 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveGEN: Generalized and Robust 3D Detection in Driving via Controllable Text-to-Image Diffusion Generation
Mar 14, 2025



In autonomous driving, vision-centric 3D detection aims to identify 3D objects from images. However, high data collection costs and diverse real-world scenarios limit the scale of training data. Once distribution shifts occur between training and test data, existing methods often suffer from performance degradation, known as Out-of-Distribution (OOD) problems. To address this, controllable Text-to-Image (T2I) diffusion offers a potential solution for training data enhancement, which is required to generate diverse OOD scenarios with precise 3D object geometry. Nevertheless, existing controllable T2I approaches are restricted by the limited scale of training data or struggle to preserve all annotated 3D objects. In this paper, we present DriveGEN, a method designed to improve the robustness of 3D detectors in Driving via Training-Free Controllable Text-to-Image Diffusion Generation. Without extra diffusion model training, DriveGEN consistently preserves objects with precise 3D geometry across diverse OOD generations, consisting of 2 stages: 1) Self-Prototype Extraction: We empirically find that self-attention features are semantic-aware but require accurate region selection for 3D objects. Thus, we extract precise object features via layouts to capture 3D object geometry, termed self-prototypes. 2) Prototype-Guided Diffusion: To preserve objects across various OOD scenarios, we perform semantic-aware feature alignment and shallow feature alignment during denoising. Extensive experiments demonstrate the effectiveness of DriveGEN in improving 3D detection. The code is available at https://github.com/Hongbin98/DriveGEN.
PiSA: A Self-Augmented Data Engine and Training Strategy for 3D Understanding with Large Models
Mar 13, 2025



3D Multimodal Large Language Models (MLLMs) have recently made substantial advancements. However, their potential remains untapped, primarily due to the limited quantity and suboptimal quality of 3D datasets. Current approaches attempt to transfer knowledge from 2D MLLMs to expand 3D instruction data, but still face modality and domain gaps. To this end, we introduce PiSA-Engine (Point-Self-Augmented-Engine), a new framework for generating instruction point-language datasets enriched with 3D spatial semantics. We observe that existing 3D MLLMs offer a comprehensive understanding of point clouds for annotation, while 2D MLLMs excel at cross-validation by providing complementary information. By integrating holistic 2D and 3D insights from off-the-shelf MLLMs, PiSA-Engine enables a continuous cycle of high-quality data generation. We select PointLLM as the baseline and adopt this co-evolution training framework to develop an enhanced 3D MLLM, termed PointLLM-PiSA. Additionally, we identify limitations in previous 3D benchmarks, which often feature coarse language captions and insufficient category diversity, resulting in inaccurate evaluations. To address this gap, we further introduce PiSA-Bench, a comprehensive 3D benchmark covering six key aspects with detailed and diverse labels. Experimental results demonstrate PointLLM-PiSA's state-of-the-art performance in zero-shot 3D object captioning and generative classification on our PiSA-Bench, achieving significant improvements of 46.45% (+8.33%) and 63.75% (+16.25%), respectively. We will release the code, datasets, and benchmark.
EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion
Nov 23, 2024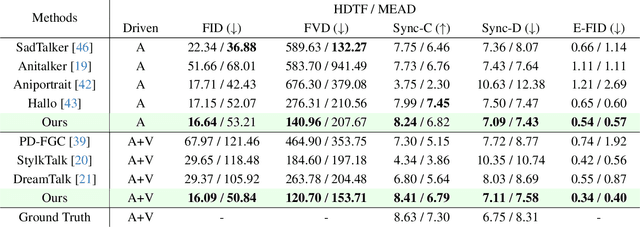
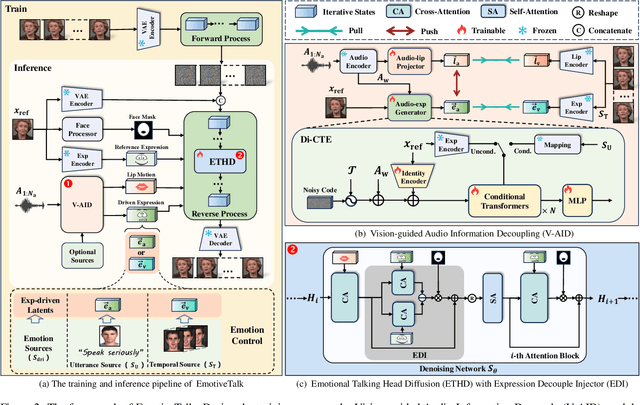
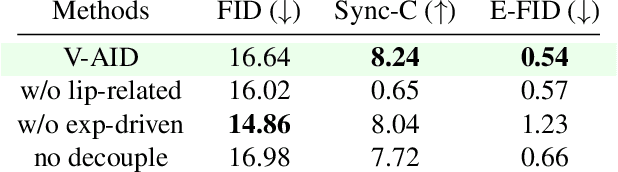

Diffusion models have revolutionized the field of talking head generation, yet still face challenges in expressiveness, controllability, and stability in long-time generation. In this research, we propose an EmotiveTalk framework to address these issues. Firstly, to realize better control over the generation of lip movement and facial expression, a Vision-guided Audio Information Decoupling (V-AID) approach is designed to generate audio-based decoupled representations aligned with lip movements and expression. Specifically, to achieve alignment between audio and facial expression representation spaces, we present a Diffusion-based Co-speech Temporal Expansion (Di-CTE) module within V-AID to generate expression-related representations under multi-source emotion condition constraints. Then we propose a well-designed Emotional Talking Head Diffusion (ETHD) backbone to efficiently generate highly expressive talking head videos, which contains an Expression Decoupling Injection (EDI) module to automatically decouple the expressions from reference portraits while integrating the target expression information, achieving more expressive generation performance. Experimental results show that EmotiveTalk can generate expressive talking head videos, ensuring the promised controllability of emotions and stability during long-time generation, yielding state-of-the-art performance compared to existing methods.
DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation
Jun 06, 2024



Atrous convolutions are employed as a method to increase the receptive field in semantic segmentation tasks. However, in previous works of semantic segmentation, it was rarely employed in the shallow layers of the model. We revisit the design of atrous convolutions in modern convolutional neural networks (CNNs), and demonstrate that the concept of using large kernels to apply atrous convolutions could be a more powerful paradigm. We propose three guidelines to apply atrous convolutions more efficiently. Following these guidelines, we propose DSNet, a Dual-Branch CNN architecture, which incorporates atrous convolutions in the shallow layers of the model architecture, as well as pretraining the nearly entire encoder on ImageNet to achieve better performance. To demonstrate the effectiveness of our approach, our models achieve a new state-of-the-art trade-off between accuracy and speed on ADE20K, Cityscapes and BDD datasets. Specifically, DSNet achieves 40.0% mIOU with inference speed of 179.2 FPS on ADE20K, and 80.4% mIOU with speed of 81.9 FPS on Cityscapes. Source code and models are available at Github: https://github.com/takaniwa/DSNet.
A Variance-Preserving Interpolation Approach for Diffusion Models with Applications to Single Channel Speech Enhancement and Recognition
May 27, 2024



In this paper, we propose a variance-preserving interpolation framework to improve diffusion models for single-channel speech enhancement (SE) and automatic speech recognition (ASR). This new variance-preserving interpolation diffusion model (VPIDM) approach requires only 25 iterative steps and obviates the need for a corrector, an essential element in the existing variance-exploding interpolation diffusion model (VEIDM). Two notable distinctions between VPIDM and VEIDM are the scaling function of the mean of state variables and the constraint imposed on the variance relative to the mean's scale. We conduct a systematic exploration of the theoretical mechanism underlying VPIDM and develop insights regarding VPIDM's applications in SE and ASR using VPIDM as a frontend. Our proposed approach, evaluated on two distinct data sets, demonstrates VPIDM's superior performances over conventional discriminative SE algorithms. Furthermore, we assess the performance of the proposed model under varying signal-to-noise ratio (SNR) levels. The investigation reveals VPIDM's improved robustness in target noise elimination when compared to VEIDM. Furthermore, utilizing the mid-outputs of both VPIDM and VEIDM results in enhanced ASR accuracies, thereby highlighting the practical efficacy of our proposed approach.
Quality-aware Masked Diffusion Transformer for Enhanced Music Generation
May 24, 2024In recent years, diffusion-based text-to-music (TTM) generation has gained prominence, offering a novel approach to synthesizing musical content from textual descriptions. Achieving high accuracy and diversity in this generation process requires extensive, high-quality data, which often constitutes only a fraction of available datasets. Within open-source datasets, the prevalence of issues like mislabeling, weak labeling, unlabeled data, and low-quality music waveform significantly hampers the development of music generation models. To overcome these challenges, we introduce a novel quality-aware masked diffusion transformer (QA-MDT) approach that enables generative models to discern the quality of input music waveform during training. Building on the unique properties of musical signals, we have adapted and implemented a MDT model for TTM task, while further unveiling its distinct capacity for quality control. Moreover, we address the issue of low-quality captions with a caption refinement data processing approach. Our demo page is shown in https://qa-mdt.github.io/. Code on https://github.com/ivcylc/qa-mdt
Continuous Modeling of the Denoising Process for Speech Enhancement Based on Deep Learning
Sep 17, 2023

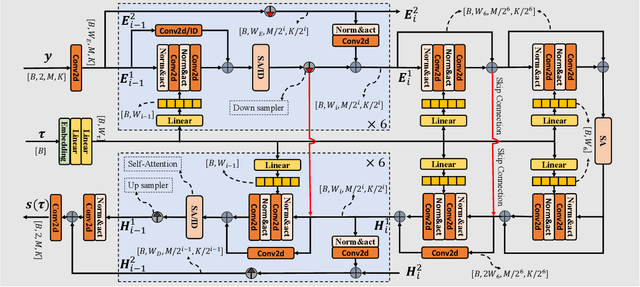

In this paper, we explore a continuous modeling approach for deep-learning-based speech enhancement, focusing on the denoising process. We use a state variable to indicate the denoising process. The starting state is noisy speech and the ending state is clean speech. The noise component in the state variable decreases with the change of the state index until the noise component is 0. During training, a UNet-like neural network learns to estimate every state variable sampled from the continuous denoising process. In testing, we introduce a controlling factor as an embedding, ranging from zero to one, to the neural network, allowing us to control the level of noise reduction. This approach enables controllable speech enhancement and is adaptable to various application scenarios. Experimental results indicate that preserving a small amount of noise in the clean target benefits speech enhancement, as evidenced by improvements in both objective speech measures and automatic speech recognition performance.
Variance-Preserving-Based Interpolation Diffusion Models for Speech Enhancement
Jun 14, 2023

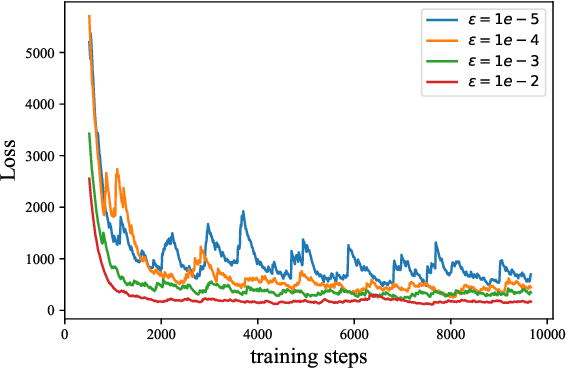

The goal of this study is to implement diffusion models for speech enhancement (SE). The first step is to emphasize the theoretical foundation of variance-preserving (VP)-based interpolation diffusion under continuous conditions. Subsequently, we present a more concise framework that encapsulates both the VP- and variance-exploding (VE)-based interpolation diffusion methods. We demonstrate that these two methods are special cases of the proposed framework. Additionally, we provide a practical example of VP-based interpolation diffusion for the SE task. To improve performance and ease model training, we analyze the common difficulties encountered in diffusion models and suggest amenable hyper-parameters. Finally, we evaluate our model against several methods using a public benchmark to showcase the effectiveness of our approach