 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingingBot: An Avatar-Driven System for Robotic Face Singing Performance
Jan 05, 2026Equipping robotic faces with singing capabilities is crucial for empathetic Human-Robot Interaction. However, existing robotic face driving research primarily focuses on conversations or mimicking static expressions, struggling to meet the high demands for continuous emotional expression and coherence in singing. To address this, we propose a novel avatar-driven framework for appealing robotic singing. We first leverage portrait video generation models embedded with extensive human priors to synthesize vivid singing avatars, providing reliable expression and emotion guidance. Subsequently, these facial features are transferred to the robot via semantic-oriented mapping functions that span a wide expression space. Furthermore, to quantitatively evaluate the emotional richness of robotic singing, we propose the Emotion Dynamic Range metric to measure the emotional breadth within the Valence-Arousal space, revealing that a broad emotional spectrum is crucial for appealing performances. Comprehensive experiments prove that our method achieves rich emotional expressions while maintaining lip-audio synchronization, significantly outperforming existing approaches.
MoRE: 3D Visual Geometry Reconstruction Meets Mixture-of-Experts
Oct 31, 2025Recent advances in language and vision have demonstrated that scaling up model capacity consistently improves performance across diverse tasks. In 3D visual geometry reconstruction, large-scale training has likewise proven effective for learning versatile representations. However, further scaling of 3D models is challenging due to the complexity of geometric supervision and the diversity of 3D data. To overcome these limitations, we propose MoRE, a dense 3D visual foundation model based on a Mixture-of-Experts (MoE) architecture that dynamically routes features to task-specific experts, allowing them to specialize in complementary data aspects and enhance both scalability and adaptability. Aiming to improve robustness under real-world conditions, MoRE incorporates a confidence-based depth refinement module that stabilizes and refines geometric estimation. In addition, it integrates dense semantic features with globally aligned 3D backbone representations for high-fidelity surface normal prediction. MoRE is further optimized with tailored loss functions to ensure robust learning across diverse inputs and multiple geometric tasks. Extensive experiments demonstrate that MoRE achieves state-of-the-art performance across multiple benchmarks and supports effective downstream applications without extra computation.
LaVieID: Local Autoregressive Diffusion Transformers for Identity-Preserving Video Creation
Aug 11, 2025

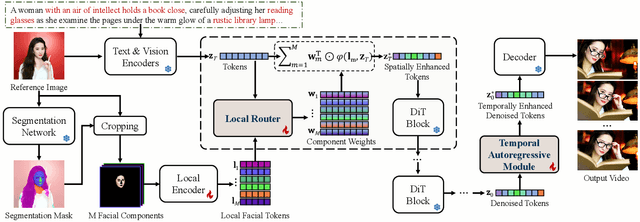

In this paper, we present LaVieID, a novel \underline{l}ocal \underline{a}utoregressive \underline{vi}d\underline{e}o diffusion framework designed to tackle the challenging \underline{id}entity-preserving text-to-video task. The key idea of LaVieID is to mitigate the loss of identity information inherent in the stochastic global generation process of diffusion transformers (DiTs) from both spatial and temporal perspectives. Specifically, unlike the global and unstructured modeling of facial latent states in existing DiTs, LaVieID introduces a local router to explicitly represent latent states by weighted combinations of fine-grained local facial structures. This alleviates undesirable feature interference and encourages DiTs to capture distinctive facial characteristics. Furthermore, a temporal autoregressive module is integrated into LaVieID to refine denoised latent tokens before video decoding. This module divides latent tokens temporally into chunks, exploiting their long-range temporal dependencies to predict biases for rectifying tokens, thereby significantly enhancing inter-frame identity consistency. Consequently, LaVieID can generate high-fidelity personalized videos and achieve state-of-the-art performance. Our code and models are available at https://github.com/ssugarwh/LaVieID.
SEA: Self-Evolution Agent with Step-wise Reward for Computer Use
Aug 06, 2025Computer use agent is an emerging area in artificial intelligence that aims to operate the computers to achieve the user's tasks, which attracts a lot of attention from both industry and academia. However, the present agents' performance is far from being used. In this paper, we propose the Self-Evolution Agent (SEA) for computer use, and to develop this agent, we propose creative methods in data generation, reinforcement learning, and model enhancement. Specifically, we first propose an automatic pipeline to generate the verifiable trajectory for training. And then, we propose efficient step-wise reinforcement learning to alleviate the significant computational requirements for long-horizon training. In the end, we propose the enhancement method to merge the grounding and planning ability into one model without any extra training. Accordingly, based on our proposed innovation of data generation, training strategy, and enhancement, we get the Selfevolution Agent (SEA) for computer use with only 7B parameters, which outperforms models with the same number of parameters and has comparable performance to larger ones. We will make the models' weight and related codes open-source in the future.
Multimodal Latent Diffusion Model for Complex Sewing Pattern Generation
Dec 19, 2024



Generating sewing patterns in garment design is receiving increasing attention due to its CG-friendly and flexible-editing nature. Previous sewing pattern generation methods have been able to produce exquisite clothing, but struggle to design complex garments with detailed control. To address these issues, we propose SewingLDM, a multi-modal generative model that generates sewing patterns controlled by text prompts, body shapes, and garment sketches. Initially, we extend the original vector of sewing patterns into a more comprehensive representation to cover more intricate details and then compress them into a compact latent space. To learn the sewing pattern distribution in the latent space, we design a two-step training strategy to inject the multi-modal conditions, \ie, body shapes, text prompts, and garment sketches, into a diffusion model, ensuring the generated garments are body-suited and detail-controlled. Comprehensive qualitative and quantitative experiments show the effectiveness of our proposed method, significantly surpassing previous approaches in terms of complex garment design and various body adaptability. Our project page: https://shengqiliu1.github.io/SewingLDM.
EACO: Enhancing Alignment in Multimodal LLMs via Critical Observation
Dec 06, 2024



Multimodal large language models (MLLMs) have achieved remarkable progress on various visual question answering and reasoning tasks leveraging instruction fine-tuning specific datasets. They can also learn from preference data annotated by human to enhance their reasoning ability and mitigate hallucinations. Most of preference data is generated from the model itself. However, existing methods require high-quality critical labels, which are costly and rely on human or proprietary models like GPT-4V. In this work, we propose Enhancing Alignment in MLLMs via Critical Observation (EACO), which aligns MLLMs by self-generated preference data using only 5k images economically. Our approach begins with collecting and refining a Scoring Evaluation Instruction-tuning dataset to train a critical evaluation model, termed the Critic. This Critic observes model responses across multiple dimensions, selecting preferred and non-preferred outputs for refined Direct Preference Optimization (DPO) tuning. To further enhance model performance, we employ an additional supervised fine-tuning stage after preference tuning. EACO reduces the overall hallucinations by 65.6% on HallusionBench and improves the reasoning ability by 21.8% on MME-Cognition. EACO achieves an 8.5% improvement over LLaVA-v1.6-Mistral-7B across multiple benchmarks. Remarkably, EACO also shows the potential critical ability in open-source MLLMs, demonstrating that EACO is a viable path to boost the competence of MLLMs.
Learning Interaction-aware 3D Gaussian Splatting for One-shot Hand Avatars
Oct 11, 2024


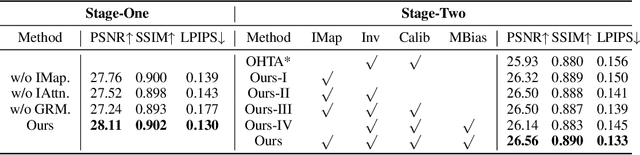
In this paper, we propose to create animatable avatars for interacting hands with 3D Gaussian Splatting (GS) and single-image inputs. Existing GS-based methods designed for single subjects often yield unsatisfactory results due to limited input views, various hand poses, and occlusions. To address these challenges, we introduce a novel two-stage interaction-aware GS framework that exploits cross-subject hand priors and refines 3D Gaussians in interacting areas. Particularly, to handle hand variations, we disentangle the 3D presentation of hands into optimization-based identity maps and learning-based latent geometric features and neural texture maps. Learning-based features are captured by trained networks to provide reliable priors for poses, shapes, and textures, while optimization-based identity maps enable efficient one-shot fitting of out-of-distribution hands. Furthermore, we devise an interaction-aware attention module and a self-adaptive Gaussian refinement module. These modules enhance image rendering quality in areas with intra- and inter-hand interactions, overcoming the limitations of existing GS-based methods. Our proposed method is validated via extensive experiments on the large-scale InterHand2.6M dataset, and it significantly improves the state-of-the-art performance in image quality. Project Page: \url{https://github.com/XuanHuang0/GuassianHand}.
Revealing Directions for Text-guided 3D Face Editing
Oct 07, 2024



3D face editing is a significant task in multimedia, aimed at the manipulation of 3D face models across various control signals. The success of 3D-aware GAN provides expressive 3D models learned from 2D single-view images only, encouraging researchers to discover semantic editing directions in its latent space. However, previous methods face challenges in balancing quality, efficiency, and generalization. To solve the problem, we explore the possibility of introducing the strength of diffusion model into 3D-aware GANs. In this paper, we present Face Clan, a fast and text-general approach for generating and manipulating 3D faces based on arbitrary attribute descriptions. To achieve disentangled editing, we propose to diffuse on the latent space under a pair of opposite prompts to estimate the mask indicating the region of interest on latent codes. Based on the mask, we then apply denoising to the masked latent codes to reveal the editing direction. Our method offers a precisely controllable manipulation method, allowing users to intuitively customize regions of interest with the text description. Experiments demonstrate the effectiveness and generalization of our Face Clan for various pre-trained GANs. It offers an intuitive and wide application for text-guided face editing that contributes to the landscape of multimedia content creation.
GarmentAligner: Text-to-Garment Generation via Retrieval-augmented Multi-level Corrections
Aug 23, 2024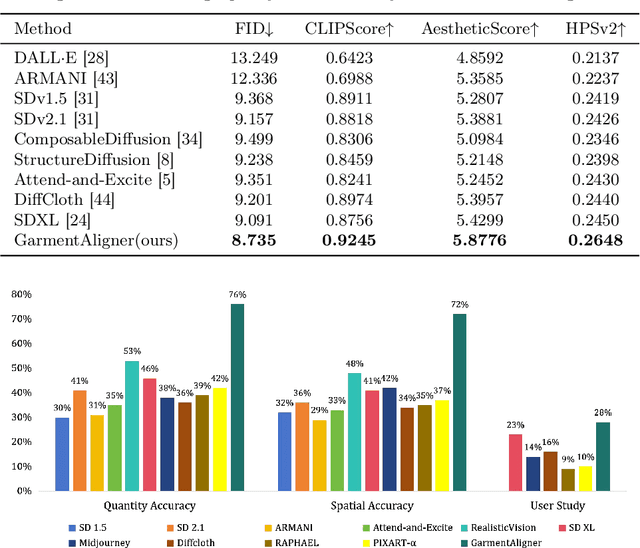



General text-to-image models bring revolutionary innovation to the fields of arts, design, and media. However, when applied to garment generation, even the state-of-the-art text-to-image models suffer from fine-grained semantic misalignment, particularly concerning the quantity, position, and interrelations of garment components. Addressing this, we propose GarmentAligner, a text-to-garment diffusion model trained with retrieval-augmented multi-level corrections. To achieve semantic alignment at the component level, we introduce an automatic component extraction pipeline to obtain spatial and quantitative information of garment components from corresponding images and captions. Subsequently, to exploit component relationships within the garment images, we construct retrieval subsets for each garment by retrieval augmentation based on component-level similarity ranking and conduct contrastive learning to enhance the model perception of components from positive and negative samples. To further enhance the alignment of components across semantic, spatial, and quantitative granularities, we propose the utilization of multi-level correction losses that leverage detailed component information. The experimental findings demonstrate that GarmentAligner achieves superior fidelity and fine-grained semantic alignment when compared to existing competitors.
AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation
Jun 03, 2024As cutting-edge Text-to-Image (T2I) generation models already excel at producing remarkable single images, an even more challenging task, i.e., multi-turn interactive image generation begins to attract the attention of related research communities. This task requires models to interact with users over multiple turns to generate a coherent sequence of images. However, since users may switch subjects frequently, current efforts struggle to maintain subject consistency while generating diverse images. To address this issue, we introduce a training-free multi-agent framework called AutoStudio. AutoStudio employs three agents based on large language models (LLMs) to handle interactions, along with a stable diffusion (SD) based agent for generating high-quality images. Specifically, AutoStudio consists of (i) a subject manager to interpret interaction dialogues and manage the context of each subject, (ii) a layout generator to generate fine-grained bounding boxes to control subject locations, (iii) a supervisor to provide suggestions for layout refinements, and (iv) a drawer to complete image generation. Furthermore, we introduce a Parallel-UNet to replace the original UNet in the drawer, which employs two parallel cross-attention modules for exploiting subject-aware features. We also introduce a subject-initialized generation method to better preserve small subjects. Our AutoStudio hereby can generate a sequence of multi-subject images interactively and consistently. Extensive experiments on the public CMIGBench benchmark and human evaluations show that AutoStudio maintains multi-subject consistency across multiple turns well, and it also raises the state-of-the-art performance by 13.65% in average Frechet Inception Distance and 2.83% in average character-character similarity.