 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional Clustering onto Hamiltonian Cycle
Apr 27, 2023



Clustering aims to group unlabelled samples based on their similarities. It has become a significant tool for the analysis of high-dimensional data. However, most of the clustering methods merely generate pseudo labels and thus are unable to simultaneously present the similarities between different clusters and outliers. This paper proposes a new framework called High-dimensional Clustering onto Hamiltonian Cycle (HCHC) to solve the above problems. First, HCHC combines global structure with local structure in one objective function for deep clustering, improving the labels as relative probabilities, to mine the similarities between different clusters while keeping the local structure in each cluster. Then, the anchors of different clusters are sorted on the optimal Hamiltonian cycle generated by the cluster similarities and mapped on the circumference of a circle. Finally, a sample with a higher probability of a cluster will be mapped closer to the corresponding anchor. In this way, our framework allows us to appreciate three aspects visually and simultaneously - clusters (formed by samples with high probabilities), cluster similarities (represented as circular distances), and outliers (recognized as dots far away from all clusters). The experiments illustrate the superiority of HCHC.
Vocabulary-informed Extreme Value Learning
Jan 26, 2018

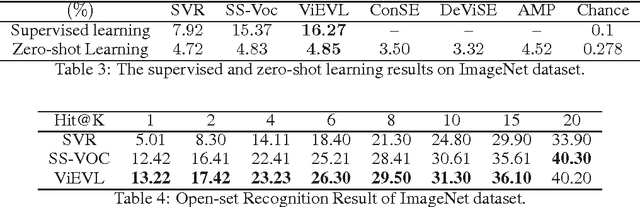
The novel unseen classes can be formulated as the extreme values of known classes. This inspired the recent works on open-set recognition \cite{Scheirer_2013_TPAMI,Scheirer_2014_TPAMIb,EVM}, which however can have no way of naming the novel unseen classes. To solve this problem, we propose the Extreme Value Learning (EVL) formulation to learn the mapping from visual feature to semantic space. To model the margin and coverage distributions of each class, the Vocabulary-informed Learning (ViL) is adopted by using vast open vocabulary in the semantic space. Essentially, by incorporating the EVL and ViL, we for the first time propose a novel semantic embedding paradigm -- Vocabulary-informed Extreme Value Learning (ViEVL), which embeds the visual features into semantic space in a probabilistic way. The learned embedding can be directly used to solve supervised learning, zero-shot and open set recognition simultaneously. Experiments on two benchmark datasets demonstrate the effectiveness of proposed frameworks.