 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Focused Sequential Experimental Design: A Directional Uncertainty-Guided Approach
Feb 05, 2026We consider the sequential experimental design problem in the predict-then-optimize paradigm. In this paradigm, the outputs of the prediction model are used as coefficient vectors in a downstream linear optimization problem. Traditional sequential experimental design aims to control the input variables (features) so that the improvement in prediction accuracy from each experimental outcome (label) is maximized. However, in the predict-then-optimize setting, performance is ultimately evaluated based on the decision loss induced by the downstream optimization, rather than by prediction error. This mismatch between prediction accuracy and decision loss renders traditional decision-blind designs inefficient. To address this issue, we propose a directional-based metric to quantify predictive uncertainty. This metric does not require solving an optimization oracle and is therefore computationally tractable. We show that the resulting sequential design criterion enjoys strong consistency and convergence guarantees. Under a broad class of distributions, we demonstrate that our directional uncertainty-based design attains an earlier stopping time than decision-blind designs. This advantage is further supported by real-world experiments on an LLM job allocation problem.
ORPR: An OR-Guided Pretrain-then-Reinforce Learning Model for Inventory Management
Dec 22, 2025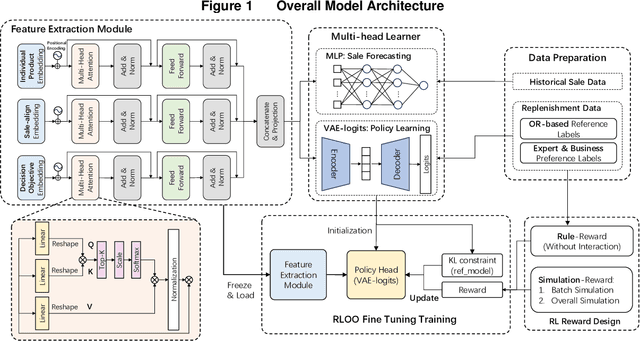
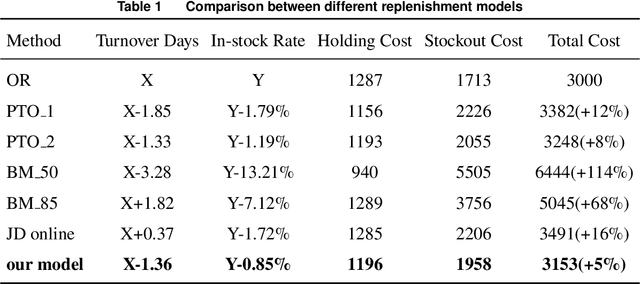
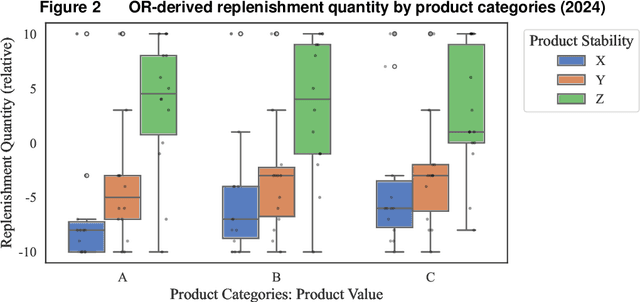
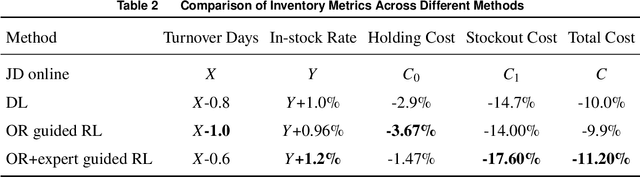
As the pursuit of synergy between Artificial Intelligence (AI) and Operations Research (OR) gains momentum in handling complex inventory systems, a critical challenge persists: how to effectively reconcile AI's adaptive perception with OR's structural rigor. To bridge this gap, we propose a novel OR-Guided "Pretrain-then-Reinforce" framework. To provide structured guidance, we propose a simulation-augmented OR model that generates high-quality reference decisions, implicitly capturing complex business constraints and managerial preferences. Leveraging these OR-derived decisions as foundational training labels, we design a domain-informed deep learning foundation model to establish foundational decision-making capabilities, followed by a reinforcement learning (RL) fine-tuning stage. Uniquely, we position RL as a deep alignment mechanism that enables the AI agent to internalize the optimality principles of OR, while simultaneously leveraging exploration for general policy refinement and allowing expert guidance for scenario-specific adaptation (e.g., promotional events). Validated through extensive numerical experiments and a field deployment at JD.com augmented by a Difference-in-Differences (DiD) analysis, our model significantly outperforms incumbent industrial practices, delivering real-world gains of a 5.27-day reduction in turnover and a 2.29% increase in in-stock rates, alongside a 29.95% decrease in holding costs. Contrary to the prevailing trend of brute-force model scaling, our study demonstrates that a lightweight, domain-informed model can deliver state-of-the-art performance and robust transferability when guided by structured OR logic. This approach offers a scalable and cost-effective paradigm for intelligent supply chain management, highlighting the value of deeply aligning AI with OR.
Leveraging LLM-Based Agents for Intelligent Supply Chain Planning
Sep 04, 2025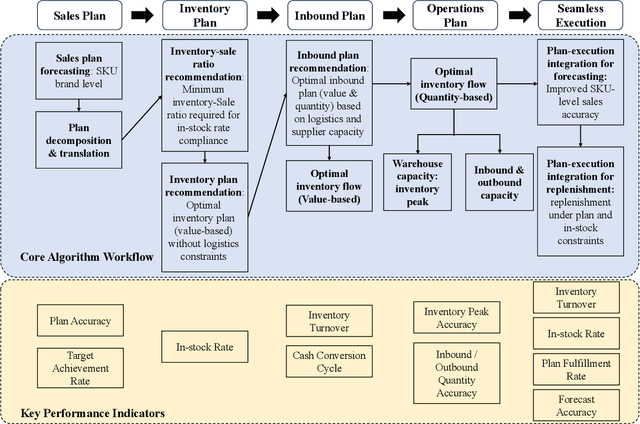
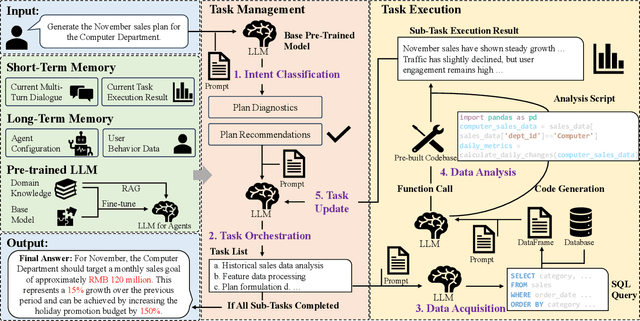
In supply chain management, planning is a critical concept. The movement of physical products across different categories, from suppliers to warehouse management, to sales, and logistics transporting them to customers, entails the involvement of many entities. It covers various aspects such as demand forecasting, inventory management, sales operations, and replenishment. How to collect relevant data from an e-commerce platform's perspective, formulate long-term plans, and dynamically adjust them based on environmental changes, while ensuring interpretability, efficiency, and reliability, is a practical and challenging problem. In recent years, the development of AI technologies, especially the rapid progress of large language models, has provided new tools to address real-world issues. In this work, we construct a Supply Chain Planning Agent (SCPA) framework that can understand domain knowledge, comprehend the operator's needs, decompose tasks, leverage or create new tools, and return evidence-based planning reports. We deploy this framework in JD.com's real-world scenario, demonstrating the feasibility of LLM-agent applications in the supply chain. It effectively reduced labor and improved accuracy, stock availability, and other key metrics.
Learning While Repositioning in On-Demand Vehicle Sharing Networks
Jan 31, 2025We consider a network inventory problem motivated by one-way, on-demand vehicle sharing services. Due to uncertainties in both demand and returns, as well as a fixed number of rental units across an $n$-location network, the service provider must periodically reposition vehicles to match supply with demand spatially while minimizing costs. The optimal repositioning policy under a general $n$-location network is intractable without knowing the optimal value function. We introduce the best base-stock repositioning policy as a generalization of the classical inventory control policy to $n$ dimensions, and establish its asymptotic optimality in two distinct limiting regimes under general network structures. We present reformulations to efficiently compute this best base-stock policy in an offline setting with pre-collected data. In the online setting, we show that a natural Lipschitz-bandit approach achieves a regret guarantee of $\widetilde{O}(T^{\frac{n}{n+1}})$, which suffers from the exponential dependence on $n$. We illustrate the challenges of learning with censored data in networked systems through a regret lower bound analysis and by demonstrating the suboptimality of alternative algorithmic approaches. Motivated by these challenges, we propose an Online Gradient Repositioning algorithm that relies solely on censored demand. Under a mild cost-structure assumption, we prove that it attains an optimal regret of $O(n^{2.5} \sqrt{T})$, which matches the regret lower bound in $T$ and achieves only polynomial dependence on $n$. The key algorithmic innovation involves proposing surrogate costs to disentangle intertemporal dependencies and leveraging dual solutions to find the gradient of policy change. Numerical experiments demonstrate the effectiveness of our proposed methods.
TimeHF: Billion-Scale Time Series Models Guided by Human Feedback
Jan 27, 2025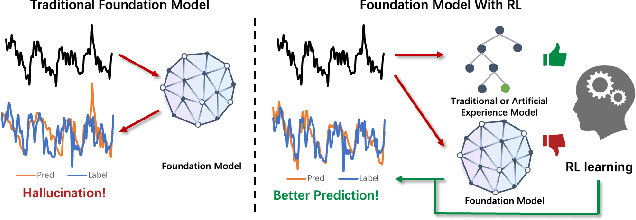
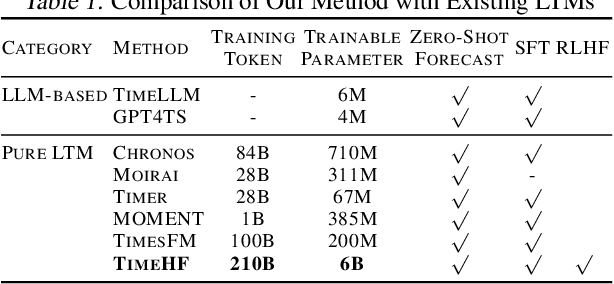

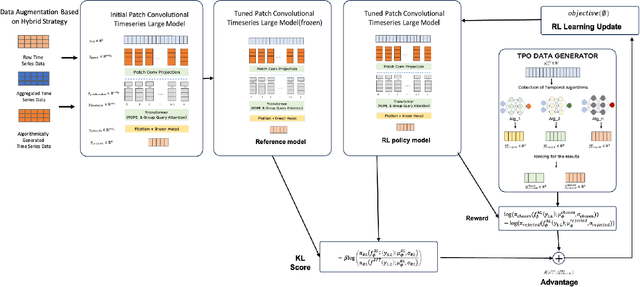
Time series neural networks perform exceptionally well in real-world applications but encounter challenges such as limited scalability, poor generalization, and suboptimal zero-shot performance. Inspired by large language models, there is interest in developing large time series models (LTM) to address these issues. However, current methods struggle with training complexity, adapting human feedback, and achieving high predictive accuracy. We introduce TimeHF, a novel pipeline for creating LTMs with 6 billion parameters, incorporating human feedback. We use patch convolutional embedding to capture long time series information and design a human feedback mechanism called time-series policy optimization. Deployed in JD.com's supply chain, TimeHF handles automated replenishment for over 20,000 products, improving prediction accuracy by 33.21% over existing methods. This work advances LTM technology and shows significant industrial benefits.
Online MDP with Transition Prototypes: A Robust Adaptive Approach
Dec 19, 2024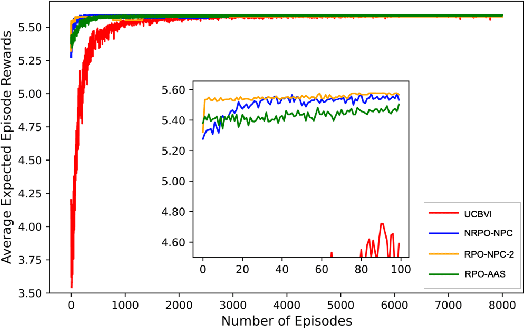
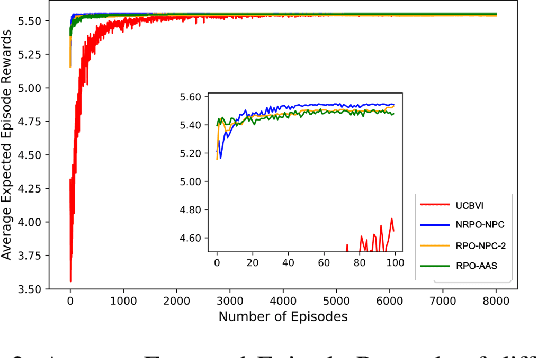
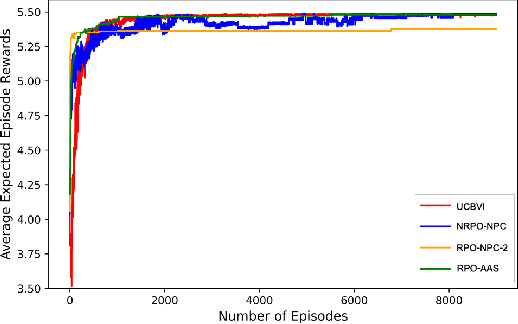
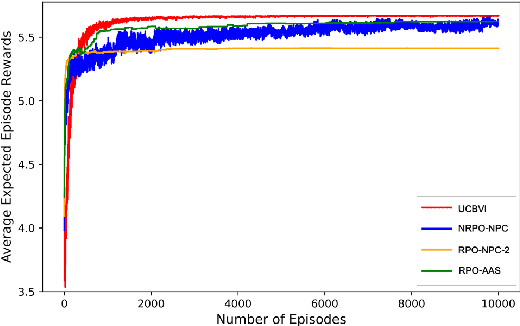
In this work, we consider an online robust Markov Decision Process (MDP) where we have the information of finitely many prototypes of the underlying transition kernel. We consider an adaptively updated ambiguity set of the prototypes and propose an algorithm that efficiently identifies the true underlying transition kernel while guaranteeing the performance of the corresponding robust policy. To be more specific, we provide a sublinear regret of the subsequent optimal robust policy. We also provide an early stopping mechanism and a worst-case performance bound of the value function. In numerical experiments, we demonstrate that our method outperforms existing approaches, particularly in the early stage with limited data. This work contributes to robust MDPs by considering possible prior information about the underlying transition probability and online learning, offering both theoretical insights and practical algorithms for improved decision-making under uncertainty.
Using Drone Swarm to Stop Wildfire: A Predict-then-optimize Approach
Nov 25, 2024



Drone swarms coupled with data intelligence can be the future of wildfire fighting. However, drone swarm firefighting faces enormous challenges, such as the highly complex environmental conditions in wildfire scenes, the highly dynamic nature of wildfire spread, and the significant computational complexity of drone swarm operations. We develop a predict-then-optimize approach to address these challenges to enable effective drone swarm firefighting. First, we construct wildfire spread prediction convex neural network (Convex-NN) models based on real wildfire data. Then, we propose a mixed-integer programming (MIP) model coupled with dynamic programming (DP) to enable efficient drone swarm task planning. We further use chance-constrained robust optimization (CCRO) to ensure robust firefighting performances under varying situations. The formulated model is solved efficiently using Benders Decomposition and Branch-and-Cut algorithms. After 75 simulated wildfire environments training, the MIP+CCRO approach shows the best performance among several testing sets, reducing movements by 37.3\% compared to the plain MIP. It also significantly outperformed the GA baseline, which often failed to fully extinguish the fire. Eventually, we will conduct real-world fire spread and quenching experiments in the next stage for further validation.
Daily Physical Activity Monitoring -- Adaptive Learning from Multi-source Motion Sensor Data
May 26, 2024



In healthcare applications, there is a growing need to develop machine learning models that use data from a single source, such as that from a wrist wearable device, to monitor physical activities, assess health risks, and provide immediate health recommendations or interventions. However, the limitation of using single-source data often compromises the model's accuracy, as it fails to capture the full scope of human activities. While a more comprehensive dataset can be gathered in a lab setting using multiple sensors attached to various body parts, this approach is not practical for everyday use due to the impracticality of wearing multiple sensors. To address this challenge, we introduce a transfer learning framework that optimizes machine learning models for everyday applications by leveraging multi-source data collected in a laboratory setting. We introduce a novel metric to leverage the inherent relationship between these multiple data sources, as they are all paired to capture aspects of the same physical activity. Through numerical experiments, our framework outperforms existing methods in classification accuracy and robustness to noise, offering a promising avenue for the enhancement of daily activity monitoring.
Potential Energy Advantage of Quantum Economy
Aug 15, 2023


Energy cost is increasingly crucial in the modern computing industry with the wide deployment of large-scale machine learning models and language models. For the firms that provide computing services, low energy consumption is important both from the perspective of their own market growth and the government's regulations. In this paper, we study the energy benefits of quantum computing vis-a-vis classical computing. Deviating from the conventional notion of quantum advantage based solely on computational complexity, we redefine advantage in an energy efficiency context. Through a Cournot competition model constrained by energy usage, we demonstrate quantum computing firms can outperform classical counterparts in both profitability and energy efficiency at Nash equilibrium. Therefore quantum computing may represent a more sustainable pathway for the computing industry. Moreover, we discover that the energy benefits of quantum computing economies are contingent on large-scale computation. Based on real physical parameters, we further illustrate the scale of operation necessary for realizing this energy efficiency advantage.
Estimating and Incentivizing Imperfect-Knowledge Agents with Hidden Rewards
Aug 13, 2023



In practice, incentive providers (i.e., principals) often cannot observe the reward realizations of incentivized agents, which is in contrast to many principal-agent models that have been previously studied. This information asymmetry challenges the principal to consistently estimate the agent's unknown rewards by solely watching the agent's decisions, which becomes even more challenging when the agent has to learn its own rewards. This complex setting is observed in various real-life scenarios ranging from renewable energy storage contracts to personalized healthcare incentives. Hence, it offers not only interesting theoretical questions but also wide practical relevance. This paper explores a repeated adverse selection game between a self-interested learning agent and a learning principal. The agent tackles a multi-armed bandit (MAB) problem to maximize their expected reward plus incentive. On top of the agent's learning, the principal trains a parallel algorithm and faces a trade-off between consistently estimating the agent's unknown rewards and maximizing their own utility by offering adaptive incentives to lead the agent. For a non-parametric model, we introduce an estimator whose only input is the history of principal's incentives and agent's choices. We unite this estimator with a proposed data-driven incentive policy within a MAB framework. Without restricting the type of the agent's algorithm, we prove finite-sample consistency of the estimator and a rigorous regret bound for the principal by considering the sequential externality imposed by the agent. Lastly, our theoretical results are reinforced by simulations justifying applicability of our framework to green energy aggregator contracts.