 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning While Repositioning in On-Demand Vehicle Sharing Networks
Jan 31, 2025We consider a network inventory problem motivated by one-way, on-demand vehicle sharing services. Due to uncertainties in both demand and returns, as well as a fixed number of rental units across an $n$-location network, the service provider must periodically reposition vehicles to match supply with demand spatially while minimizing costs. The optimal repositioning policy under a general $n$-location network is intractable without knowing the optimal value function. We introduce the best base-stock repositioning policy as a generalization of the classical inventory control policy to $n$ dimensions, and establish its asymptotic optimality in two distinct limiting regimes under general network structures. We present reformulations to efficiently compute this best base-stock policy in an offline setting with pre-collected data. In the online setting, we show that a natural Lipschitz-bandit approach achieves a regret guarantee of $\widetilde{O}(T^{\frac{n}{n+1}})$, which suffers from the exponential dependence on $n$. We illustrate the challenges of learning with censored data in networked systems through a regret lower bound analysis and by demonstrating the suboptimality of alternative algorithmic approaches. Motivated by these challenges, we propose an Online Gradient Repositioning algorithm that relies solely on censored demand. Under a mild cost-structure assumption, we prove that it attains an optimal regret of $O(n^{2.5} \sqrt{T})$, which matches the regret lower bound in $T$ and achieves only polynomial dependence on $n$. The key algorithmic innovation involves proposing surrogate costs to disentangle intertemporal dependencies and leveraging dual solutions to find the gradient of policy change. Numerical experiments demonstrate the effectiveness of our proposed methods.
Beyond $\mathcal{O}(\sqrt{T})$ Regret: Decoupling Learning and Decision-making in Online Linear Programming
Jan 06, 2025



Online linear programming plays an important role in both revenue management and resource allocation, and recent research has focused on developing efficient first-order online learning algorithms. Despite the empirical success of first-order methods, they typically achieve a regret no better than $\mathcal{O} ( \sqrt{T} )$, which is suboptimal compared to the $\mathcal{O} (\log T)$ bound guaranteed by the state-of-the-art linear programming (LP)-based online algorithms. This paper establishes a general framework that improves upon the $\mathcal{O} ( \sqrt{T} )$ result when the LP dual problem exhibits certain error bound conditions. For the first time, we show that first-order learning algorithms achieve $o( \sqrt{T} )$ regret in the continuous support setting and $\mathcal{O} (\log T)$ regret in the finite support setting beyond the non-degeneracy assumption. Our results significantly improve the state-of-the-art regret results and provide new insights for sequential decision-making.
Decoupling Learning and Decision-Making: Breaking the $\mathcal{O}(\sqrt{T})$ Barrier in Online Resource Allocation with First-Order Methods
Feb 11, 2024Online linear programming plays an important role in both revenue management and resource allocation, and recent research has focused on developing efficient first-order online learning algorithms. Despite the empirical success of first-order methods, they typically achieve a regret no better than $\mathcal{O}(\sqrt{T})$, which is suboptimal compared to the $\mathcal{O}(\log T)$ bound guaranteed by the state-of-the-art linear programming (LP)-based online algorithms. This paper establishes several important facts about online linear programming, which unveils the challenge for first-order-method-based online algorithms to achieve beyond $\mathcal{O}(\sqrt{T})$ regret. To address the challenge, we introduce a new algorithmic framework that decouples learning from decision-making. More importantly, for the first time, we show that first-order methods can attain regret $\mathcal{O}(T^{1/3})$ with this new framework. Lastly, we conduct numerical experiments to validate our theoretical findings.
Learning to Make Adherence-Aware Advice
Oct 01, 2023
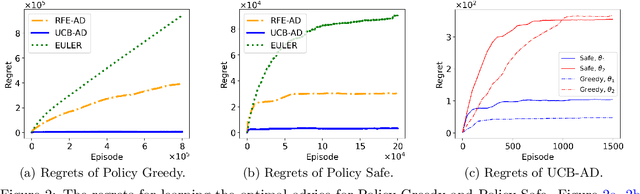


As artificial intelligence (AI) systems play an increasingly prominent role in human decision-making, challenges surface in the realm of human-AI interactions. One challenge arises from the suboptimal AI policies due to the inadequate consideration of humans disregarding AI recommendations, as well as the need for AI to provide advice selectively when it is most pertinent. This paper presents a sequential decision-making model that (i) takes into account the human's adherence level (the probability that the human follows/rejects machine advice) and (ii) incorporates a defer option so that the machine can temporarily refrain from making advice. We provide learning algorithms that learn the optimal advice policy and make advice only at critical time stamps. Compared to problem-agnostic reinforcement learning algorithms, our specialized learning algorithms not only enjoy better theoretical convergence properties but also show strong empirical performance.
When No-Rejection Learning is Optimal for Regression with Rejection
Jul 06, 2023



Learning with rejection is a prototypical model for studying the interaction between humans and AI on prediction tasks. The model has two components, a predictor and a rejector. Upon the arrival of a sample, the rejector first decides whether to accept it; if accepted, the predictor fulfills the prediction task, and if rejected, the prediction will be deferred to humans. The learning problem requires learning a predictor and a rejector simultaneously. This changes the structure of the conventional loss function and often results in non-convexity and inconsistency issues. For the classification with rejection problem, several works develop surrogate losses for the jointly learning with provable consistency guarantees; in parallel, there has been less work for the regression counterpart. We study the regression with rejection (RwR) problem and investigate the no-rejection learning strategy which treats the RwR problem as a standard regression task to learn the predictor. We establish that the suboptimality of the no-rejection learning strategy observed in the literature can be mitigated by enlarging the function class of the predictor. Then we introduce the truncated loss to single out the learning for the predictor and we show that a consistent surrogate property can be established for the predictor individually in an easier way than for the predictor and the rejector jointly. Our findings advocate for a two-step learning procedure that first uses all the data to learn the predictor and then calibrates the prediction loss for the rejector. It is better aligned with the common intuition that more data samples will lead to a better predictor and it calls for more efforts on a better design of calibration algorithms for learning the rejector. While our discussions mainly focus on the regression problem, the theoretical results and insights generalize to the classification problem as well.
Maximum Optimality Margin: A Unified Approach for Contextual Linear Programming and Inverse Linear Programming
Jan 26, 2023In this paper, we study the predict-then-optimize problem where the output of a machine learning prediction task is used as the input of some downstream optimization problem, say, the objective coefficient vector of a linear program. The problem is also known as predictive analytics or contextual linear programming. The existing approaches largely suffer from either (i) optimization intractability (a non-convex objective function)/statistical inefficiency (a suboptimal generalization bound) or (ii) requiring strong condition(s) such as no constraint or loss calibration. We develop a new approach to the problem called \textit{maximum optimality margin} which designs the machine learning loss function by the optimality condition of the downstream optimization. The max-margin formulation enjoys both computational efficiency and good theoretical properties for the learning procedure. More importantly, our new approach only needs the observations of the optimal solution in the training data rather than the objective function, which makes it a new and natural approach to the inverse linear programming problem under both contextual and context-free settings; we also analyze the proposed method under both offline and online settings, and demonstrate its performance using numerical experiments.
An Adaptive State Aggregation Algorithm for Markov Decision Processes
Jul 23, 2021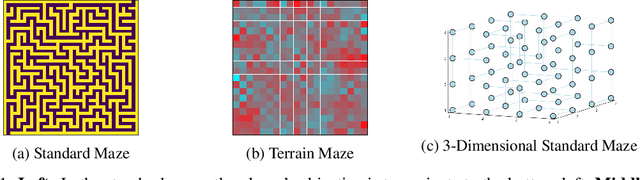

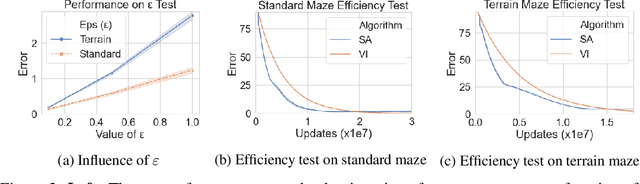
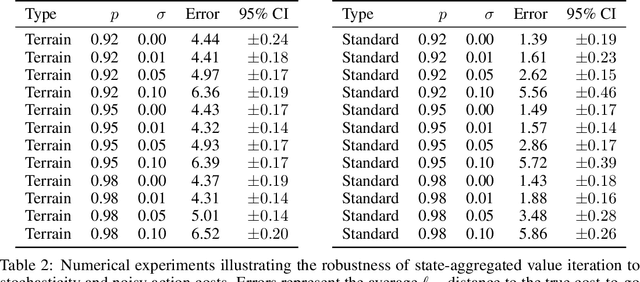
Value iteration is a well-known method of solving Markov Decision Processes (MDPs) that is simple to implement and boasts strong theoretical convergence guarantees. However, the computational cost of value iteration quickly becomes infeasible as the size of the state space increases. Various methods have been proposed to overcome this issue for value iteration in large state and action space MDPs, often at the price, however, of generalizability and algorithmic simplicity. In this paper, we propose an intuitive algorithm for solving MDPs that reduces the cost of value iteration updates by dynamically grouping together states with similar cost-to-go values. We also prove that our algorithm converges almost surely to within \(2\varepsilon / (1 - \gamma)\) of the true optimal value in the \(\ell^\infty\) norm, where \(\gamma\) is the discount factor and aggregated states differ by at most \(\varepsilon\). Numerical experiments on a variety of simulated environments confirm the robustness of our algorithm and its ability to solve MDPs with much cheaper updates especially as the scale of the MDP problem increases.
The Symmetry between Arms and Knapsacks: A Primal-Dual Approach for Bandits with Knapsacks
Feb 19, 2021In this paper, we study the bandits with knapsacks (BwK) problem and develop a primal-dual based algorithm that achieves a problem-dependent logarithmic regret bound. The BwK problem extends the multi-arm bandit (MAB) problem to model the resource consumption associated with playing each arm, and the existing BwK literature has been mainly focused on deriving asymptotically optimal distribution-free regret bounds. We first study the primal and dual linear programs underlying the BwK problem. From this primal-dual perspective, we discover symmetry between arms and knapsacks, and then propose a new notion of sub-optimality measure for the BwK problem. The sub-optimality measure highlights the important role of knapsacks in determining algorithm regret and inspires the design of our two-phase algorithm. In the first phase, the algorithm identifies the optimal arms and the binding knapsacks, and in the second phase, it exhausts the binding knapsacks via playing the optimal arms through an adaptive procedure. Our regret upper bound involves the proposed sub-optimality measure and it has a logarithmic dependence on length of horizon $T$ and a polynomial dependence on $m$ (the numbers of arms) and $d$ (the number of knapsacks). To the best of our knowledge, this is the first problem-dependent logarithmic regret bound for solving the general BwK problem.