 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned Stable Inpainting: Mitigating Unwanted Object Insertion and Preserving Color Consistency
Jan 21, 2026Generative image inpainting can produce realistic, high-fidelity results even with large, irregular masks. However, existing methods still face key issues that make inpainted images look unnatural. In this paper, we identify two main problems: (1) Unwanted object insertion: generative models may hallucinate arbitrary objects in the masked region that do not match the surrounding context. (2) Color inconsistency: inpainted regions often exhibit noticeable color shifts, leading to smeared textures and degraded image quality. We analyze the underlying causes of these issues and propose efficient post-hoc solutions for pre-trained inpainting models. Specifically, we introduce the principled framework of Aligned Stable inpainting with UnKnown Areas prior (ASUKA). To reduce unwanted object insertion, we use reconstruction-based priors to guide the generative model, suppressing hallucinated objects while preserving generative flexibility. To address color inconsistency, we design a specialized VAE decoder that formulates latent-to-image decoding as a local harmonization task. This design significantly reduces color shifts and produces more color-consistent results. We implement ASUKA on two representative inpainting architectures: a U-Net-based model and a DiT-based model. We analyze and propose lightweight injection strategies that minimize interference with the model's original generation capacity while ensuring the mitigation of the two issues. We evaluate ASUKA using the Places2 dataset and MISATO, our proposed diverse benchmark. Experiments show that ASUKA effectively suppresses object hallucination and improves color consistency, outperforming standard diffusion, rectified flow models, and other inpainting methods. Dataset, models and codes will be released in github.
ActiveVLA: Injecting Active Perception into Vision-Language-Action Models for Precise 3D Robotic Manipulation
Jan 13, 2026Recent advances in robot manipulation have leveraged pre-trained vision-language models (VLMs) and explored integrating 3D spatial signals into these models for effective action prediction, giving rise to the promising vision-language-action (VLA) paradigm. However, most existing approaches overlook the importance of active perception: they typically rely on static, wrist-mounted cameras that provide an end-effector-centric viewpoint. As a result, these models are unable to adaptively select optimal viewpoints or resolutions during task execution, which significantly limits their performance in long-horizon tasks and fine-grained manipulation scenarios. To address these limitations, we propose ActiveVLA, a novel vision-language-action framework that empowers robots with active perception capabilities for high-precision, fine-grained manipulation. ActiveVLA adopts a coarse-to-fine paradigm, dividing the process into two stages: (1) Critical region localization. ActiveVLA projects 3D inputs onto multi-view 2D projections, identifies critical 3D regions, and supports dynamic spatial awareness. (2) Active perception optimization. Drawing on the localized critical regions, ActiveVLA uses an active view selection strategy to choose optimal viewpoints. These viewpoints aim to maximize amodal relevance and diversity while minimizing occlusions. Additionally, ActiveVLA applies a 3D zoom-in to improve resolution in key areas. Together, these steps enable finer-grained active perception for precise manipulation. Extensive experiments demonstrate that ActiveVLA achieves precise 3D manipulation and outperforms state-of-the-art baselines on three simulation benchmarks. Moreover, ActiveVLA transfers seamlessly to real-world scenarios, enabling robots to learn high-precision tasks in complex environments.
CME-CAD: Heterogeneous Collaborative Multi-Expert Reinforcement Learning for CAD Code Generation
Dec 29, 2025Computer-Aided Design (CAD) is essential in industrial design, but the complexity of traditional CAD modeling and workflows presents significant challenges for automating the generation of high-precision, editable CAD models. Existing methods that reconstruct 3D models from sketches often produce non-editable and approximate models that fall short of meeting the stringent requirements for precision and editability in industrial design. Moreover, the reliance on text or image-based inputs often requires significant manual annotation, limiting their scalability and applicability in industrial settings. To overcome these challenges, we propose the Heterogeneous Collaborative Multi-Expert Reinforcement Learning (CME-CAD) paradigm, a novel training paradigm for CAD code generation. Our approach integrates the complementary strengths of these models, facilitating collaborative learning and improving the model's ability to generate accurate, constraint-compatible, and fully editable CAD models. We introduce a two-stage training process: Multi-Expert Fine-Tuning (MEFT), and Multi-Expert Reinforcement Learning (MERL). Additionally, we present CADExpert, an open-source benchmark consisting of 17,299 instances, including orthographic projections with precise dimension annotations, expert-generated Chain-of-Thought (CoT) processes, executable CADQuery code, and rendered 3D models.
VidSplice: Towards Coherent Video Inpainting via Explicit Spaced Frame Guidance
Oct 24, 2025Recent video inpainting methods often employ image-to-video (I2V) priors to model temporal consistency across masked frames. While effective in moderate cases, these methods struggle under severe content degradation and tend to overlook spatiotemporal stability, resulting in insufficient control over the latter parts of the video. To address these limitations, we decouple video inpainting into two sub-tasks: multi-frame consistent image inpainting and masked area motion propagation. We propose VidSplice, a novel framework that introduces spaced-frame priors to guide the inpainting process with spatiotemporal cues. To enhance spatial coherence, we design a CoSpliced Module to perform first-frame propagation strategy that diffuses the initial frame content into subsequent reference frames through a splicing mechanism. Additionally, we introduce a delicate context controller module that encodes coherent priors after frame duplication and injects the spliced video into the I2V generative backbone, effectively constraining content distortion during generation. Extensive evaluations demonstrate that VidSplice achieves competitive performance across diverse video inpainting scenarios. Moreover, its design significantly improves both foreground alignment and motion stability, outperforming existing approaches.
Learning Global Representation from Queries for Vectorized HD Map Construction
Oct 08, 2025The online construction of vectorized high-definition (HD) maps is a cornerstone of modern autonomous driving systems. State-of-the-art approaches, particularly those based on the DETR framework, formulate this as an instance detection problem. However, their reliance on independent, learnable object queries results in a predominantly local query perspective, neglecting the inherent global representation within HD maps. In this work, we propose \textbf{MapGR} (\textbf{G}lobal \textbf{R}epresentation learning for HD \textbf{Map} construction), an architecture designed to learn and utilize a global representations from queries. Our method introduces two synergistic modules: a Global Representation Learning (GRL) module, which encourages the distribution of all queries to better align with the global map through a carefully designed holistic segmentation task, and a Global Representation Guidance (GRG) module, which endows each individual query with explicit, global-level contextual information to facilitate its optimization. Evaluations on the nuScenes and Argoverse2 datasets validate the efficacy of our approach, demonstrating substantial improvements in mean Average Precision (mAP) compared to leading baselines.
Training-Free Pyramid Token Pruning for Efficient Large Vision-Language Models via Region, Token, and Instruction-Guided Importance
Sep 19, 2025Large Vision-Language Models (LVLMs) have significantly advanced multimodal understanding but still struggle with efficiently processing high-resolution images. Recent approaches partition high-resolution images into multiple sub-images, dramatically increasing the number of visual tokens and causing exponential computational overhead during inference. To address these limitations, we propose a training-free token pruning strategy, Pyramid Token Pruning (PTP), that integrates bottom-up visual saliency at both region and token levels with top-down instruction-guided importance. Inspired by human visual attention mechanisms, PTP selectively retains more tokens from visually salient regions and further leverages textual instructions to pinpoint tokens most relevant to specific multimodal tasks. Extensive experiments across 13 diverse benchmarks demonstrate that our method substantially reduces computational overhead and inference latency with minimal performance loss.
HERO: Rethinking Visual Token Early Dropping in High-Resolution Large Vision-Language Models
Sep 16, 2025
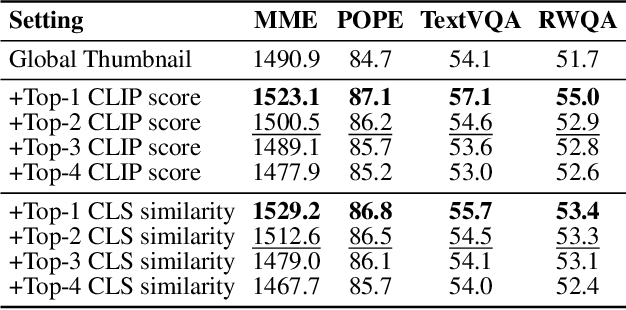
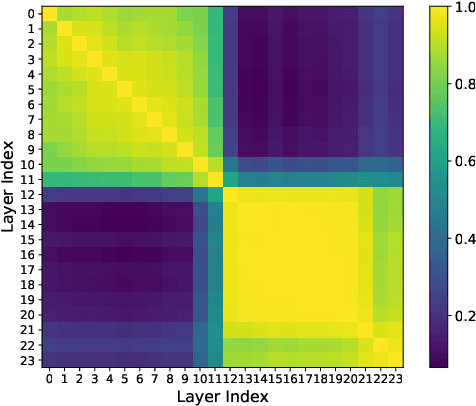
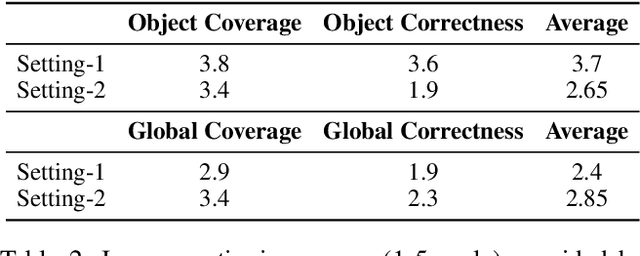
By cropping high-resolution images into local tiles and encoding them independently, High-Resolution Large Vision-Language Models (HR-LVLMs) have demonstrated remarkable fine-grained visual understanding capabilities. However, this divide-and-conquer paradigm significantly increases the number of visual tokens, resulting in substantial computational and memory overhead. To better understand and address this challenge, we empirically investigate visual token utilization in HR-LVLMs and uncover three key findings: (1) the local tiles have varying importance, jointly determined by visual saliency and task relevance; (2) the CLS token in CLIP-based vision encoders exhibits a two-stage attention pattern across layers, with each stage attending to different types of visual tokens; (3) the visual tokens emphasized at different stages encode information at varying levels of granularity, playing complementary roles within LVLMs. Building on these insights, we propose HERO, a High-resolution visual token early dropping framework that integrates content-adaptive token budget allocation with function-aware token selection. By accurately estimating tile-level importance and selectively retaining visual tokens with complementary roles, HERO achieves superior efficiency-accuracy trade-offs across diverse benchmarks and model scales, all in a training-free manner. This study provides both empirical insights and practical solutions toward efficient inference in HR-LVLMs.
From Intent to Execution: Multimodal Chain-of-Thought Reinforcement Learning for Precise CAD Code Generation
Aug 13, 2025Computer-Aided Design (CAD) plays a vital role in engineering and manufacturing, yet current CAD workflows require extensive domain expertise and manual modeling effort. Recent advances in large language models (LLMs) have made it possible to generate code from natural language, opening new opportunities for automating parametric 3D modeling. However, directly translating human design intent into executable CAD code remains highly challenging, due to the need for logical reasoning, syntactic correctness, and numerical precision. In this work, we propose CAD-RL, a multimodal Chain-of-Thought (CoT) guided reinforcement learning post training framework for CAD modeling code generation. Our method combines CoT-based Cold Start with goal-driven reinforcement learning post training using three task-specific rewards: executability reward, geometric accuracy reward, and external evaluation reward. To ensure stable policy learning under sparse and high-variance reward conditions, we introduce three targeted optimization strategies: Trust Region Stretch for improved exploration, Precision Token Loss for enhanced dimensions parameter accuracy, and Overlong Filtering to reduce noisy supervision. To support training and benchmarking, we release ExeCAD, a noval dataset comprising 16,540 real-world CAD examples with paired natural language and structured design language descriptions, executable CADQuery scripts, and rendered 3D models. Experiments demonstrate that CAD-RL achieves significant improvements in reasoning quality, output precision, and code executability over existing VLMs.
Beyond Task-Specific Reasoning: A Unified Conditional Generative Framework for Abstract Visual Reasoning
Jul 15, 2025



Abstract visual reasoning (AVR) enables humans to quickly discover and generalize abstract rules to new scenarios. Designing intelligent systems with human-like AVR abilities has been a long-standing topic in the artificial intelligence community. Deep AVR solvers have recently achieved remarkable success in various AVR tasks. However, they usually use task-specific designs or parameters in different tasks. In such a paradigm, solving new tasks often means retraining the model, and sometimes retuning the model architectures, which increases the cost of solving AVR problems. In contrast to task-specific approaches, this paper proposes a novel Unified Conditional Generative Solver (UCGS), aiming to address multiple AVR tasks in a unified framework. First, we prove that some well-known AVR tasks can be reformulated as the problem of estimating the predictability of target images in problem panels. Then, we illustrate that, under the proposed framework, training one conditional generative model can solve various AVR tasks. The experiments show that with a single round of multi-task training, UCGS demonstrates abstract reasoning ability across various AVR tasks. Especially, UCGS exhibits the ability of zero-shot reasoning, enabling it to perform abstract reasoning on problems from unseen AVR tasks in the testing phase.
A Neural Representation Framework with LLM-Driven Spatial Reasoning for Open-Vocabulary 3D Visual Grounding
Jul 09, 2025



Open-vocabulary 3D visual grounding aims to localize target objects based on free-form language queries, which is crucial for embodied AI applications such as autonomous navigation, robotics, and augmented reality. Learning 3D language fields through neural representations enables accurate understanding of 3D scenes from limited viewpoints and facilitates the localization of target objects in complex environments. However, existing language field methods struggle to accurately localize instances using spatial relations in language queries, such as ``the book on the chair.'' This limitation mainly arises from inadequate reasoning about spatial relations in both language queries and 3D scenes. In this work, we propose SpatialReasoner, a novel neural representation-based framework with large language model (LLM)-driven spatial reasoning that constructs a visual properties-enhanced hierarchical feature field for open-vocabulary 3D visual grounding. To enable spatial reasoning in language queries, SpatialReasoner fine-tunes an LLM to capture spatial relations and explicitly infer instructions for the target, anchor, and spatial relation. To enable spatial reasoning in 3D scenes, SpatialReasoner incorporates visual properties (opacity and color) to construct a hierarchical feature field. This field represents language and instance features using distilled CLIP features and masks extracted via the Segment Anything Model (SAM). The field is then queried using the inferred instructions in a hierarchical manner to localize the target 3D instance based on the spatial relation in the language query. Extensive experiments show that our framework can be seamlessly integrated into different neural representations, outperforming baseline models in 3D visual grounding while empowering their spatial reasoning capability.