 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating an Imperfect Auxiliary Predictor for Unobserved No-Purchase Choice
Feb 13, 2026Firms typically cannot observe key consumer actions: whether customers buy from a competitor, choose not to buy, or even fully consider the firm's offer. This missing outside-option information makes market-size and preference estimation difficult even in simple multinomial logit (MNL) models, and it is a central obstacle in practice when only transaction data are recorded. Existing approaches often rely on auxiliary market-share, aggregated, or cross-market data. We study a complementary setting in which a black-box auxiliary predictor provides outside-option probabilities, but is potentially biased or miscalibrated because it was trained in a different channel, period, or population, or produced by an external machine-learning system. We develop calibration methods that turn such imperfect predictions into statistically valid no-purchase estimates using purchase-only data from the focal environment. First, under affine miscalibration in logit space, we show that a simple regression identifies outside-option utility parameters and yields consistent recovery of no-purchase probabilities without collecting new labels for no-purchase events. Second, under a weaker nearly monotone condition, we propose a rank-based calibration method and derive finite-sample error bounds that cleanly separate auxiliary-predictor quality from first-stage utility-learning error over observed in-set choices. Our analysis also translates estimation error into downstream decision quality for assortment optimization, quantifying how calibration accuracy affects revenue performance. The bounds provide explicit dependence on predictor alignment and utility-learning error, clarifying when each source dominates. Numerical experiments demonstrate improvements in no-purchase estimation and downstream assortment decisions, and we discuss robust aggregation extensions for combining multiple auxiliary predictors.
Learning Shortest Paths When Data is Scarce
Jan 07, 2026Digital twins and other simulators are increasingly used to support routing decisions in large-scale networks. However, simulator outputs often exhibit systematic bias, while ground-truth measurements are costly and scarce. We study a stochastic shortest-path problem in which a planner has access to abundant synthetic samples, limited real-world observations, and an edge-similarity structure capturing expected behavioral similarity across links. We model the simulator-to-reality discrepancy as an unknown, edge-specific bias that varies smoothly over the similarity graph, and estimate it using Laplacian-regularized least squares. This approach yields calibrated edge cost estimates even in data-scarce regimes. We establish finite-sample error bounds, translate estimation error into path-level suboptimality guarantees, and propose a computable, data-driven certificate that verifies near-optimality of a candidate route. For cold-start settings without initial real data, we develop a bias-aware active learning algorithm that leverages the simulator and adaptively selects edges to measure until a prescribed accuracy is met. Numerical experiments on multiple road networks and traffic graphs further demonstrate the effectiveness of our methods.
Incentivizing High-Quality Human Annotations with Golden Questions
May 25, 2025Human-annotated data plays a vital role in training large language models (LLMs), such as supervised fine-tuning and human preference alignment. However, it is not guaranteed that paid human annotators produce high-quality data. In this paper, we study how to incentivize human annotators to do so. We start from a principal-agent model to model the dynamics between the company (the principal) and the annotator (the agent), where the principal can only monitor the annotation quality by examining $n$ samples. We investigate the maximum likelihood estimators (MLE) and the corresponding hypothesis testing to incentivize annotators: the agent is given a bonus if the MLE passes the test. By analyzing the variance of the outcome, we show that the strategic behavior of the agent makes the hypothesis testing very different from traditional ones: Unlike the exponential rate proved by the large deviation theory, the principal-agent model's hypothesis testing rate is of $\Theta(1/\sqrt{n \log n})$. Our theory implies two criteria for the \emph{golden questions} to monitor the performance of the annotators: they should be of (1) high certainty and (2) similar format to normal ones. In that light, we select a set of golden questions in human preference data. By doing incentive-compatible experiments, we find out that the annotators' behavior is better revealed by those golden questions, compared to traditional survey techniques such as instructed manipulation checks.
OMGPT: A Sequence Modeling Framework for Data-driven Operational Decision Making
May 19, 2025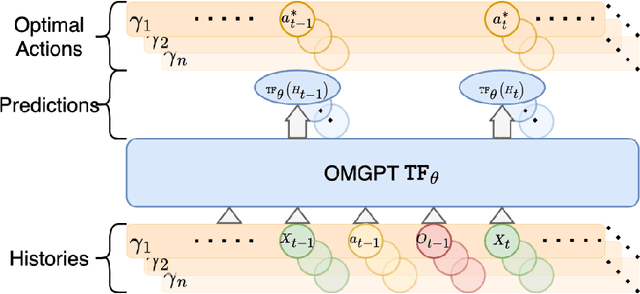



We build a Generative Pre-trained Transformer (GPT) model from scratch to solve sequential decision making tasks arising in contexts of operations research and management science which we call OMGPT. We first propose a general sequence modeling framework to cover several operational decision making tasks as special cases, such as dynamic pricing, inventory management, resource allocation, and queueing control. Under the framework, all these tasks can be viewed as a sequential prediction problem where the goal is to predict the optimal future action given all the historical information. Then we train a transformer-based neural network model (OMGPT) as a natural and powerful architecture for sequential modeling. This marks a paradigm shift compared to the existing methods for these OR/OM tasks in that (i) the OMGPT model can take advantage of the huge amount of pre-trained data; (ii) when tackling these problems, OMGPT does not assume any analytical model structure and enables a direct and rich mapping from the history to the future actions. Either of these two aspects, to the best of our knowledge, is not achieved by any existing method. We establish a Bayesian perspective to theoretically understand the working mechanism of the OMGPT on these tasks, which relates its performance with the pre-training task diversity and the divergence between the testing task and pre-training tasks. Numerically, we observe a surprising performance of the proposed model across all the above tasks.
How Humans Help LLMs: Assessing and Incentivizing Human Preference Annotators
Feb 10, 2025Human-annotated preference data play an important role in aligning large language models (LLMs). In this paper, we investigate the questions of assessing the performance of human annotators and incentivizing them to provide high-quality annotations. The quality assessment of language/text annotation faces two challenges: (i) the intrinsic heterogeneity among annotators, which prevents the classic methods that assume the underlying existence of a true label; and (ii) the unclear relationship between the annotation quality and the performance of downstream tasks, which excludes the possibility of inferring the annotators' behavior based on the model performance trained from the annotation data. Then we formulate a principal-agent model to characterize the behaviors of and the interactions between the company and the human annotators. The model rationalizes a practical mechanism of a bonus scheme to incentivize annotators which benefits both parties and it underscores the importance of the joint presence of an assessment system and a proper contract scheme. From a technical perspective, our analysis extends the existing literature on the principal-agent model by considering a continuous action space for the agent. We show the gap between the first-best and the second-best solutions (under the continuous action space) is of $\Theta(1/\sqrt{n \log n})$ for the binary contracts and $\Theta(1/n)$ for the linear contracts, where $n$ is the number of samples used for performance assessment; this contrasts with the known result of $\exp(-\Theta(n))$ for the binary contracts when the action space is discrete. Throughout the paper, we use real preference annotation data to accompany our discussions.
Understanding the Training and Generalization of Pretrained Transformer for Sequential Decision Making
May 23, 2024



In this paper, we consider the supervised pretrained transformer for a class of sequential decision-making problems. The class of considered problems is a subset of the general formulation of reinforcement learning in that there is no transition probability matrix, and the class of problems covers bandits, dynamic pricing, and newsvendor problems as special cases. Such a structure enables the use of optimal actions/decisions in the pretraining phase, and the usage also provides new insights for the training and generalization of the pretrained transformer. We first note that the training of the transformer model can be viewed as a performative prediction problem, and the existing methods and theories largely ignore or cannot resolve the arisen out-of-distribution issue. We propose a natural solution that includes the transformer-generated action sequences in the training procedure, and it enjoys better properties both numerically and theoretically. The availability of the optimal actions in the considered tasks also allows us to analyze the properties of the pretrained transformer as an algorithm and explains why it may lack exploration and how this can be automatically resolved. Numerically, we categorize the advantages of the pretrained transformer over the structured algorithms such as UCB and Thompson sampling into three cases: (i) it better utilizes the prior knowledge in the pretraining data; (ii) it can elegantly handle the misspecification issue suffered by the structured algorithms; (iii) for short time horizon such as $T\le50$, it behaves more greedy and enjoys much better regret than the structured algorithms which are designed for asymptotic optimality.
Towards Better Statistical Understanding of Watermarking LLMs
Mar 19, 2024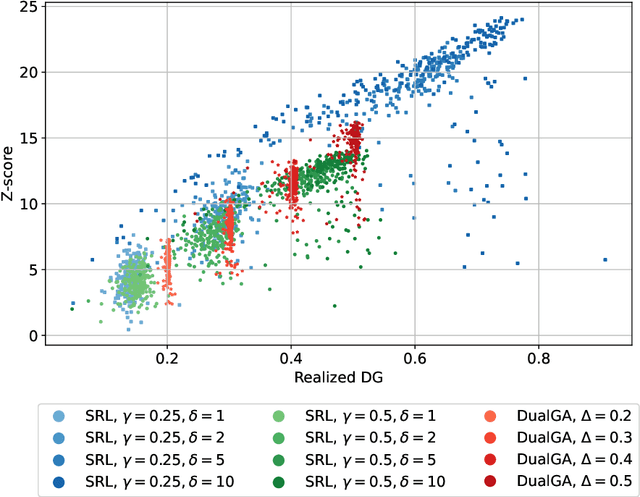
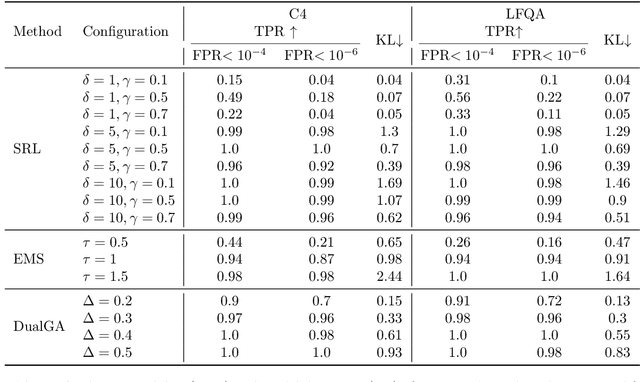
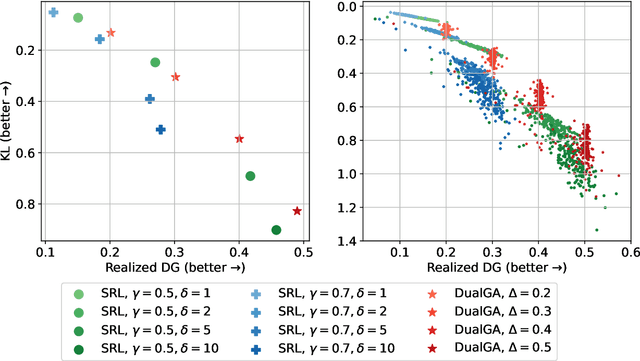
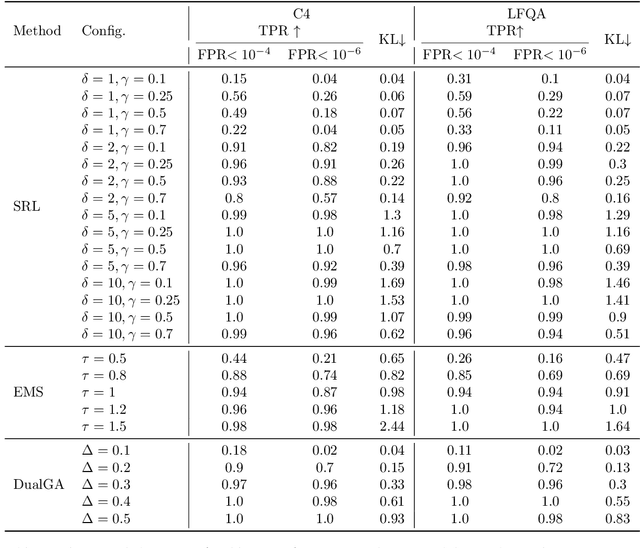
In this paper, we study the problem of watermarking large language models (LLMs). We consider the trade-off between model distortion and detection ability and formulate it as a constrained optimization problem based on the green-red algorithm of Kirchenbauer et al. (2023a). We show that the optimal solution to the optimization problem enjoys a nice analytical property which provides a better understanding and inspires the algorithm design for the watermarking process. We develop an online dual gradient ascent watermarking algorithm in light of this optimization formulation and prove its asymptotic Pareto optimality between model distortion and detection ability. Such a result guarantees an averaged increased green list probability and henceforth detection ability explicitly (in contrast to previous results). Moreover, we provide a systematic discussion on the choice of the model distortion metrics for the watermarking problem. We justify our choice of KL divergence and present issues with the existing criteria of ``distortion-free'' and perplexity. Finally, we empirically evaluate our algorithms on extensive datasets against benchmark algorithms.
Transformer Choice Net: A Transformer Neural Network for Choice Prediction
Oct 12, 2023



Discrete-choice models, such as Multinomial Logit, Probit, or Mixed-Logit, are widely used in Marketing, Economics, and Operations Research: given a set of alternatives, the customer is modeled as choosing one of the alternatives to maximize a (latent) utility function. However, extending such models to situations where the customer chooses more than one item (such as in e-commerce shopping) has proven problematic. While one can construct reasonable models of the customer's behavior, estimating such models becomes very challenging because of the combinatorial explosion in the number of possible subsets of items. In this paper we develop a transformer neural network architecture, the Transformer Choice Net, that is suitable for predicting multiple choices. Transformer networks turn out to be especially suitable for this task as they take into account not only the features of the customer and the items but also the context, which in this case could be the assortment as well as the customer's past choices. On a range of benchmark datasets, our architecture shows uniformly superior out-of-sample prediction performance compared to the leading models in the literature, without requiring any custom modeling or tuning for each instance.
Learning to Make Adherence-Aware Advice
Oct 01, 2023
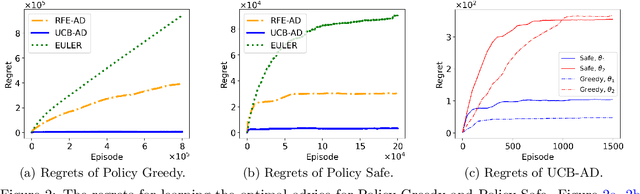


As artificial intelligence (AI) systems play an increasingly prominent role in human decision-making, challenges surface in the realm of human-AI interactions. One challenge arises from the suboptimal AI policies due to the inadequate consideration of humans disregarding AI recommendations, as well as the need for AI to provide advice selectively when it is most pertinent. This paper presents a sequential decision-making model that (i) takes into account the human's adherence level (the probability that the human follows/rejects machine advice) and (ii) incorporates a defer option so that the machine can temporarily refrain from making advice. We provide learning algorithms that learn the optimal advice policy and make advice only at critical time stamps. Compared to problem-agnostic reinforcement learning algorithms, our specialized learning algorithms not only enjoy better theoretical convergence properties but also show strong empirical performance.
A Neural Network Based Choice Model for Assortment Optimization
Aug 10, 2023Discrete-choice models are used in economics, marketing and revenue management to predict customer purchase probabilities, say as a function of prices and other features of the offered assortment. While they have been shown to be expressive, capturing customer heterogeneity and behaviour, they are also hard to estimate, often based on many unobservables like utilities; and moreover, they still fail to capture many salient features of customer behaviour. A natural question then, given their success in other contexts, is if neural networks can eliminate the necessity of carefully building a context-dependent customer behaviour model and hand-coding and tuning the estimation. It is unclear however how one would incorporate assortment effects into such a neural network, and also how one would optimize the assortment with such a black-box generative model of choice probabilities. In this paper we investigate first whether a single neural network architecture can predict purchase probabilities for datasets from various contexts and generated under various models and assumptions. Next, we develop an assortment optimization formulation that is solvable by off-the-shelf integer programming solvers. We compare against a variety of benchmark discrete-choice models on simulated as well as real-world datasets, developing training tricks along the way to make the neural network prediction and subsequent optimization robust and comparable in performance to the alternates.