 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIGC In China: Current Developments And Future Outlook
Aug 21, 2023The increasing attention given to AI Generated Content (AIGC) has brought a profound impact on various aspects of daily life, industrial manufacturing, and the academic sector. Recognizing the global trends and competitiveness in AIGC development, this study aims to analyze China's current status in the field. The investigation begins with an overview of the foundational technologies and current applications of AIGC. Subsequently, the study delves into the market status, policy landscape, and development trajectory of AIGC in China, utilizing keyword searches to identify relevant scholarly papers. Furthermore, the paper provides a comprehensive examination of AIGC products and their corresponding ecosystem, emphasizing the ecological construction of AIGC. Finally, this paper discusses the challenges and risks faced by the AIGC industry while presenting a forward-looking perspective on the industry's future based on competitive insights in AIGC.
Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights
May 24, 2023Adapters, a plug-in neural network module with some tunable parameters, have emerged as a parameter-efficient transfer learning technique for adapting pre-trained models to downstream tasks, especially for natural language processing (NLP) and computer vision (CV) fields. Meanwhile, learning recommendation models directly from raw item modality features -- e.g., texts of NLP and images of CV -- can enable effective and transferable recommender systems (called TransRec). In view of this, a natural question arises: can adapter-based learning techniques achieve parameter-efficient TransRec with good performance? To this end, we perform empirical studies to address several key sub-questions. First, we ask whether the adapter-based TransRec performs comparably to TransRec based on standard full-parameter fine-tuning? does it hold for recommendation with different item modalities, e.g., textual RS and visual RS. If yes, we benchmark these existing adapters, which have been shown to be effective in NLP and CV tasks, in the item recommendation settings. Third, we carefully study several key factors for the adapter-based TransRec in terms of where and how to insert these adapters? Finally, we look at the effects of adapter-based TransRec by either scaling up its source training data or scaling down its target training data. Our paper provides key insights and practical guidance on unified & transferable recommendation -- a less studied recommendation scenario. We promise to release all code & datasets for future research.
High-dimensional Clustering onto Hamiltonian Cycle
Apr 27, 2023



Clustering aims to group unlabelled samples based on their similarities. It has become a significant tool for the analysis of high-dimensional data. However, most of the clustering methods merely generate pseudo labels and thus are unable to simultaneously present the similarities between different clusters and outliers. This paper proposes a new framework called High-dimensional Clustering onto Hamiltonian Cycle (HCHC) to solve the above problems. First, HCHC combines global structure with local structure in one objective function for deep clustering, improving the labels as relative probabilities, to mine the similarities between different clusters while keeping the local structure in each cluster. Then, the anchors of different clusters are sorted on the optimal Hamiltonian cycle generated by the cluster similarities and mapped on the circumference of a circle. Finally, a sample with a higher probability of a cluster will be mapped closer to the corresponding anchor. In this way, our framework allows us to appreciate three aspects visually and simultaneously - clusters (formed by samples with high probabilities), cluster similarities (represented as circular distances), and outliers (recognized as dots far away from all clusters). The experiments illustrate the superiority of HCHC.
An Effective Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds
Mar 21, 2023



3D single object tracking in LiDAR point clouds (LiDAR SOT) plays a crucial role in autonomous driving. Current approaches all follow the Siamese paradigm based on appearance matching. However, LiDAR point clouds are usually textureless and incomplete, which hinders effective appearance matching. Besides, previous methods greatly overlook the critical motion clues among targets. In this work, beyond 3D Siamese tracking, we introduce a motion-centric paradigm to handle LiDAR SOT from a new perspective. Following this paradigm, we propose a matching-free two-stage tracker M^2-Track. At the 1st-stage, M^2-Track localizes the target within successive frames via motion transformation. Then it refines the target box through motion-assisted shape completion at the 2nd-stage. Due to the motion-centric nature, our method shows its impressive generalizability with limited training labels and provides good differentiability for end-to-end cycle training. This inspires us to explore semi-supervised LiDAR SOT by incorporating a pseudo-label-based motion augmentation and a self-supervised loss term. Under the fully-supervised setting, extensive experiments confirm that M^2-Track significantly outperforms previous state-of-the-arts on three large-scale datasets while running at 57FPS (~8%, ~17% and ~22% precision gains on KITTI, NuScenes, and Waymo Open Dataset respectively). While under the semi-supervised setting, our method performs on par with or even surpasses its fully-supervised counterpart using fewer than half labels from KITTI. Further analysis verifies each component's effectiveness and shows the motion-centric paradigm's promising potential for auto-labeling and unsupervised domain adaptation.
EVNet: An Explainable Deep Network for Dimension Reduction
Nov 21, 2022



Dimension reduction (DR) is commonly utilized to capture the intrinsic structure and transform high-dimensional data into low-dimensional space while retaining meaningful properties of the original data. It is used in various applications, such as image recognition, single-cell sequencing analysis, and biomarker discovery. However, contemporary parametric-free and parametric DR techniques suffer from several significant shortcomings, such as the inability to preserve global and local features and the pool generalization performance. On the other hand, regarding explainability, it is crucial to comprehend the embedding process, especially the contribution of each part to the embedding process, while understanding how each feature affects the embedding results that identify critical components and help diagnose the embedding process. To address these problems, we have developed a deep neural network method called EVNet, which provides not only excellent performance in structural maintainability but also explainability to the DR therein. EVNet starts with data augmentation and a manifold-based loss function to improve embedding performance. The explanation is based on saliency maps and aims to examine the trained EVNet parameters and contributions of components during the embedding process. The proposed techniques are integrated with a visual interface to help the user to adjust EVNet to achieve better DR performance and explainability. The interactive visual interface makes it easier to illustrate the data features, compare different DR techniques, and investigate DR. An in-depth experimental comparison shows that EVNet consistently outperforms the state-of-the-art methods in both performance measures and explainability.
An Open Source Interactive Visual Analytics Tool for Comparative Programming Comprehension
Jul 29, 2022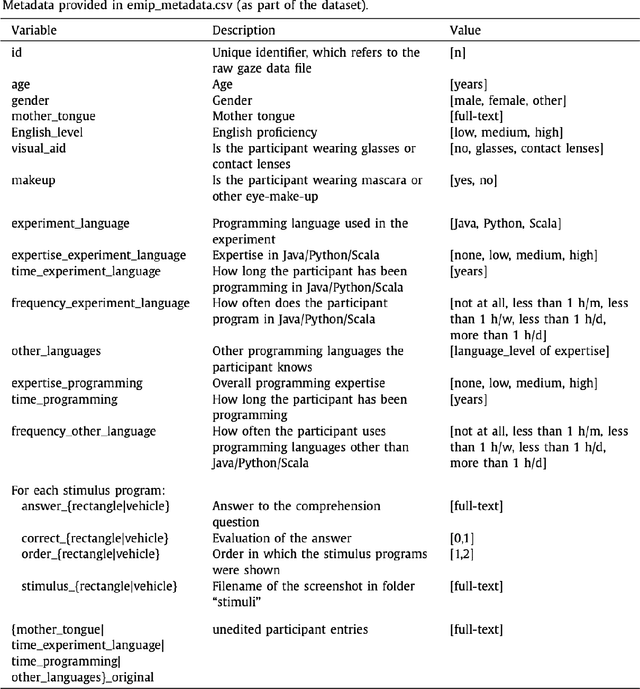



This paper proposes an open source visual analytics tool consisting of several views and perspectives on eye movement data collected during code reading tasks when writing computer programs. Hence the focus of this work is on code and program comprehension. The source code is shown as a visual stimulus. It can be inspected in combination with overlaid scanpaths in which the saccades can be visually encoded in several forms, including straight, curved, and orthogonal lines, modifiable by interaction techniques. The tool supports interaction techniques like filter functions, aggregations, data sampling, and many more. We illustrate the usefulness of our tool by applying it to the eye movements of 216 programmers of multiple expertise levels that were collected during two code comprehension tasks. Our tool helped to analyze the difference between the strategic program comprehension of programmers based on their demographic background, time taken to complete the task, choice of programming task, and expertise.
Beyond 3D Siamese Tracking: A Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds
Mar 03, 2022



3D single object tracking (3D SOT) in LiDAR point clouds plays a crucial role in autonomous driving. Current approaches all follow the Siamese paradigm based on appearance matching. However, LiDAR point clouds are usually textureless and incomplete, which hinders effective appearance matching. Besides, previous methods greatly overlook the critical motion clues among targets. In this work, beyond 3D Siamese tracking, we introduce a motion-centric paradigm to handle 3D SOT from a new perspective. Following this paradigm, we propose a matching-free two-stage tracker M^2-Track. At the 1^st-stage, M^2-Track localizes the target within successive frames via motion transformation. Then it refines the target box through motion-assisted shape completion at the 2^nd-stage. Extensive experiments confirm that M^2-Track significantly outperforms previous state-of-the-arts on three large-scale datasets while running at 57FPS (~8%, ~17%, and ~22%) precision gains on KITTI, NuScenes, and Waymo Open Dataset respectively). Further analysis verifies each component's effectiveness and shows the motion-centric paradigm's promising potential when combined with appearance matching.