 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Planning Considering Time-Varying and Uncertain Movement Speed in Multi-Robot Automatic Warehouses: Problem Formulation and Algorithm
Dec 01, 2022



Path planning in the multi-robot system refers to calculating a set of actions for each robot, which will move each robot to its goal without conflicting with other robots. Lately, the research topic has received significant attention for its extensive applications, such as airport ground, drone swarms, and automatic warehouses. Despite these available research results, most of the existing investigations are concerned with the cases of robots with a fixed movement speed without considering uncertainty. Therefore, in this work, we study the problem of path-planning in the multi-robot automatic warehouse context, which considers the time-varying and uncertain robots' movement speed. Specifically, the path-planning module searches a path with as few conflicts as possible for a single agent by calculating traffic cost based on customarily distributed conflict probability and combining it with the classic A* algorithm. However, this probability-based method cannot eliminate all conflicts, and speed's uncertainty will constantly cause new conflicts. As a supplement, we propose the other two modules. The conflict detection and re-planning module chooses objects requiring re-planning paths from the agents involved in different types of conflicts periodically by our designed rules. Also, at each step, the scheduling module fills up the agent's preserved queue and decides who has a higher priority when the same element is assigned to two agents simultaneously. Finally, we compare the proposed algorithm with other algorithms from academia and industry, and the results show that the proposed method is validated as the best performance.
Privacy-Preserving Technology to Help Millions of People: Federated Prediction Model for Stroke Prevention
Jun 15, 2020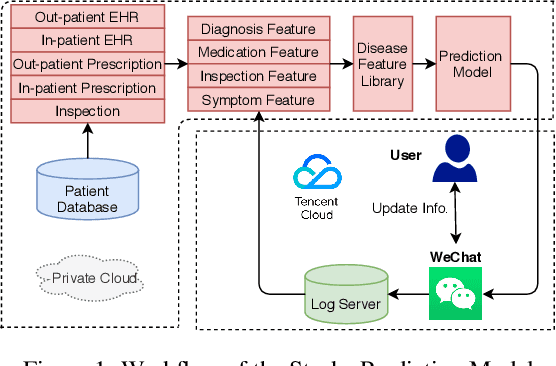
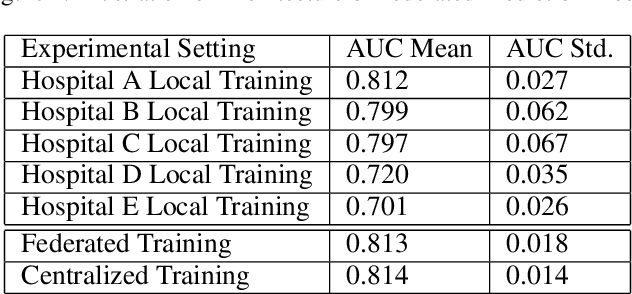
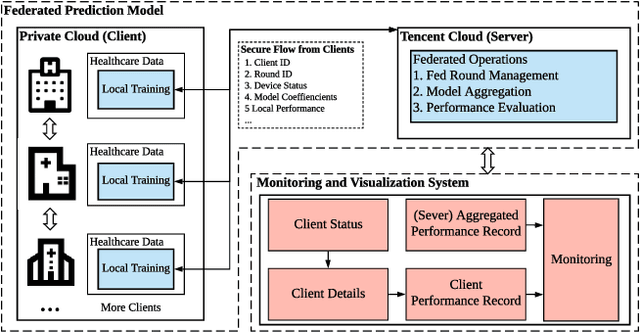
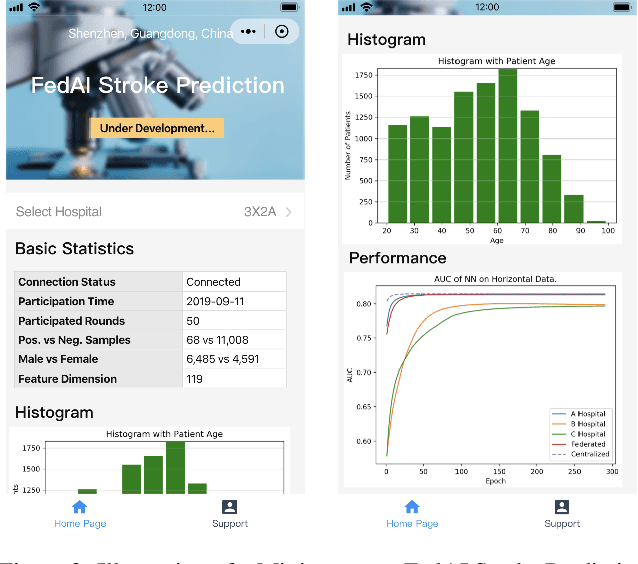
prevention of stroke with its associated risk factors has been one of the public health priorities worldwide. Emerging artificial intelligence technology is being increasingly adopted to predict stroke. Because of privacy concerns, patient data are stored in distributed electronic health record (EHR) databases, voluminous clinical datasets, which prevent patient data from being aggregated and restrains AI technology to boost the accuracy of stroke prediction with centralized training data. In this work, our scientists and engineers propose a privacy-preserving scheme to predict the risk of stroke and deploy our federated prediction model on cloud servers. Our system of federated prediction model asynchronously supports any number of client connections and arbitrary local gradient iterations in each communication round. It adopts federated averaging during the model training process, without patient data being taken out of the hospitals during the whole process of model training and forecasting. With the privacy-preserving mechanism, our federated prediction model trains over all the healthcare data from hospitals in a certain city without actual data sharing among them. Therefore, it is not only secure but also more accurate than any single prediction model that trains over the data only from one single hospital. Especially for small hospitals with few confirmed stroke cases, our federated model boosts model performance by 10%~20% in several machine learning metrics. To help stroke experts comprehend the advantage of our prediction system more intuitively, we developed a mobile app that collects the key information of patients' statistics and demonstrates performance comparisons between the federated prediction model and the single prediction model during the federated training process.
A Survey towards Federated Semi-supervised Learning
Feb 26, 2020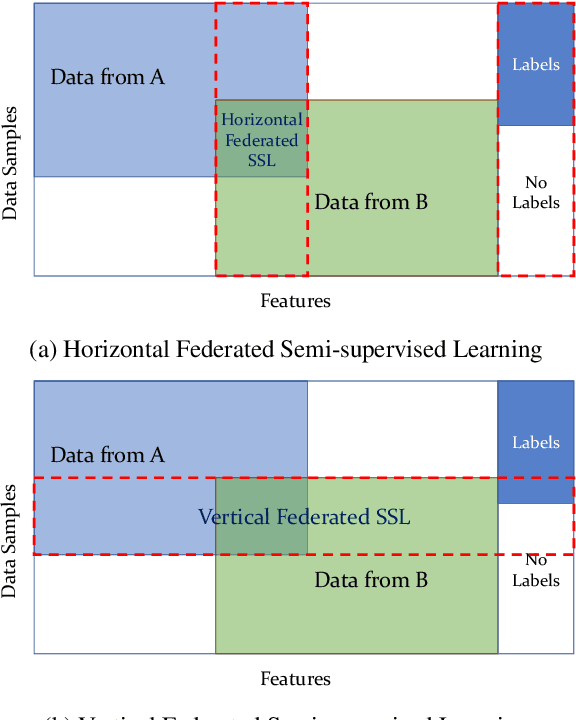
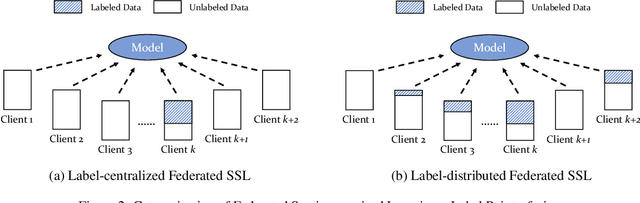
The success of Artificial Intelligence (AI) should be largely attributed to the accessibility of abundant data. However, this is not exactly the case in reality, where it is common for developers in industry to face insufficient, incomplete and isolated data. Consequently, federated learning was proposed to alleviate such challenges by allowing multiple parties to collaboratively build machine learning models without explicitly sharing their data and in the meantime, preserve data privacy. However, existing algorithms of federated learning mainly focus on examples where, either the data do not require explicit labeling, or all data are labeled. Yet in reality, we are often confronted with the case that labeling data itself is costly and there is no sufficient supply of labeled data. While such issues are commonly solved by semi-supervised learning, to the best of knowledge, no existing effort has been put to federated semi-supervised learning. In this survey, we briefly summarize prevalent semi-supervised algorithms and make a brief prospect into federated semi-supervised learning, including possible methodologies, settings and challenges.
HHHFL: Hierarchical Heterogeneous Horizontal Federated Learning for Electroencephalography
Sep 11, 2019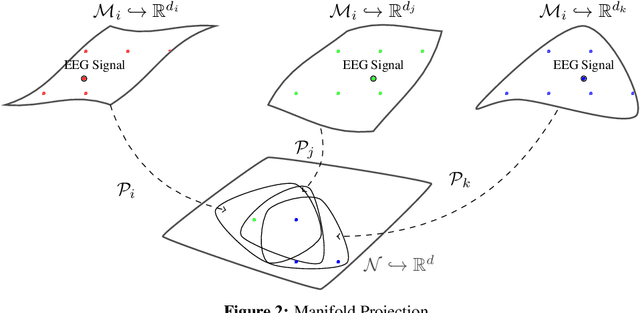
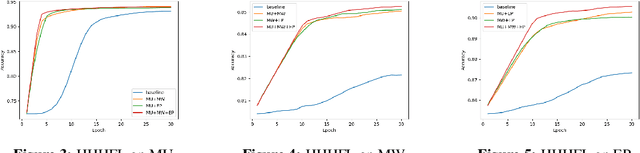
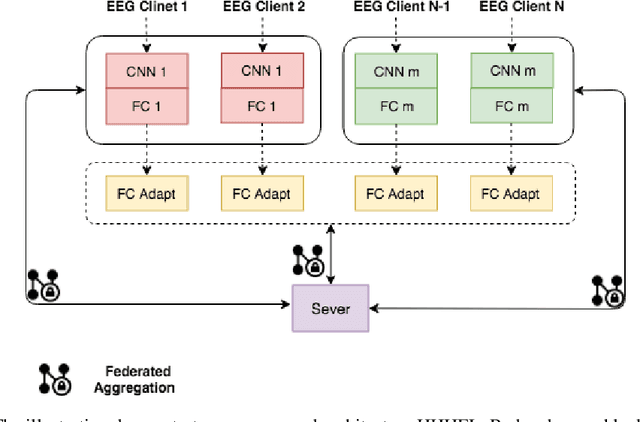
Electroencephalography (EEG) classification techniques have been widely studied for human behavior and emotion recognition tasks. But it is still a challenging issue since the data may vary from subject to subject, may change over time for the same subject, and maybe heterogeneous. Recent years, increasing privacy-preserving demands poses new challenges to this task. The data heterogeneity, as well as the privacy constraint of the EEG data, is not concerned in previous studies. To fill this gap, in this paper, we propose a heterogeneous federated learning approach to train machine learning models over heterogeneous EEG data, while preserving the data privacy of each party. To verify the effectiveness of our approach, we conduct experiments on a real-world EEG dataset, consisting of heterogeneous data collected from diverse devices. Our approach achieves consistent performance improvement on every task.