain simultaneously. Furthermore, we introduce a reconstruction task to make the structural features and blur patterns complementary. This blur-decoupled learning process enhances the generalization capabilities of BD-Diff when encountering unknown domain blur patterns. Experiments on real-world datasets demonstrate that BD-Diff outperforms existing state-of-the-art methods in blur removal and structural preservation in various challenging scenarios. The codes will be released in https://github.com/donahowe/BD-Diff
ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
Orca: Ocean Significant Wave Height Estimation with Spatio-temporally Aware Large Language Models
Jul 29, 2024
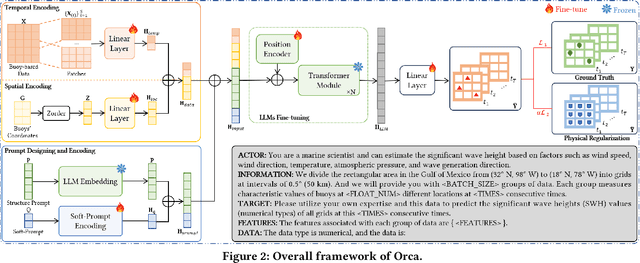


Significant wave height (SWH) is a vital metric in marine science, and accurate SWH estimation is crucial for various applications, e.g., marine energy development, fishery, early warning systems for potential risks, etc. Traditional SWH estimation methods that are based on numerical models and physical theories are hindered by computational inefficiencies. Recently, machine learning has emerged as an appealing alternative to improve accuracy and reduce computational time. However, due to limited observational technology and high costs, the scarcity of real-world data restricts the potential of machine learning models. To overcome these limitations, we propose an ocean SWH estimation framework, namely Orca. Specifically, Orca enhances the limited spatio-temporal reasoning abilities of classic LLMs with a novel spatiotemporal aware encoding module. By segmenting the limited buoy observational data temporally, encoding the buoys' locations spatially, and designing prompt templates, Orca capitalizes on the robust generalization ability of LLMs to estimate significant wave height effectively with limited data. Experimental results on the Gulf of Mexico demonstrate that Orca achieves state-of-the-art performance in SWH estimation.
AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation
Jun 03, 2024As cutting-edge Text-to-Image (T2I) generation models already excel at producing remarkable single images, an even more challenging task, i.e., multi-turn interactive image generation begins to attract the attention of related research communities. This task requires models to interact with users over multiple turns to generate a coherent sequence of images. However, since users may switch subjects frequently, current efforts struggle to maintain subject consistency while generating diverse images. To address this issue, we introduce a training-free multi-agent framework called AutoStudio. AutoStudio employs three agents based on large language models (LLMs) to handle interactions, along with a stable diffusion (SD) based agent for generating high-quality images. Specifically, AutoStudio consists of (i) a subject manager to interpret interaction dialogues and manage the context of each subject, (ii) a layout generator to generate fine-grained bounding boxes to control subject locations, (iii) a supervisor to provide suggestions for layout refinements, and (iv) a drawer to complete image generation. Furthermore, we introduce a Parallel-UNet to replace the original UNet in the drawer, which employs two parallel cross-attention modules for exploiting subject-aware features. We also introduce a subject-initialized generation method to better preserve small subjects. Our AutoStudio hereby can generate a sequence of multi-subject images interactively and consistently. Extensive experiments on the public CMIGBench benchmark and human evaluations show that AutoStudio maintains multi-subject consistency across multiple turns well, and it also raises the state-of-the-art performance by 13.65% in average Frechet Inception Distance and 2.83% in average character-character similarity.
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024



Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
Deep Learning Based Multi-Node ISAC 4D Environmental Reconstruction with Uplink- Downlink Cooperation
Apr 23, 2024
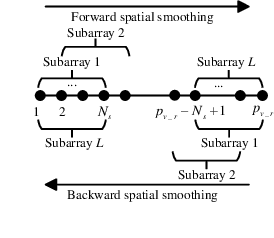
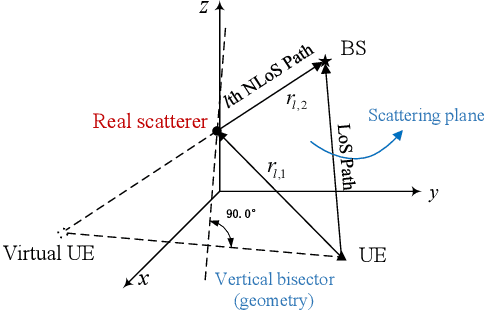
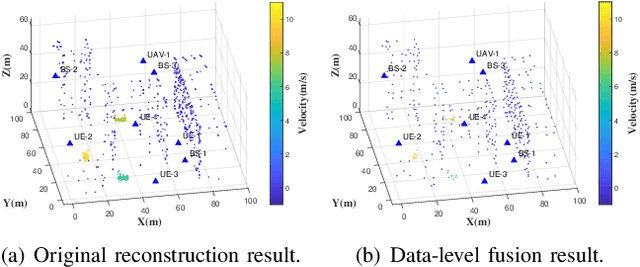
Utilizing widely distributed communication nodes to achieve environmental reconstruction is one of the significant scenarios for Integrated Sensing and Communication (ISAC) and a crucial technology for 6G. To achieve this crucial functionality, we propose a deep learning based multi-node ISAC 4D environment reconstruction method with Uplink-Downlink (UL-DL) cooperation, which employs virtual aperture technology, Constant False Alarm Rate (CFAR) detection, and Mutiple Signal Classification (MUSIC) algorithm to maximize the sensing capabilities of single sensing nodes. Simultaneously, it introduces a cooperative environmental reconstruction scheme involving multi-node cooperation and Uplink-Downlink (UL-DL) cooperation to overcome the limitations of single-node sensing caused by occlusion and limited viewpoints. Furthermore, the deep learning models Attention Gate Gridding Residual Neural Network (AGGRNN) and Multi-View Sensing Fusion Network (MVSFNet) to enhance the density of sparsely reconstructed point clouds are proposed, aiming to restore as many original environmental details as possible while preserving the spatial structure of the point cloud. Additionally, we propose a multi-level fusion strategy incorporating both data-level and feature-level fusion to fully leverage the advantages of multi-node cooperation. Experimental results demonstrate that the environmental reconstruction performance of this method significantly outperforms other comparative method, enabling high-precision environmental reconstruction using ISAC system.
Ligandformer: A Graph Neural Network for Predicting Compound Property with Robust Interpretation
Feb 24, 2022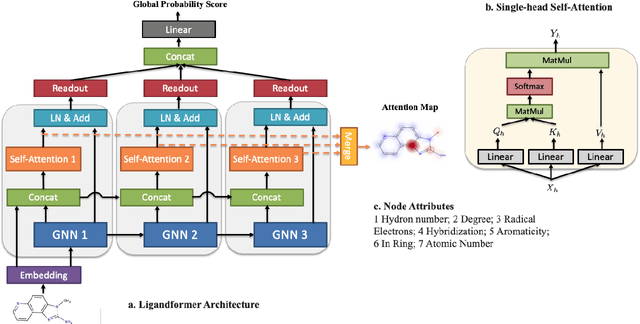

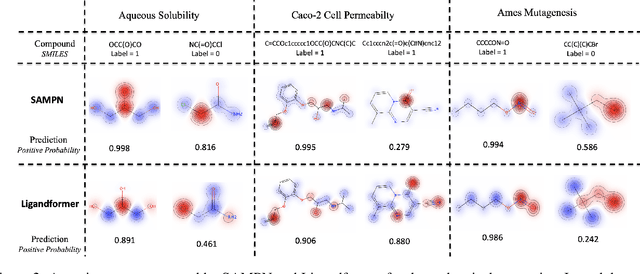
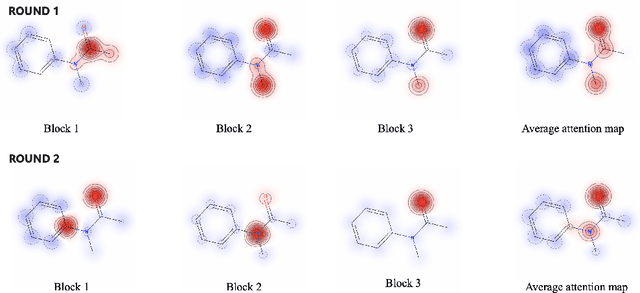
Robust and efficient interpretation of QSAR methods is quite useful to validate AI prediction rationales with subjective opinion (chemist or biologist expertise), understand sophisticated chemical or biological process mechanisms, and provide heuristic ideas for structure optimization in pharmaceutical industry. For this purpose, we construct a multi-layer self-attention based Graph Neural Network framework, namely Ligandformer, for predicting compound property with interpretation. Ligandformer integrates attention maps on compound structure from different network blocks. The integrated attention map reflects the machine's local interest on compound structure, and indicates the relationship between predicted compound property and its structure. This work mainly contributes to three aspects: 1. Ligandformer directly opens the black-box of deep learning methods, providing local prediction rationales on chemical structures. 2. Ligandformer gives robust prediction in different experimental rounds, overcoming the ubiquitous prediction instability of deep learning methods. 3. Ligandformer can be generalized to predict different chemical or biological properties with high performance. Furthermore, Ligandformer can simultaneously output specific property score and visible attention map on structure, which can support researchers to investigate chemical or biological property and optimize structure efficiently. Our framework outperforms over counterparts in terms of accuracy, robustness and generalization, and can be applied in complex system study.