 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTL-BenchLS: A Large-Scale Benchmark for RTL Reasoning and Generation with Large Language Models
Jun 08, 2026LLM-based RTL generation and reasoning is a promising direction for hardware design automation. High-quality benchmarks are critical infrastructure for tracking progress in this direction. However, existing RTL benchmarks face inherent limitations in both scale and task scope. The designs they cover are typically small and simple, and the tasks focus almost entirely on specification-to-RTL generation. Frontier models' performance already saturates on the existing benchmarks. Scaling these benchmarks up is fundamentally difficult because aligned labels are required for benchmarking, such as specifications and testbenches. Such aligned high-quality data are rarely available for real-world designs. We introduce RTL-BenchLS, a large-scale benchmark addressing both limitations above. It contains over 10,000 formally verified Verilog designs, covering substantially larger and more complex designs than existing benchmarks. Beyond specification-to-RTL generation, we propose three novel tasks that jointly evaluate reasoning and generation: round-trip reasoning, masked-content reasoning, and repository-issue reasoning. The first two are self-supervised, which directly resolves the scaling bottleneck. All tasks are verified through formal equivalence checking without any manual testbenches. We evaluate eight LLMs on RTL-BenchLS. Even the best model reaches only 23% on natural-language round-trip reasoning, 28% on masked-content reasoning, and 12% on repository-issue fixing. RTL-BenchLS is substantially more challenging than existing benchmarks. It leaves ample room for future improvement and offers guidance for developing LLM-based methods for hardware design.
Dr.~RTL: Autonomous Agentic RTL Optimization through Tool-Grounded Self-Improvement
Apr 16, 2026Recent advances in large language models (LLMs) have sparked growing interest in automatic RTL optimization for better performance, power, and area (PPA). However, existing methods are still far from realistic RTL optimization. Their evaluation settings are often unrealistic: they are tested on manually degraded, small-scale RTL designs and rely on weak open-source tools. Their optimization methods are also limited, relying on coarse design-level feedback and simple pre-defined rewriting rules. To address these limitations, we present Dr. RTL, an agentic framework for RTL timing optimization in a realistic evaluation environment, with continual self-improvement through reusable optimization skills. We establish a realistic evaluation setting with more challenging RTL designs and an industrial EDA workflow. Within this setting, Dr. RTL performs closed-loop optimization through a multi-agent framework for critical-path analysis, parallel RTL rewriting, and tool-based evaluation. We further introduce group-relative skill learning, which compares parallel RTL rewrites and distills the optimization experience into an interpretable skill library. Currently, this library contains 47 pattern--strategy entries for cross-design reuse to improve PPA and accelerate convergence, and it can continue evolving over time. Evaluated on 20 real-world RTL designs, Dr. RTL achieves average WNS/TNS improvements of 21\%/17\% with a 6\% area reduction over the industry-leading commercial synthesis tool.
ShallowJail: Steering Jailbreaks against Large Language Models
Feb 06, 2026Large Language Models(LLMs) have been successful in numerous fields. Alignment has usually been applied to prevent them from harmful purposes. However, aligned LLMs remain vulnerable to jailbreak attacks that deliberately mislead them into producing harmful outputs. Existing jailbreaks are either black-box, using carefully crafted, unstealthy prompts, or white-box, requiring resource-intensive computation. In light of these challenges, we introduce ShallowJail, a novel attack that exploits shallow alignment in LLMs. ShallowJail can misguide LLMs' responses by manipulating the initial tokens during inference. Through extensive experiments, we demonstrate the effectiveness of~\shallow, which substantially degrades the safety of state-of-the-art LLM responses.
A New Benchmark for the Appropriate Evaluation of RTL Code Optimization
Jan 05, 2026The rapid progress of artificial intelligence increasingly relies on efficient integrated circuit (IC) design. Recent studies have explored the use of large language models (LLMs) for generating Register Transfer Level (RTL) code, but existing benchmarks mainly evaluate syntactic correctness rather than optimization quality in terms of power, performance, and area (PPA). This work introduces RTL-OPT, a benchmark for assessing the capability of LLMs in RTL optimization. RTL-OPT contains 36 handcrafted digital designs that cover diverse implementation categories including combinational logic, pipelined datapaths, finite state machines, and memory interfaces. Each task provides a pair of RTL codes, a suboptimal version and a human-optimized reference that reflects industry-proven optimization patterns not captured by conventional synthesis tools. Furthermore, RTL-OPT integrates an automated evaluation framework to verify functional correctness and quantify PPA improvements, enabling standardized and meaningful assessment of generative models for hardware design optimization.
Two Birds with One Stone: Multi-Task Detection and Attribution of LLM-Generated Text
Aug 19, 2025Large Language Models (LLMs), such as GPT-4 and Llama, have demonstrated remarkable abilities in generating natural language. However, they also pose security and integrity challenges. Existing countermeasures primarily focus on distinguishing AI-generated content from human-written text, with most solutions tailored for English. Meanwhile, authorship attribution--determining which specific LLM produced a given text--has received comparatively little attention despite its importance in forensic analysis. In this paper, we present DA-MTL, a multi-task learning framework that simultaneously addresses both text detection and authorship attribution. We evaluate DA-MTL on nine datasets and four backbone models, demonstrating its strong performance across multiple languages and LLM sources. Our framework captures each task's unique characteristics and shares insights between them, which boosts performance in both tasks. Additionally, we conduct a thorough analysis of cross-modal and cross-lingual patterns and assess the framework's robustness against adversarial obfuscation techniques. Our findings offer valuable insights into LLM behavior and the generalization of both detection and authorship attribution.
EarthCrafter: Scalable 3D Earth Generation via Dual-Sparse Latent Diffusion
Jul 23, 2025Despite the remarkable developments achieved by recent 3D generation works, scaling these methods to geographic extents, such as modeling thousands of square kilometers of Earth's surface, remains an open challenge. We address this through a dual innovation in data infrastructure and model architecture. First, we introduce Aerial-Earth3D, the largest 3D aerial dataset to date, consisting of 50k curated scenes (each measuring 600m x 600m) captured across the U.S. mainland, comprising 45M multi-view Google Earth frames. Each scene provides pose-annotated multi-view images, depth maps, normals, semantic segmentation, and camera poses, with explicit quality control to ensure terrain diversity. Building on this foundation, we propose EarthCrafter, a tailored framework for large-scale 3D Earth generation via sparse-decoupled latent diffusion. Our architecture separates structural and textural generation: 1) Dual sparse 3D-VAEs compress high-resolution geometric voxels and textural 2D Gaussian Splats (2DGS) into compact latent spaces, largely alleviating the costly computation suffering from vast geographic scales while preserving critical information. 2) We propose condition-aware flow matching models trained on mixed inputs (semantics, images, or neither) to flexibly model latent geometry and texture features independently. Extensive experiments demonstrate that EarthCrafter performs substantially better in extremely large-scale generation. The framework further supports versatile applications, from semantic-guided urban layout generation to unconditional terrain synthesis, while maintaining geographic plausibility through our rich data priors from Aerial-Earth3D. Our project page is available at https://whiteinblue.github.io/earthcrafter/
Incentivizing High-Quality Human Annotations with Golden Questions
May 25, 2025Human-annotated data plays a vital role in training large language models (LLMs), such as supervised fine-tuning and human preference alignment. However, it is not guaranteed that paid human annotators produce high-quality data. In this paper, we study how to incentivize human annotators to do so. We start from a principal-agent model to model the dynamics between the company (the principal) and the annotator (the agent), where the principal can only monitor the annotation quality by examining $n$ samples. We investigate the maximum likelihood estimators (MLE) and the corresponding hypothesis testing to incentivize annotators: the agent is given a bonus if the MLE passes the test. By analyzing the variance of the outcome, we show that the strategic behavior of the agent makes the hypothesis testing very different from traditional ones: Unlike the exponential rate proved by the large deviation theory, the principal-agent model's hypothesis testing rate is of $\Theta(1/\sqrt{n \log n})$. Our theory implies two criteria for the \emph{golden questions} to monitor the performance of the annotators: they should be of (1) high certainty and (2) similar format to normal ones. In that light, we select a set of golden questions in human preference data. By doing incentive-compatible experiments, we find out that the annotators' behavior is better revealed by those golden questions, compared to traditional survey techniques such as instructed manipulation checks.
Can Differentially Private Fine-tuning LLMs Protect Against Privacy Attacks?
May 01, 2025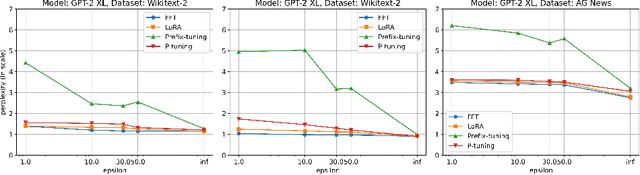
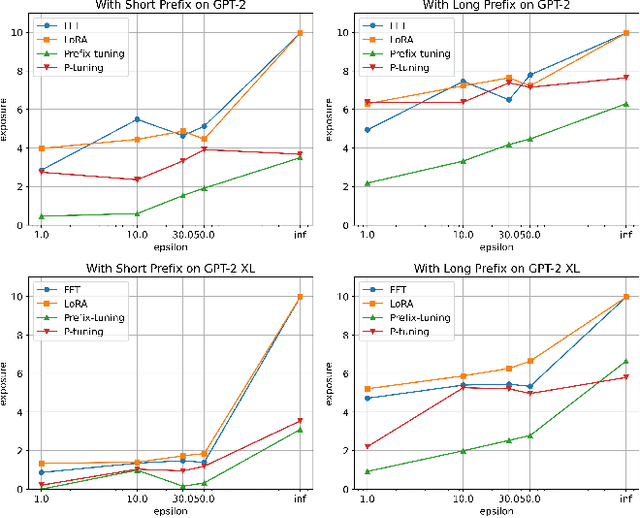
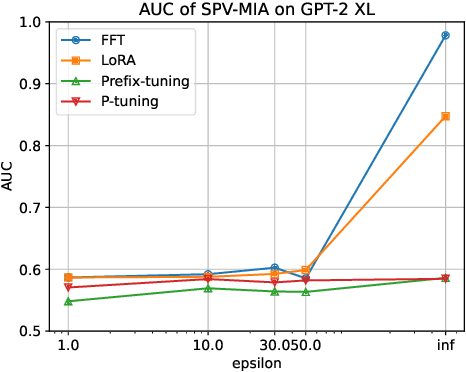
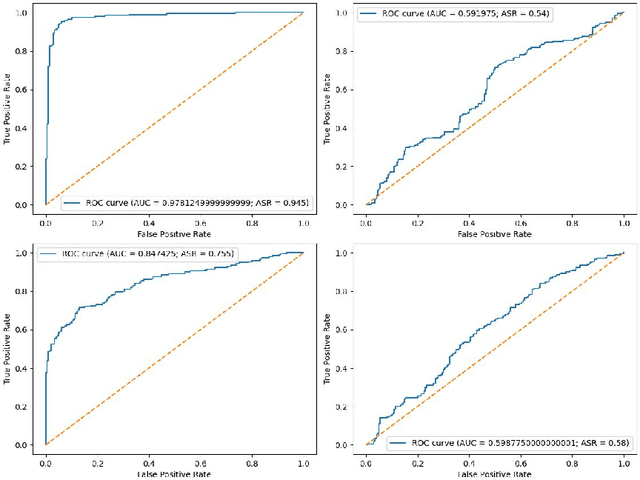
Fine-tuning large language models (LLMs) has become an essential strategy for adapting them to specialized tasks; however, this process introduces significant privacy challenges, as sensitive training data may be inadvertently memorized and exposed. Although differential privacy (DP) offers strong theoretical guarantees against such leakage, its empirical privacy effectiveness on LLMs remains unclear, especially under different fine-tuning methods. In this paper, we systematically investigate the impact of DP across fine-tuning methods and privacy budgets, using both data extraction and membership inference attacks to assess empirical privacy risks. Our main findings are as follows: (1) Differential privacy reduces model utility, but its impact varies significantly across different fine-tuning methods. (2) Without DP, the privacy risks of models fine-tuned with different approaches differ considerably. (3) When DP is applied, even a relatively high privacy budget can substantially lower privacy risk. (4) The privacy-utility trade-off under DP training differs greatly among fine-tuning methods, with some methods being unsuitable for DP due to severe utility degradation. Our results provide practical guidance for privacy-conscious deployment of LLMs and pave the way for future research on optimizing the privacy-utility trade-off in fine-tuning methodologies.
GenEDA: Unleashing Generative Reasoning on Netlist via Multimodal Encoder-Decoder Aligned Foundation Model
Apr 13, 2025



The success of foundation AI has motivated the research of circuit foundation models, which are customized to assist the integrated circuit (IC) design process. However, existing pre-trained circuit models are typically limited to standalone encoders for predictive tasks or decoders for generative tasks. These two model types are developed independently, operate on different circuit modalities, and reside in separate latent spaces, which restricts their ability to complement each other for more advanced applications. In this work, we present GenEDA, the first framework that aligns circuit encoders with decoders within a shared latent space. GenEDA bridges the gap between graph-based circuit representations and text-based large language models (LLMs), enabling communication between their respective latent spaces. To achieve the alignment, we propose two paradigms that support both open-source trainable LLMs and commercial frozen LLMs. Built on this aligned architecture, GenEDA enables three unprecedented generative reasoning tasks over netlists, where the model reversely generates the high-level functionality from low-level netlists in different granularities. These tasks extend traditional gate-type prediction to direct generation of full-circuit functionality. Experiments demonstrate that GenEDA significantly boosts advanced LLMs' (e.g., GPT-4o and DeepSeek-V3) performance in all tasks.
NetTAG: A Multimodal RTL-and-Layout-Aligned Netlist Foundation Model via Text-Attributed Graph
Apr 12, 2025



Circuit representation learning has shown promise in advancing Electronic Design Automation (EDA) by capturing structural and functional circuit properties for various tasks. Existing pre-trained solutions rely on graph learning with complex functional supervision, such as truth table simulation. However, they only handle simple and-inverter graphs (AIGs), struggling to fully encode other complex gate functionalities. While large language models (LLMs) excel at functional understanding, they lack the structural awareness for flattened netlists. To advance netlist representation learning, we present NetTAG, a netlist foundation model that fuses gate semantics with graph structure, handling diverse gate types and supporting a variety of functional and physical tasks. Moving beyond existing graph-only methods, NetTAG formulates netlists as text-attributed graphs, with gates annotated by symbolic logic expressions and physical characteristics as text attributes. Its multimodal architecture combines an LLM-based text encoder for gate semantics and a graph transformer for global structure. Pre-trained with gate and graph self-supervised objectives and aligned with RTL and layout stages, NetTAG captures comprehensive circuit intrinsics. Experimental results show that NetTAG consistently outperforms each task-specific method on four largely different functional and physical tasks and surpasses state-of-the-art AIG encoders, demonstrating its versatility.