 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVHOI: Bridge Multi-view Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model
Mar 16, 2026Human-Object Interaction (HOI) video reenactment with realistic motion remains a frontier in expressive digital human creation. Existing approaches primarily handle simple image-plane motion (e.g., in-plane translations), struggling with complex non-planar manipulations like out-of-plane reorientation. In this paper, we propose MVHOI, a two-stage HOI video reenactment framework that bridges multi-view reference conditions and video foundation models via a 3D Foundation Model (3DFM). The 3DFM first produces view-consistent object priors conditioned on implicit motion dynamics across novel viewpoints. A controllable video generation model then synthesizes high-fidelity object texture by incorporating multi-view reference images, ensuring appearance consistency via a reasonable retrieval mechanism. By enabling these two stages to mutually reinforce one another during the inference phase, our framework shows superior performance in generating long-duration HOI videos with intricate object manipulations. Extensive experiments show substantial improvements over prior approaches, especially for HOI with complex 3D object manipulations.
WildGHand: Learning Anti-Perturbation Gaussian Hand Avatars from Monocular In-the-Wild Videos
Feb 24, 2026Despite recent progress in 3D hand reconstruction from monocular videos, most existing methods rely on data captured in well-controlled environments and therefore degrade in real-world settings with severe perturbations, such as hand-object interactions, extreme poses, illumination changes, and motion blur. To tackle these issues, we introduce WildGHand, an optimization-based framework that enables self-adaptive 3D Gaussian splatting on in-the-wild videos and produces high-fidelity hand avatars. WildGHand incorporates two key components: (i) a dynamic perturbation disentanglement module that explicitly represents perturbations as time-varying biases on 3D Gaussian attributes during optimization, and (ii) a perturbation-aware optimization strategy that generates per-frame anisotropic weighted masks to guide optimization. Together, these components allow the framework to identify and suppress perturbations across both spatial and temporal dimensions. We further curate a dataset of monocular hand videos captured under diverse perturbations to benchmark in-the-wild hand avatar reconstruction. Extensive experiments on this dataset and two public datasets demonstrate that WildGHand achieves state-of-the-art performance and substantially improves over its base model across multiple metrics (e.g., up to a $15.8\%$ relative gain in PSNR and a $23.1\%$ relative reduction in LPIPS). Our implementation and dataset are available at https://github.com/XuanHuang0/WildGHand.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Mechanical Power Modeling and Energy Efficiency Maximization for Movable Antenna Systems
May 09, 2025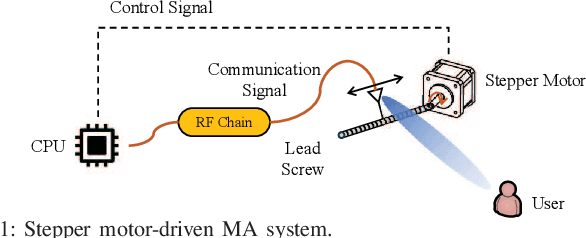

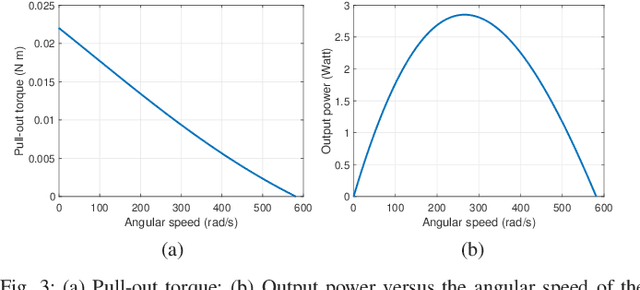

Movable antennas (MAs) have recently garnered significant attention in wireless communications due to their capability to reshape wireless channels via local antenna movement within a confined region. However, to achieve accurate antenna movement, MA drivers introduce non-negligible mechanical power consumption, rendering energy efficiency (EE) optimization more critical compared to conventional fixed-position antenna (FPA) systems. To address this problem, we develop in this paper a fundamental power consumption model for stepper motor-driven MA systems by resorting to basic electric motor theory. Based on this model, we formulate an EE maximization problem by jointly optimizing an MA's position, moving speed, and transmit power. However, this problem is difficult to solve optimally due to the intricate relationship between the mechanical power consumption and the design variables. To tackle this issue, we first uncover a hidden monotonicity of the EE performance with respect to the MA's moving speed. Then, we apply the Dinkelbach algorithm to obtain the optimal transmit power in a semi-closed form for any given MA position, followed by an enumeration to determine the optimal MA position. Numerical results demonstrate that despite the additional mechanical power consumption, the MA system can outperform the conventional FPA system in terms of EE.
CLDA-YOLO: Visual Contrastive Learning Based Domain Adaptive YOLO Detector
Dec 16, 2024



Unsupervised domain adaptive (UDA) algorithms can markedly enhance the performance of object detectors under conditions of domain shifts, thereby reducing the necessity for extensive labeling and retraining. Current domain adaptive object detection algorithms primarily cater to two-stage detectors, which tend to offer minimal improvements when directly applied to single-stage detectors such as YOLO. Intending to benefit the YOLO detector from UDA, we build a comprehensive domain adaptive architecture using a teacher-student cooperative system for the YOLO detector. In this process, we propose uncertainty learning to cope with pseudo-labeling generated by the teacher model with extreme uncertainty and leverage dynamic data augmentation to asymptotically adapt the teacher-student system to the environment. To address the inability of single-stage object detectors to align at multiple stages, we utilize a unified visual contrastive learning paradigm that aligns instance at backbone and head respectively, which steadily improves the robustness of the detectors in cross-domain tasks. In summary, we present an unsupervised domain adaptive YOLO detector based on visual contrastive learning (CLDA-YOLO), which achieves highly competitive results across multiple domain adaptive datasets without any reduction in inference speed.
Using Generative AI and Multi-Agents to Provide Automatic Feedback
Nov 11, 2024

This study investigates the use of generative AI and multi-agent systems to provide automatic feedback in educational contexts, particularly for student constructed responses in science assessments. The research addresses a key gap in the field by exploring how multi-agent systems, called AutoFeedback, can improve the quality of GenAI-generated feedback, overcoming known issues such as over-praise and over-inference that are common in single-agent large language models (LLMs). The study developed a multi-agent system consisting of two AI agents: one for generating feedback and another for validating and refining it. The system was tested on a dataset of 240 student responses, and its performance was compared to that of a single-agent LLM. Results showed that AutoFeedback significantly reduced the occurrence of over-praise and over-inference errors, providing more accurate and pedagogically sound feedback. The findings suggest that multi-agent systems can offer a more reliable solution for generating automated feedback in educational settings, highlighting their potential for scalable and personalized learning support. These results have important implications for educators and researchers seeking to leverage AI in formative assessments, offering a pathway to more effective feedback mechanisms that enhance student learning outcomes.
Learning Interaction-aware 3D Gaussian Splatting for One-shot Hand Avatars
Oct 11, 2024


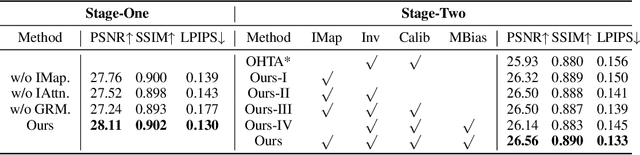
In this paper, we propose to create animatable avatars for interacting hands with 3D Gaussian Splatting (GS) and single-image inputs. Existing GS-based methods designed for single subjects often yield unsatisfactory results due to limited input views, various hand poses, and occlusions. To address these challenges, we introduce a novel two-stage interaction-aware GS framework that exploits cross-subject hand priors and refines 3D Gaussians in interacting areas. Particularly, to handle hand variations, we disentangle the 3D presentation of hands into optimization-based identity maps and learning-based latent geometric features and neural texture maps. Learning-based features are captured by trained networks to provide reliable priors for poses, shapes, and textures, while optimization-based identity maps enable efficient one-shot fitting of out-of-distribution hands. Furthermore, we devise an interaction-aware attention module and a self-adaptive Gaussian refinement module. These modules enhance image rendering quality in areas with intra- and inter-hand interactions, overcoming the limitations of existing GS-based methods. Our proposed method is validated via extensive experiments on the large-scale InterHand2.6M dataset, and it significantly improves the state-of-the-art performance in image quality. Project Page: \url{https://github.com/XuanHuang0/GuassianHand}.
DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation
Jun 06, 2024



Atrous convolutions are employed as a method to increase the receptive field in semantic segmentation tasks. However, in previous works of semantic segmentation, it was rarely employed in the shallow layers of the model. We revisit the design of atrous convolutions in modern convolutional neural networks (CNNs), and demonstrate that the concept of using large kernels to apply atrous convolutions could be a more powerful paradigm. We propose three guidelines to apply atrous convolutions more efficiently. Following these guidelines, we propose DSNet, a Dual-Branch CNN architecture, which incorporates atrous convolutions in the shallow layers of the model architecture, as well as pretraining the nearly entire encoder on ImageNet to achieve better performance. To demonstrate the effectiveness of our approach, our models achieve a new state-of-the-art trade-off between accuracy and speed on ADE20K, Cityscapes and BDD datasets. Specifically, DSNet achieves 40.0% mIOU with inference speed of 179.2 FPS on ADE20K, and 80.4% mIOU with speed of 81.9 FPS on Cityscapes. Source code and models are available at Github: https://github.com/takaniwa/DSNet.
Soar: Design and Deployment of A Smart Roadside Infrastructure System for Autonomous Driving
Apr 21, 2024
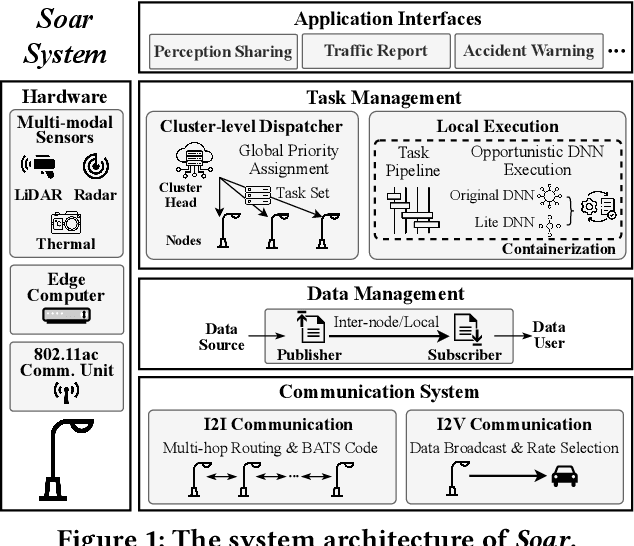
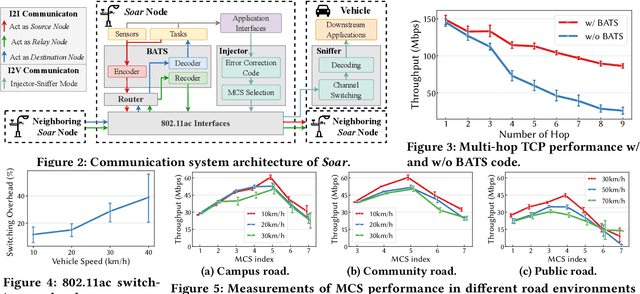
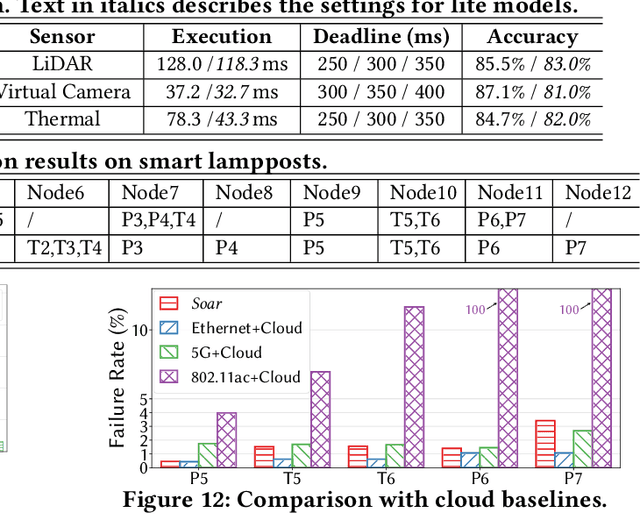
Recently,smart roadside infrastructure (SRI) has demonstrated the potential of achieving fully autonomous driving systems. To explore the potential of infrastructure-assisted autonomous driving, this paper presents the design and deployment of Soar, the first end-to-end SRI system specifically designed to support autonomous driving systems. Soar consists of both software and hardware components carefully designed to overcome various system and physical challenges. Soar can leverage the existing operational infrastructure like street lampposts for a lower barrier of adoption. Soar adopts a new communication architecture that comprises a bi-directional multi-hop I2I network and a downlink I2V broadcast service, which are designed based on off-the-shelf 802.11ac interfaces in an integrated manner. Soar also features a hierarchical DL task management framework to achieve desirable load balancing among nodes and enable them to collaborate efficiently to run multiple data-intensive autonomous driving applications. We deployed a total of 18 Soar nodes on existing lampposts on campus, which have been operational for over two years. Our real-world evaluation shows that Soar can support a diverse set of autonomous driving applications and achieve desirable real-time performance and high communication reliability. Our findings and experiences in this work offer key insights into the development and deployment of next-generation smart roadside infrastructure and autonomous driving systems.
3D Visibility-aware Generalizable Neural Radiance Fields for Interacting Hands
Jan 02, 2024



Neural radiance fields (NeRFs) are promising 3D representations for scenes, objects, and humans. However, most existing methods require multi-view inputs and per-scene training, which limits their real-life applications. Moreover, current methods focus on single-subject cases, leaving scenes of interacting hands that involve severe inter-hand occlusions and challenging view variations remain unsolved. To tackle these issues, this paper proposes a generalizable visibility-aware NeRF (VA-NeRF) framework for interacting hands. Specifically, given an image of interacting hands as input, our VA-NeRF first obtains a mesh-based representation of hands and extracts their corresponding geometric and textural features. Subsequently, a feature fusion module that exploits the visibility of query points and mesh vertices is introduced to adaptively merge features of both hands, enabling the recovery of features in unseen areas. Additionally, our VA-NeRF is optimized together with a novel discriminator within an adversarial learning paradigm. In contrast to conventional discriminators that predict a single real/fake label for the synthesized image, the proposed discriminator generates a pixel-wise visibility map, providing fine-grained supervision for unseen areas and encouraging the VA-NeRF to improve the visual quality of synthesized images. Experiments on the Interhand2.6M dataset demonstrate that our proposed VA-NeRF outperforms conventional NeRFs significantly. Project Page: \url{https://github.com/XuanHuang0/VANeRF}.