 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive State Aggregation Algorithm for Markov Decision Processes
Jul 23, 2021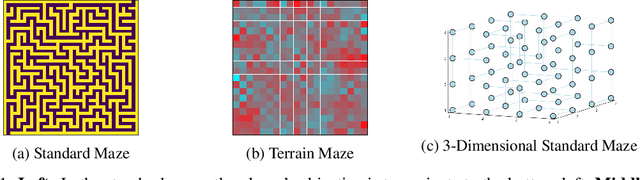

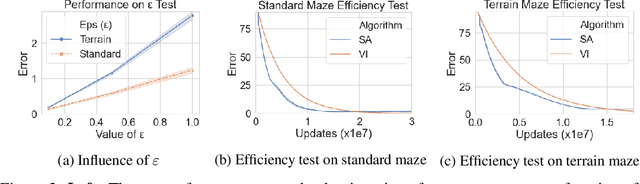
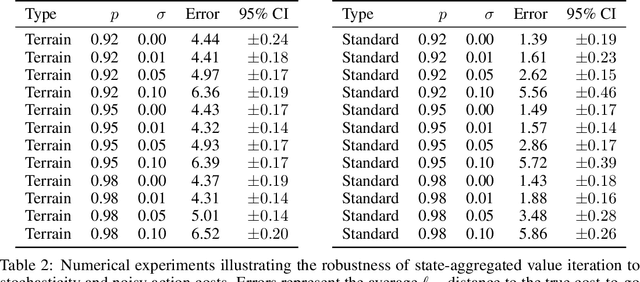
Value iteration is a well-known method of solving Markov Decision Processes (MDPs) that is simple to implement and boasts strong theoretical convergence guarantees. However, the computational cost of value iteration quickly becomes infeasible as the size of the state space increases. Various methods have been proposed to overcome this issue for value iteration in large state and action space MDPs, often at the price, however, of generalizability and algorithmic simplicity. In this paper, we propose an intuitive algorithm for solving MDPs that reduces the cost of value iteration updates by dynamically grouping together states with similar cost-to-go values. We also prove that our algorithm converges almost surely to within \(2\varepsilon / (1 - \gamma)\) of the true optimal value in the \(\ell^\infty\) norm, where \(\gamma\) is the discount factor and aggregated states differ by at most \(\varepsilon\). Numerical experiments on a variety of simulated environments confirm the robustness of our algorithm and its ability to solve MDPs with much cheaper updates especially as the scale of the MDP problem increases.
Linear Representation Meta-Reinforcement Learning for Instant Adaptation
Jan 12, 2021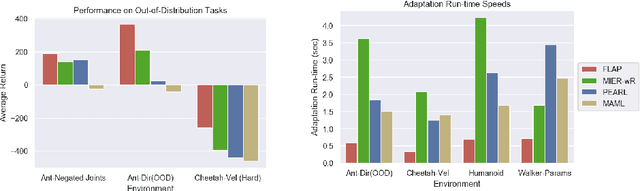
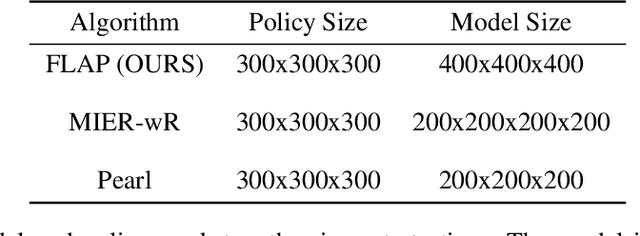
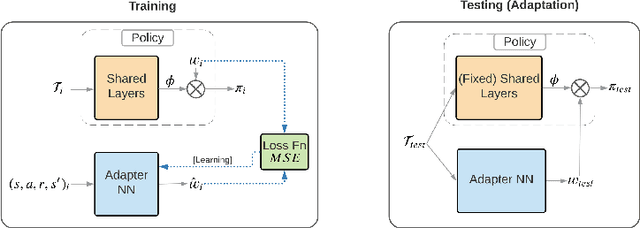
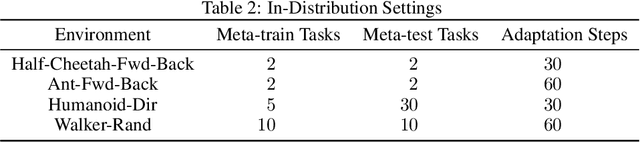
This paper introduces Fast Linearized Adaptive Policy (FLAP), a new meta-reinforcement learning (meta-RL) method that is able to extrapolate well to out-of-distribution tasks without the need to reuse data from training, and adapt almost instantaneously with the need of only a few samples during testing. FLAP builds upon the idea of learning a shared linear representation of the policy so that when adapting to a new task, it suffices to predict a set of linear weights. A separate adapter network is trained simultaneously with the policy such that during adaptation, we can directly use the adapter network to predict these linear weights instead of updating a meta-policy via gradient descent, such as in prior meta-RL methods like MAML, to obtain the new policy. The application of the separate feed-forward network not only speeds up the adaptation run-time significantly, but also generalizes extremely well to very different tasks that prior Meta-RL methods fail to generalize to. Experiments on standard continuous-control meta-RL benchmarks show FLAP presenting significantly stronger performance on out-of-distribution tasks with up to double the average return and up to 8X faster adaptation run-time speeds when compared to prior methods.