 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Cache: Cross-Chunk Block Caching for Few-Step Autoregressive World Models Inference
Apr 22, 2026Real-time world simulation is becoming a key infrastructure for scalable evaluation and online reinforcement learning of autonomous driving systems. Recent driving world models built on autoregressive video diffusion achieve high-fidelity, controllable multi-camera generation, but their inference cost remains a bottleneck for interactive deployment. However, existing diffusion caching methods are designed for offline video generation with multiple denoising steps, and do not transfer to this scenario. Few-step distilled models have no inter-step redundancy left for these methods to reuse, and sequence-level parallelization techniques require future conditioning that closed-loop interactive generation does not provide. We present X-Cache, a training-free acceleration method that caches along a different axis: across consecutive generation chunks rather than across denoising steps. X-Cache maintains per-block residual caches that persist across chunks, and applies a dual-metric gating mechanism over a structure- and action-aware block-input fingerprint to independently decide whether each block should recompute or reuse its cached residual. To prevent approximation errors from permanently contaminating the autoregressive KV cache, X-Cache identifies KV update chunks (the forward passes that write clean keys and values into the persistent cache) and unconditionally forces full computation on these chunks, cutting off error propagation. We implement X-Cache on X-world, a production multi-camera action-conditioned driving world model built on multi-block causal DiT with few-step denoising and rolling KV cache. X-Cache achieves 71% block skip rate with 2.6x wall-clock speedup while maintaining minimum degradation.
X-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving
Mar 20, 2026Scalable and reliable evaluation is increasingly critical in the end-to-end era of autonomous driving, where vision--language--action (VLA) policies directly map raw sensor streams to driving actions. Yet, current evaluation pipelines still rely heavily on real-world road testing, which is costly, biased toward limited scenario coverage, and difficult to reproduce. These challenges motivate a real-world simulator that can generate realistic future observations under proposed actions, while remaining controllable and stable over long horizons. We present X-World, an action-conditioned multi-camera generative world model that simulates future observations directly in video space. Given synchronized multi-view camera history and a future action sequence, X-World generates future multi-camera video streams that follow the commanded actions. To ensure reproducible and editable scene rollouts, X-World further supports optional controls over dynamic traffic agents and static road elements, and retains a text-prompt interface for appearance-level control (e.g., weather and time of day). Beyond world simulation, X-World also enables video style transfer by conditioning on appearance prompts while preserving the underlying action and scene dynamics. At the core of X-World is a multi-view latent video generator designed to explicitly encourage cross-view geometric consistency and temporal coherence under diverse control signals. Experiments show that X-World achieves high-quality multi-view video generation with (i) strong view consistency across cameras, (ii) stable temporal dynamics over long rollouts, and (iii) high controllability with strict action following and faithful adherence to optional scene controls. These properties make X-World a practical foundation for scalable and reproducible evaluation.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025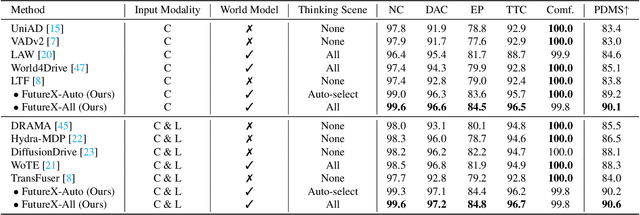
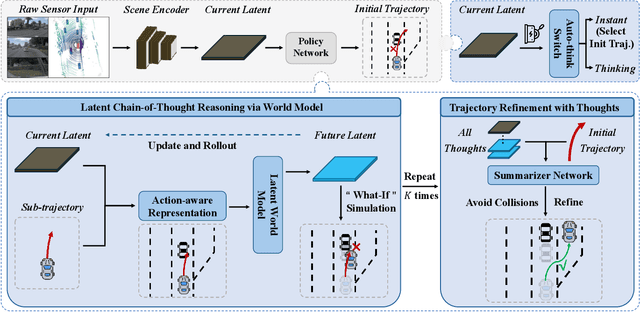

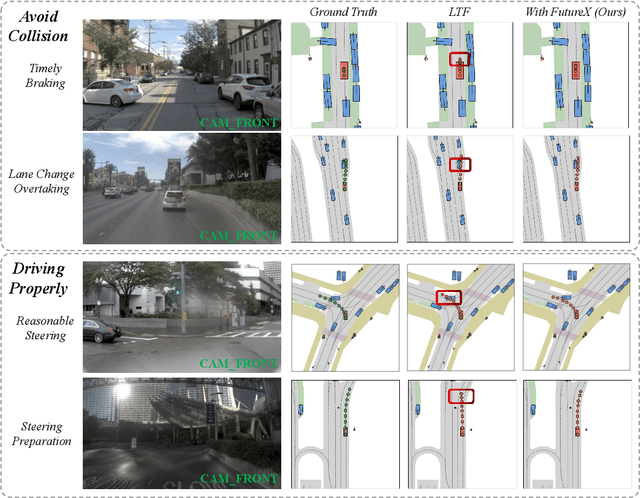
In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
PiSA: A Self-Augmented Data Engine and Training Strategy for 3D Understanding with Large Models
Mar 13, 2025



3D Multimodal Large Language Models (MLLMs) have recently made substantial advancements. However, their potential remains untapped, primarily due to the limited quantity and suboptimal quality of 3D datasets. Current approaches attempt to transfer knowledge from 2D MLLMs to expand 3D instruction data, but still face modality and domain gaps. To this end, we introduce PiSA-Engine (Point-Self-Augmented-Engine), a new framework for generating instruction point-language datasets enriched with 3D spatial semantics. We observe that existing 3D MLLMs offer a comprehensive understanding of point clouds for annotation, while 2D MLLMs excel at cross-validation by providing complementary information. By integrating holistic 2D and 3D insights from off-the-shelf MLLMs, PiSA-Engine enables a continuous cycle of high-quality data generation. We select PointLLM as the baseline and adopt this co-evolution training framework to develop an enhanced 3D MLLM, termed PointLLM-PiSA. Additionally, we identify limitations in previous 3D benchmarks, which often feature coarse language captions and insufficient category diversity, resulting in inaccurate evaluations. To address this gap, we further introduce PiSA-Bench, a comprehensive 3D benchmark covering six key aspects with detailed and diverse labels. Experimental results demonstrate PointLLM-PiSA's state-of-the-art performance in zero-shot 3D object captioning and generative classification on our PiSA-Bench, achieving significant improvements of 46.45% (+8.33%) and 63.75% (+16.25%), respectively. We will release the code, datasets, and benchmark.
Towards Flexible 3D Perception: Object-Centric Occupancy Completion Augments 3D Object Detection
Dec 06, 2024



While 3D object bounding box (bbox) representation has been widely used in autonomous driving perception, it lacks the ability to capture the precise details of an object's intrinsic geometry. Recently, occupancy has emerged as a promising alternative for 3D scene perception. However, constructing a high-resolution occupancy map remains infeasible for large scenes due to computational constraints. Recognizing that foreground objects only occupy a small portion of the scene, we introduce object-centric occupancy as a supplement to object bboxes. This representation not only provides intricate details for detected objects but also enables higher voxel resolution in practical applications. We advance the development of object-centric occupancy perception from both data and algorithm perspectives. On the data side, we construct the first object-centric occupancy dataset from scratch using an automated pipeline. From the algorithmic standpoint, we introduce a novel object-centric occupancy completion network equipped with an implicit shape decoder that manages dynamic-size occupancy generation. This network accurately predicts the complete object-centric occupancy volume for inaccurate object proposals by leveraging temporal information from long sequences. Our method demonstrates robust performance in completing object shapes under noisy detection and tracking conditions. Additionally, we show that our occupancy features significantly enhance the detection results of state-of-the-art 3D object detectors, especially for incomplete or distant objects in the Waymo Open Dataset.
GSmoothFace: Generalized Smooth Talking Face Generation via Fine Grained 3D Face Guidance
Dec 12, 2023



Although existing speech-driven talking face generation methods achieve significant progress, they are far from real-world application due to the avatar-specific training demand and unstable lip movements. To address the above issues, we propose the GSmoothFace, a novel two-stage generalized talking face generation model guided by a fine-grained 3d face model, which can synthesize smooth lip dynamics while preserving the speaker's identity. Our proposed GSmoothFace model mainly consists of the Audio to Expression Prediction (A2EP) module and the Target Adaptive Face Translation (TAFT) module. Specifically, we first develop the A2EP module to predict expression parameters synchronized with the driven speech. It uses a transformer to capture the long-term audio context and learns the parameters from the fine-grained 3D facial vertices, resulting in accurate and smooth lip-synchronization performance. Afterward, the well-designed TAFT module, empowered by Morphology Augmented Face Blending (MAFB), takes the predicted expression parameters and target video as inputs to modify the facial region of the target video without distorting the background content. The TAFT effectively exploits the identity appearance and background context in the target video, which makes it possible to generalize to different speakers without retraining. Both quantitative and qualitative experiments confirm the superiority of our method in terms of realism, lip synchronization, and visual quality. See the project page for code, data, and request pre-trained models: https://zhanghm1995.github.io/GSmoothFace.
X4D-SceneFormer: Enhanced Scene Understanding on 4D Point Cloud Videos through Cross-modal Knowledge Transfer
Dec 12, 2023The field of 4D point cloud understanding is rapidly developing with the goal of analyzing dynamic 3D point cloud sequences. However, it remains a challenging task due to the sparsity and lack of texture in point clouds. Moreover, the irregularity of point cloud poses a difficulty in aligning temporal information within video sequences. To address these issues, we propose a novel cross-modal knowledge transfer framework, called X4D-SceneFormer. This framework enhances 4D-Scene understanding by transferring texture priors from RGB sequences using a Transformer architecture with temporal relationship mining. Specifically, the framework is designed with a dual-branch architecture, consisting of an 4D point cloud transformer and a Gradient-aware Image Transformer (GIT). During training, we employ multiple knowledge transfer techniques, including temporal consistency losses and masked self-attention, to strengthen the knowledge transfer between modalities. This leads to enhanced performance during inference using single-modal 4D point cloud inputs. Extensive experiments demonstrate the superior performance of our framework on various 4D point cloud video understanding tasks, including action recognition, action segmentation and semantic segmentation. The results achieve 1st places, i.e., 85.3% (+7.9%) accuracy and 47.3% (+5.0%) mIoU for 4D action segmentation and semantic segmentation, on the HOI4D challenge\footnote{\url{http://www.hoi4d.top/}.}, outperforming previous state-of-the-art by a large margin. We release the code at https://github.com/jinglinglingling/X4D
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 20, 2023



3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo, realistic OpenLane and ONCE-3DLanes by large margins (e.g., 11.4 gain in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR .
An Effective Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds
Mar 21, 2023



3D single object tracking in LiDAR point clouds (LiDAR SOT) plays a crucial role in autonomous driving. Current approaches all follow the Siamese paradigm based on appearance matching. However, LiDAR point clouds are usually textureless and incomplete, which hinders effective appearance matching. Besides, previous methods greatly overlook the critical motion clues among targets. In this work, beyond 3D Siamese tracking, we introduce a motion-centric paradigm to handle LiDAR SOT from a new perspective. Following this paradigm, we propose a matching-free two-stage tracker M^2-Track. At the 1st-stage, M^2-Track localizes the target within successive frames via motion transformation. Then it refines the target box through motion-assisted shape completion at the 2nd-stage. Due to the motion-centric nature, our method shows its impressive generalizability with limited training labels and provides good differentiability for end-to-end cycle training. This inspires us to explore semi-supervised LiDAR SOT by incorporating a pseudo-label-based motion augmentation and a self-supervised loss term. Under the fully-supervised setting, extensive experiments confirm that M^2-Track significantly outperforms previous state-of-the-arts on three large-scale datasets while running at 57FPS (~8%, ~17% and ~22% precision gains on KITTI, NuScenes, and Waymo Open Dataset respectively). While under the semi-supervised setting, our method performs on par with or even surpasses its fully-supervised counterpart using fewer than half labels from KITTI. Further analysis verifies each component's effectiveness and shows the motion-centric paradigm's promising potential for auto-labeling and unsupervised domain adaptation.
Benchmarking the Robustness of LiDAR Semantic Segmentation Models
Jan 03, 2023



When using LiDAR semantic segmentation models for safety-critical applications such as autonomous driving, it is essential to understand and improve their robustness with respect to a large range of LiDAR corruptions. In this paper, we aim to comprehensively analyze the robustness of LiDAR semantic segmentation models under various corruptions. To rigorously evaluate the robustness and generalizability of current approaches, we propose a new benchmark called SemanticKITTI-C, which features 16 out-of-domain LiDAR corruptions in three groups, namely adverse weather, measurement noise and cross-device discrepancy. Then, we systematically investigate 11 LiDAR semantic segmentation models, especially spanning different input representations (e.g., point clouds, voxels, projected images, and etc.), network architectures and training schemes. Through this study, we obtain two insights: 1) We find out that the input representation plays a crucial role in robustness. Specifically, under specific corruptions, different representations perform variously. 2) Although state-of-the-art methods on LiDAR semantic segmentation achieve promising results on clean data, they are less robust when dealing with noisy data. Finally, based on the above observations, we design a robust LiDAR segmentation model (RLSeg) which greatly boosts the robustness with simple but effective modifications. It is promising that our benchmark, comprehensive analysis, and observations can boost future research in robust LiDAR semantic segmentation for safety-critical applications.