 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldStereo: Bridging Camera-Guided Video Generation and Scene Reconstruction via 3D Geometric Memories
Mar 02, 2026Recent advances in foundational Video Diffusion Models (VDMs) have yielded significant progress. Yet, despite the remarkable visual quality of generated videos, reconstructing consistent 3D scenes from these outputs remains challenging, due to limited camera controllability and inconsistent generated content when viewed from distinct camera trajectories. In this paper, we propose WorldStereo, a novel framework that bridges camera-guided video generation and 3D reconstruction via two dedicated geometric memory modules. Formally, the global-geometric memory enables precise camera control while injecting coarse structural priors through incrementally updated point clouds. Moreover, the spatial-stereo memory constrains the model's attention receptive fields with 3D correspondence to focus on fine-grained details from the memory bank. These components enable WorldStereo to generate multi-view-consistent videos under precise camera control, facilitating high-quality 3D reconstruction. Furthermore, the flexible control branch-based WorldStereo shows impressive efficiency, benefiting from the distribution matching distilled VDM backbone without joint training. Extensive experiments across both camera-guided video generation and 3D reconstruction benchmarks demonstrate the effectiveness of our approach. Notably, we show that WorldStereo acts as a powerful world model, tackling diverse scene generation tasks (whether starting from perspective or panoramic images) with high-fidelity 3D results. Models will be released.
WorldCompass: Reinforcement Learning for Long-Horizon World Models
Feb 09, 2026This work presents WorldCompass, a novel Reinforcement Learning (RL) post-training framework for the long-horizon, interactive video-based world models, enabling them to explore the world more accurately and consistently based on interaction signals. To effectively "steer" the world model's exploration, we introduce three core innovations tailored to the autoregressive video generation paradigm: 1) Clip-level rollout Strategy: We generate and evaluate multiple samples at a single target clip, which significantly boosts rollout efficiency and provides fine-grained reward signals. 2) Complementary Reward Functions: We design reward functions for both interaction-following accuracy and visual quality, which provide direct supervision and effectively suppress reward-hacking behaviors. 3) Efficient RL Algorithm: We employ the negative-aware fine-tuning strategy coupled with various efficiency optimizations to efficiently and effectively enhance model capacity. Evaluations on the SoTA open-source world model, WorldPlay, demonstrate that WorldCompass significantly improves interaction accuracy and visual fidelity across various scenarios.
Aligned Stable Inpainting: Mitigating Unwanted Object Insertion and Preserving Color Consistency
Jan 21, 2026Generative image inpainting can produce realistic, high-fidelity results even with large, irregular masks. However, existing methods still face key issues that make inpainted images look unnatural. In this paper, we identify two main problems: (1) Unwanted object insertion: generative models may hallucinate arbitrary objects in the masked region that do not match the surrounding context. (2) Color inconsistency: inpainted regions often exhibit noticeable color shifts, leading to smeared textures and degraded image quality. We analyze the underlying causes of these issues and propose efficient post-hoc solutions for pre-trained inpainting models. Specifically, we introduce the principled framework of Aligned Stable inpainting with UnKnown Areas prior (ASUKA). To reduce unwanted object insertion, we use reconstruction-based priors to guide the generative model, suppressing hallucinated objects while preserving generative flexibility. To address color inconsistency, we design a specialized VAE decoder that formulates latent-to-image decoding as a local harmonization task. This design significantly reduces color shifts and produces more color-consistent results. We implement ASUKA on two representative inpainting architectures: a U-Net-based model and a DiT-based model. We analyze and propose lightweight injection strategies that minimize interference with the model's original generation capacity while ensuring the mitigation of the two issues. We evaluate ASUKA using the Places2 dataset and MISATO, our proposed diverse benchmark. Experiments show that ASUKA effectively suppresses object hallucination and improves color consistency, outperforming standard diffusion, rectified flow models, and other inpainting methods. Dataset, models and codes will be released in github.
RealisMotion: Decomposed Human Motion Control and Video Generation in the World Space
Aug 12, 2025Generating human videos with realistic and controllable motions is a challenging task. While existing methods can generate visually compelling videos, they lack separate control over four key video elements: foreground subject, background video, human trajectory and action patterns. In this paper, we propose a decomposed human motion control and video generation framework that explicitly decouples motion from appearance, subject from background, and action from trajectory, enabling flexible mix-and-match composition of these elements. Concretely, we first build a ground-aware 3D world coordinate system and perform motion editing directly in the 3D space. Trajectory control is implemented by unprojecting edited 2D trajectories into 3D with focal-length calibration and coordinate transformation, followed by speed alignment and orientation adjustment; actions are supplied by a motion bank or generated via text-to-motion methods. Then, based on modern text-to-video diffusion transformer models, we inject the subject as tokens for full attention, concatenate the background along the channel dimension, and add motion (trajectory and action) control signals by addition. Such a design opens up the possibility for us to generate realistic videos of anyone doing anything anywhere. Extensive experiments on benchmark datasets and real-world cases demonstrate that our method achieves state-of-the-art performance on both element-wise controllability and overall video quality.
EarthCrafter: Scalable 3D Earth Generation via Dual-Sparse Latent Diffusion
Jul 23, 2025Despite the remarkable developments achieved by recent 3D generation works, scaling these methods to geographic extents, such as modeling thousands of square kilometers of Earth's surface, remains an open challenge. We address this through a dual innovation in data infrastructure and model architecture. First, we introduce Aerial-Earth3D, the largest 3D aerial dataset to date, consisting of 50k curated scenes (each measuring 600m x 600m) captured across the U.S. mainland, comprising 45M multi-view Google Earth frames. Each scene provides pose-annotated multi-view images, depth maps, normals, semantic segmentation, and camera poses, with explicit quality control to ensure terrain diversity. Building on this foundation, we propose EarthCrafter, a tailored framework for large-scale 3D Earth generation via sparse-decoupled latent diffusion. Our architecture separates structural and textural generation: 1) Dual sparse 3D-VAEs compress high-resolution geometric voxels and textural 2D Gaussian Splats (2DGS) into compact latent spaces, largely alleviating the costly computation suffering from vast geographic scales while preserving critical information. 2) We propose condition-aware flow matching models trained on mixed inputs (semantics, images, or neither) to flexibly model latent geometry and texture features independently. Extensive experiments demonstrate that EarthCrafter performs substantially better in extremely large-scale generation. The framework further supports versatile applications, from semantic-guided urban layout generation to unconditional terrain synthesis, while maintaining geographic plausibility through our rich data priors from Aerial-Earth3D. Our project page is available at https://whiteinblue.github.io/earthcrafter/
Uni3C: Unifying Precisely 3D-Enhanced Camera and Human Motion Controls for Video Generation
Apr 21, 2025



Camera and human motion controls have been extensively studied for video generation, but existing approaches typically address them separately, suffering from limited data with high-quality annotations for both aspects. To overcome this, we present Uni3C, a unified 3D-enhanced framework for precise control of both camera and human motion in video generation. Uni3C includes two key contributions. First, we propose a plug-and-play control module trained with a frozen video generative backbone, PCDController, which utilizes unprojected point clouds from monocular depth to achieve accurate camera control. By leveraging the strong 3D priors of point clouds and the powerful capacities of video foundational models, PCDController shows impressive generalization, performing well regardless of whether the inference backbone is frozen or fine-tuned. This flexibility enables different modules of Uni3C to be trained in specific domains, i.e., either camera control or human motion control, reducing the dependency on jointly annotated data. Second, we propose a jointly aligned 3D world guidance for the inference phase that seamlessly integrates both scenic point clouds and SMPL-X characters to unify the control signals for camera and human motion, respectively. Extensive experiments confirm that PCDController enjoys strong robustness in driving camera motion for fine-tuned backbones of video generation. Uni3C substantially outperforms competitors in both camera controllability and human motion quality. Additionally, we collect tailored validation sets featuring challenging camera movements and human actions to validate the effectiveness of our method.
MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model
Nov 26, 2024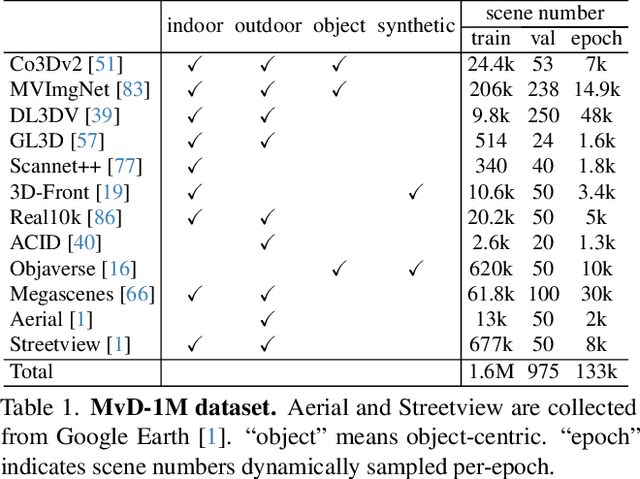
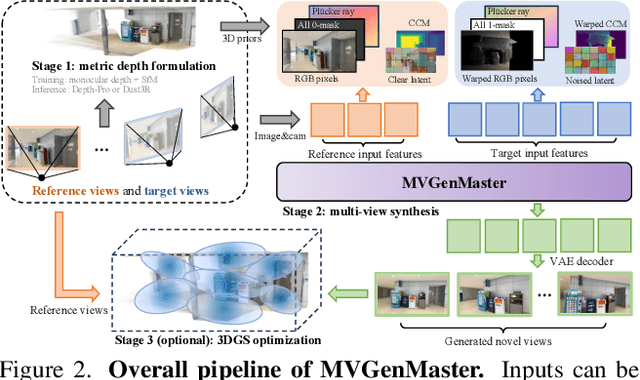
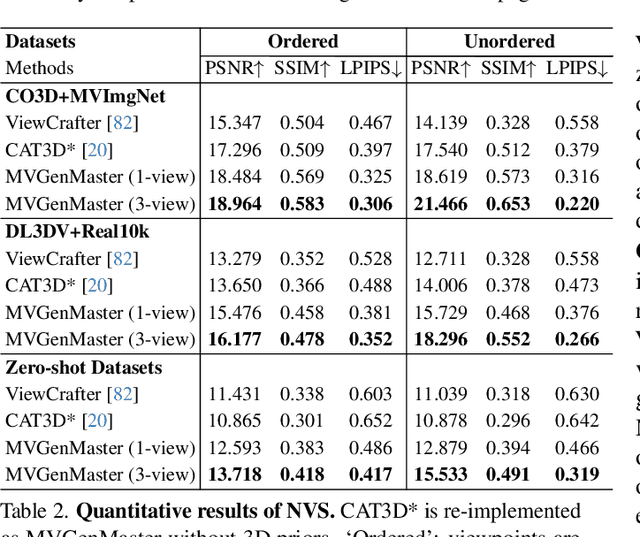
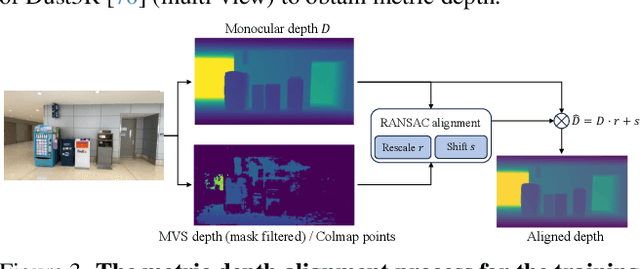
We introduce MVGenMaster, a multi-view diffusion model enhanced with 3D priors to address versatile Novel View Synthesis (NVS) tasks. MVGenMaster leverages 3D priors that are warped using metric depth and camera poses, significantly enhancing both generalization and 3D consistency in NVS. Our model features a simple yet effective pipeline that can generate up to 100 novel views conditioned on variable reference views and camera poses with a single forward process. Additionally, we have developed a comprehensive large-scale multi-view image dataset called MvD-1M, comprising up to 1.6 million scenes, equipped with well-aligned metric depth to train MVGenMaster. Moreover, we present several training and model modifications to strengthen the model with scaled-up datasets. Extensive evaluations across in- and out-of-domain benchmarks demonstrate the effectiveness of our proposed method and data formulation. Models and codes will be released at https://github.com/ewrfcas/MVGenMaster/.
MVInpainter: Learning Multi-View Consistent Inpainting to Bridge 2D and 3D Editing
Aug 15, 2024



Novel View Synthesis (NVS) and 3D generation have recently achieved prominent improvements. However, these works mainly focus on confined categories or synthetic 3D assets, which are discouraged from generalizing to challenging in-the-wild scenes and fail to be employed with 2D synthesis directly. Moreover, these methods heavily depended on camera poses, limiting their real-world applications. To overcome these issues, we propose MVInpainter, re-formulating the 3D editing as a multi-view 2D inpainting task. Specifically, MVInpainter partially inpaints multi-view images with the reference guidance rather than intractably generating an entirely novel view from scratch, which largely simplifies the difficulty of in-the-wild NVS and leverages unmasked clues instead of explicit pose conditions. To ensure cross-view consistency, MVInpainter is enhanced by video priors from motion components and appearance guidance from concatenated reference key&value attention. Furthermore, MVInpainter incorporates slot attention to aggregate high-level optical flow features from unmasked regions to control the camera movement with pose-free training and inference. Sufficient scene-level experiments on both object-centric and forward-facing datasets verify the effectiveness of MVInpainter, including diverse tasks, such as multi-view object removal, synthesis, insertion, and replacement. The project page is https://ewrfcas.github.io/MVInpainter/.
Improving Neural Surface Reconstruction with Feature Priors from Multi-View Image
Aug 04, 2024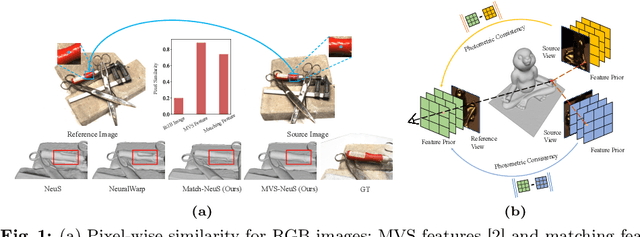
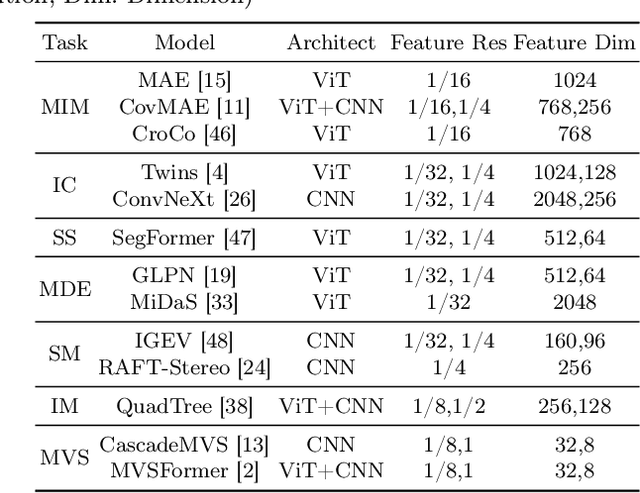
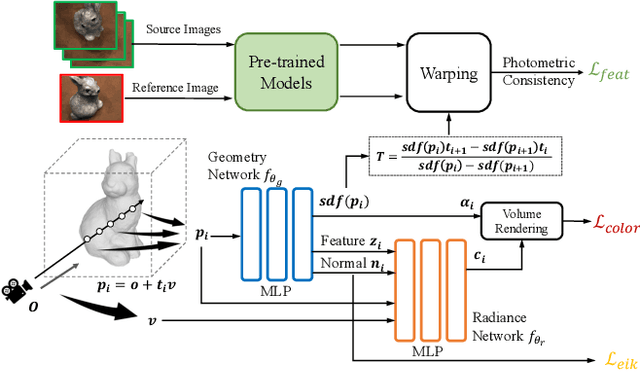

Recent advancements in Neural Surface Reconstruction (NSR) have significantly improved multi-view reconstruction when coupled with volume rendering. However, relying solely on photometric consistency in image space falls short of addressing complexities posed by real-world data, including occlusions and non-Lambertian surfaces. To tackle these challenges, we propose an investigation into feature-level consistent loss, aiming to harness valuable feature priors from diverse pretext visual tasks and overcome current limitations. It is crucial to note the existing gap in determining the most effective pretext visual task for enhancing NSR. In this study, we comprehensively explore multi-view feature priors from seven pretext visual tasks, comprising thirteen methods. Our main goal is to strengthen NSR training by considering a wide range of possibilities. Additionally, we examine the impact of varying feature resolutions and evaluate both pixel-wise and patch-wise consistent losses, providing insights into effective strategies for improving NSR performance. By incorporating pre-trained representations from MVSFormer and QuadTree, our approach can generate variations of MVS-NeuS and Match-NeuS, respectively. Our results, analyzed on DTU and EPFL datasets, reveal that feature priors from image matching and multi-view stereo outperform other pretext tasks. Moreover, we discover that extending patch-wise photometric consistency to the feature level surpasses the performance of pixel-wise approaches. These findings underscore the effectiveness of these techniques in enhancing NSR outcomes.
Animate3D: Animating Any 3D Model with Multi-view Video Diffusion
Jul 16, 2024
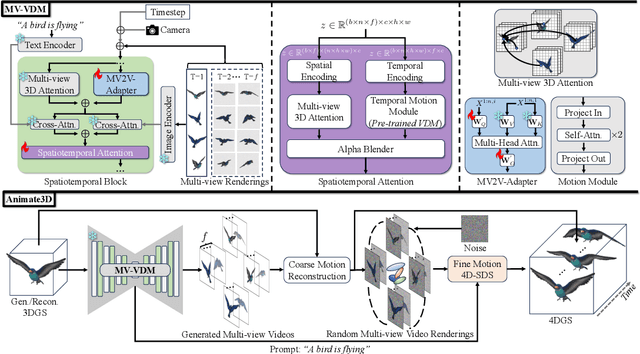


Recent advances in 4D generation mainly focus on generating 4D content by distilling pre-trained text or single-view image-conditioned models. It is inconvenient for them to take advantage of various off-the-shelf 3D assets with multi-view attributes, and their results suffer from spatiotemporal inconsistency owing to the inherent ambiguity in the supervision signals. In this work, we present Animate3D, a novel framework for animating any static 3D model. The core idea is two-fold: 1) We propose a novel multi-view video diffusion model (MV-VDM) conditioned on multi-view renderings of the static 3D object, which is trained on our presented large-scale multi-view video dataset (MV-Video). 2) Based on MV-VDM, we introduce a framework combining reconstruction and 4D Score Distillation Sampling (4D-SDS) to leverage the multi-view video diffusion priors for animating 3D objects. Specifically, for MV-VDM, we design a new spatiotemporal attention module to enhance spatial and temporal consistency by integrating 3D and video diffusion models. Additionally, we leverage the static 3D model's multi-view renderings as conditions to preserve its identity. For animating 3D models, an effective two-stage pipeline is proposed: we first reconstruct motions directly from generated multi-view videos, followed by the introduced 4D-SDS to refine both appearance and motion. Qualitative and quantitative experiments demonstrate that Animate3D significantly outperforms previous approaches. Data, code, and models will be open-released.